中文标题:基于因果框架的医疗领域数据分布偏移评估
英文标题:Diagnosing failures of fairness transfer across distribution shift in real-world medical settings
发布平台:NeurIPS
发布日期:2023-02-10
引用量(非实时):
DOI:10.48550/arXiv.2202.01034
作者:Jessica Schrouff, Natalie Harris, Oluwasanmi Koyejo, Ibrahim Alabdulmohsin, Eva Schnider, Krista Opsahl-Ong, Alex Brown, Subhrajit Roy, Diana Mincu, Christina Chen, Awa Dieng, Yuan Liu, Vivek Natarajan, Alan Karthikesalingam, Katherine Heller, Silvia Chiappa, Alexander D'Amour
文章类型:preprint
品读时间:2023-05-09 14:36
1 文章萃取
1.1 核心观点
- 在医疗领域进行机器学习安全部署时,合理诊断和减轻数据分布偏移是保障模型公平性的关键。本文基于因果框架提出了一种通用的分布偏移检验算法,能独立于场景适用于多种类型数据的偏移检验,最终结果包含针对每一项特征的检验p值,并以联合因果图的形式说明分布的结构偏移,可以用于辅助医疗模型的落地。
1.2 综合评价
- 本文提出的算法通用性强,可以通过建模算法的替换升级适用更全面的场景
- 本文在两类数据(皮肤图像和病历文本)进行多中心的算法验证,结论具备较好地说服力
- 整体算法的有效性依赖于联合因果图的构建,可靠性对数据规模有一定要求
- 缺少对算法结果的应用相关试验,仅从理论上提出了一些可行的方案
1.3 主观评分:⭐⭐⭐⭐⭐
2 精读笔记
2.1 背景知识
符号定义:
- $X$是一组特征(协变量),$Y$是要预测的结果或标签
- $A$是一个或多个敏感属性(比如人口统计学属性)
- 一个分类或回归模型$f(X')$
- $X'$根据上下文有两种定义,$X':=(X,A)$或$X':=X$
因果贝叶斯网络(Causal Bayesian network,CBN)是一种有向无环图
- 节点$U$表示各个属性/风险事件,边表示不同属性/风险事件间的因果联系
- 当节点$U^i$指向节点$U^j$时,表示$U^i$是$U^j$的一个直接原因(a direct cause)
- 节点$U^i$的所有直接原因可表示为父因集合(causal parents),用符号$pa(U^i)$表示
联合因果图(joint causal graph)是对CBN的一种拓展
- 为更好地表示数据分布的偏移,引入环境变量$S$来扩展CBN
- $S = 0$表示来自源环境的数据,$S = 1$表示来自目标环境的数据
- 源数据可表示为$P ( A , X , Y | S = 0)$,目标数据可表示为$P ( A , X , Y | S = 1)$
- 当变量$X$存在环境导致的分布偏移时,可用$S\rightarrow X$表示
- 环境导致的分布偏移可能是复合的,即作用在多个变量中:$S\rightarrow {A,X,Y}$
联合因果图示例:
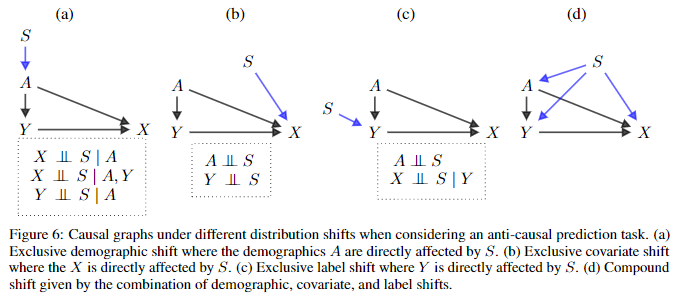
- 上图中假设目标Y是协变量X的直接原因,而敏感特征A是X和Y的直接原因
- 这种情况也被称为反因果推断(Anti-causal prediction)
- 当协变量X是目标Y的直接原因时,被称为因果推断(Causal prediction)
联合因果推理(Joint Causal Inference,JCI)框架:
- 一种在不同情况下对系统因果进行建模的框架
- 该框架兼容多种因果发现算法,并允许潜在的数据杂质
- JCI不需要了解干预目标或类型,可以统一地处理不同干预措施
- 关于JCI框架的更多细节可参阅原论文
2.2 算法细节
数据分布变化会严重影响ML模型的行为,这种影响也会表现在模型的公平性上。比如在医疗领域,模型在医院A的训练满足公平性标准,但是在使用医院B的数据进行测试时,会发现可能不满足公平性标准。
有很多研究数据分布偏移、模型鲁棒性、公平性,但很少有方法能够诊断转变的本质并指导制定适当的缓解策略。而本文设计了一种满足JCI框架的统计测试方法,可以基于应用和目标数据集的简化联合因果图,评估系统遇到的分布偏移的结构,识别阻碍数据公平性的属性转移。具体算法对应伪代码如下:

- 该算法针对图中每个节点$U$(对应每一种$A,X,Y$)进行单独的环境偏移评估
- $S = 0$表示源环境,对应数据为$D$;$S = 1$表示目标环境,对应数据为$D'$
- 每个节点的环境偏移都是通过假设检验对应$p$值来描述的。原假设为$H_0:P(U|pa(U),S=0)=P(U|pa(U),S=1)$,拒绝此原检验则意味着联合因果图中存在$S\rightarrow U$,即节点$U$存在分布偏移的情况
原假设$H_0$的转换:
- 考虑用变量$M$来表示$pa(U)$,$M$的概率密度函数可定义为$\pi(M)$:
$$H_0:P(U|M,S=0)=P(U|M,S=1)$$
- 原假设$H_0$对于任意的$pa(U)$都应该是成立的:
$$H_0:\int E[U|M|S=0]\pi(M)dM=\int E[U|M|S=1]\pi(M)dM$$
- 上式经过化简后,可转化为以下形式(过程略):
$$H_0: E[\frac{\pi(M)}{P(M|S=0)}U|S=0]= E[\frac{\pi(M)}{P(M|S=1)}U|S=1]$$
- 假设$M$满足均匀分布(不同集合的出现概率是相等的),可定义$w_0(M)$和$w_1(M)$如下:
$$\begin{equation} \left\{ \begin{gathered} w_0(M)=\frac{\pi(M)}{P(M|S=0)}\propto P(M|S=0)^{-1} \ \\ w_1(M)=\frac{\pi(M)}{P(M|S=1)}\propto P(M|S=1)^{-1} \end{gathered} \right. \end{equation}$$
- 将$w_0(M)$和$w_1(M)$带入$H_0$后便得到了原假设的最终形式:
$$H_0: E[w_0U|S=0]- E[w_1U|S=1]=0$$
上式的原假设,可解释为$U$的重加权(权重为$w$)分布在不同环境$S$下是否保持一致
用于度量差异性的$p$值的计算过程理解:
- 两种环境下的数据都会划分为训练集$D_w$和测试集$D_t$
- 对训练集进行抽样后得到不同环境下的训练子集$Q$和$Q'$,构建分类器
- 在测试子集$V$上计算分类器的预测输出$P(S|M)$,进而得到$w_0$和$w_1$
- 最后根据$H_0:E[w_0U|S=0]- E[w_1U|S=1]=0$,得到$t$检验值
- 重复以上$bootstrap$过程$n$次,得到更稳健的假设检验$p$值
当特征的维度较高时,可用考虑仅针对特征的低维表示(摘要,summary)进行测试。使用这种方法时,需要保证摘要数据的条件分布与原始数据的条件分布的一致性
算法的有效性验证(三种实验):
- 使用相同的数据进行随机拆分并进行算法测试,最终预测准确率在50%上下浮动,假阳性率约为5%,接近假设检验阈值;但需要注意结果的方差随数据量的减少而增加(说明此算法在少样本情况下不稳定)
- 针对皮肤数据中特定皮肤状况的年轻患者进行下采样,人为构建特征的分布偏移,算法识别成功
- 对Y进行统一的平移,人为构建标签的分布偏移,算法识别成功
2.3 实验分析
公平性的统计定义:子群准确性差距、人口奇偶性和均等优势
实验阶段主要展示了两个案例研究:皮肤科和电子健康记录( Electronic Health Records,EHR )
皮肤科数据包含患者人口统计学信息A、病种Y以及1~6张皮肤照片X,源数据使用来自美国2个州的12024+1925+1924(训练、验证、测试)例患者,目标数据使用来自哥伦比亚和澳大利亚的病例数据。
皮肤病数据的对比实验结果如下:
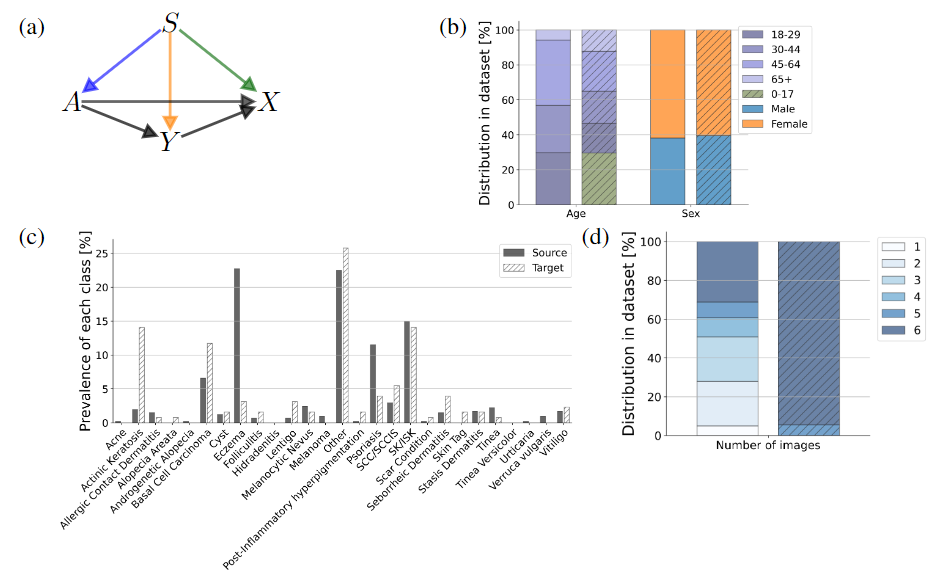
- 图(a)显示算法针对皮肤科数据构建的简化联合因果图
- 图(b)显示,源数据对应人群的年龄分布存在显著差异,表明S与A存在直接关系
- 图(c)显示,源数据中大于65岁的老年女性患者包括更多的“湿疹”和“牛皮癣”病例,即排除年龄性别的因素影响下,病种分布依然存在显著差异,表明S与Y存在直接关系
- 图(d)显示,类别为‘sk/isk’的老年女性在图像数据存在显著差异,表明S与X存在直接关系
EHR则主要使用开源的MIMIC-Ⅲ数据集,本文将医学ICU(MICU),手术ICU(SICU)和创伤手术ICU(TSICU)视为源数据(通用ICU);心脏手术恢复单元(CSRU)和冠状动脉护理单位(CCU)视为目标数据(专科ICU)。预测目标是“入住ICU时长是否大于3天”
EHR数据的对比实验结果如下:
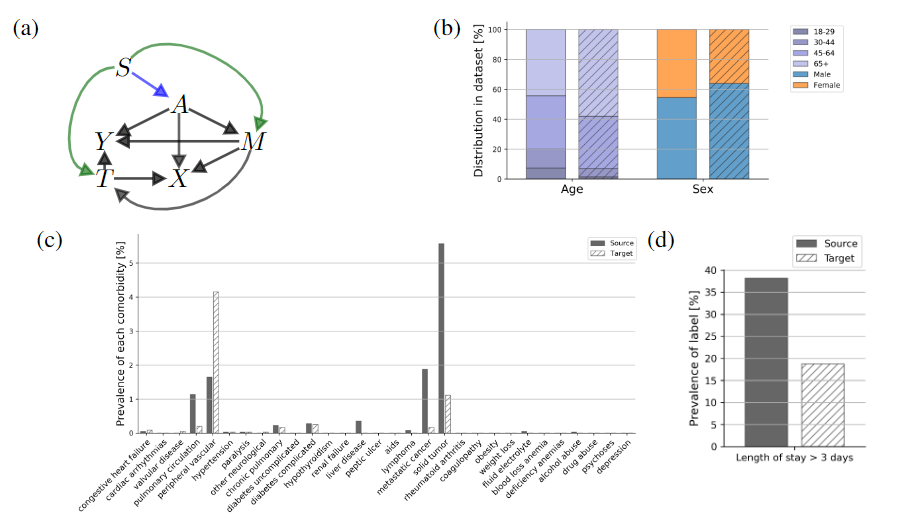
- 图(a)显示算法针对EHR数据构建的简化联合因果图,其中A表示年龄/性别、M表示病史、X表示检验/体征信息、T表示治疗手段,Y表示入住ICU时长
- 图(b)显示,源数据对应人群的年龄、性别分布均存在显著差异,表明S与A存在直接关系
- 图(c)显示,目标数据中大于65岁的老年男性患者的外周血管系统相关的合并症患病率更高,即排除年龄性别的因素影响下,合并症依然存在显著差异,表明S与M存在直接关系
- 图(d)显示,接收加压剂/肌肉(特定治疗手段)下患有实体肿瘤合并症(特定合并症)的老年男性在ICU入住时长存在显著差异,表明S与Y存在直接关系
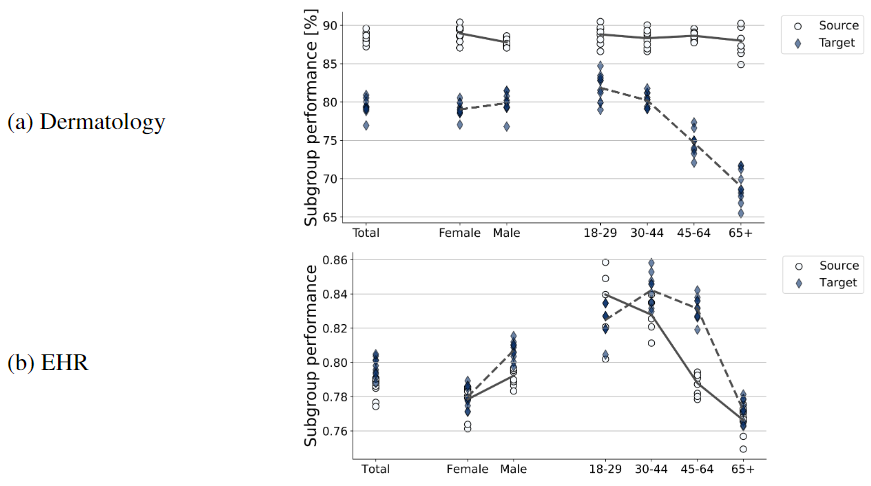
两个案例中不同亚组(年龄和性别)的模型迁移前后性能表现:
其他建模细节:
- 实际训练时主要使用逻辑回归或GPT类算法,对于每种测试重复训练100次
- 对于高维数据需要进行低维表示,包括皮肤病相关图像数据(28TPU,24h~30h)和EHR文本数据(2CPU,1h),以上过程也会重复10次以增加结果的公平性
- 皮肤病相关图像数据(448x448)借助宽ResNet101x3特征抽取器进行编码,对应模型架构如下:
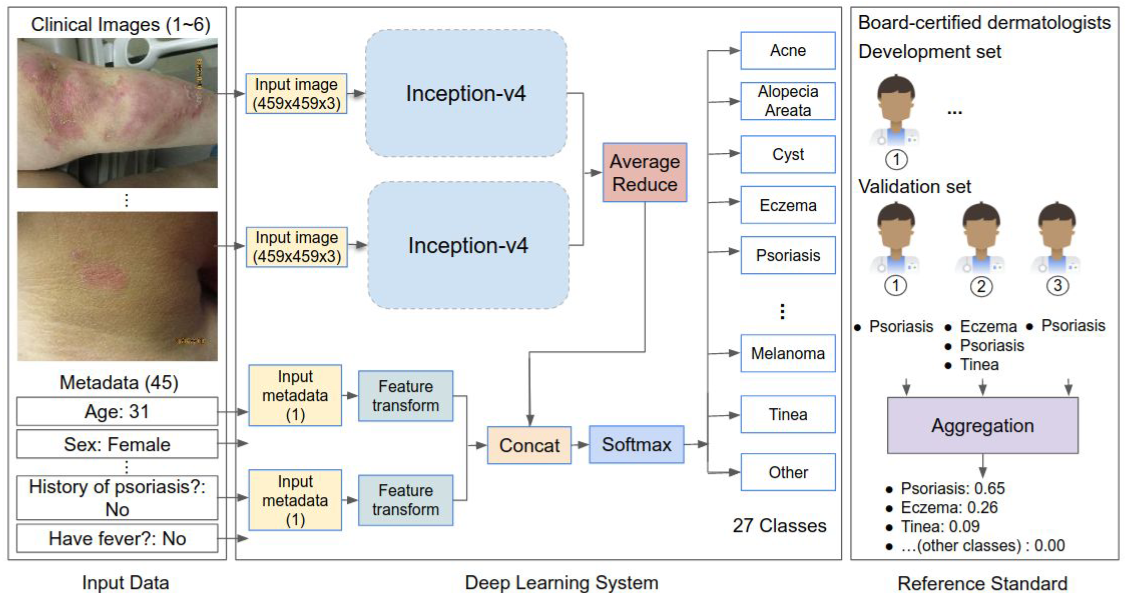
(摘自论文 A deep learning system for differential diagnosis of skin diseases) - GBT类算法可能对某一类子集过度重视而导致算法出错(由于忽视了某一子类,而导致分布偏移没有正确识别)。因此需要对类权重进行裁剪(比如限制最大值为10)来缓解此问题
- 相关建模代码主要参考自谷歌之前开源的一套EHR预测建模框架 #待补充
改进数据分布偏移的5种可行方案:
- 问题选择:专注于临床/政策保障型或预期危害较低的任务,减少ML不公平导致的影响
- 数据搜集:针对可能存在分布偏移的场景,尽量在早期完成数据搜集,方便算法测试与调整
- 输出定义:考虑对数据分布偏移不敏感的中间结果,比如图像分割任务VS诊断任务
- 算法改进:手工设计的特征工程可能有助于对特定偏见的归纳,降低部署的风险
- 后处理:针对特定场景进行迁移学习或重新训练,部署后保持对模型公平性的监控
其他分析总结:
- 使用Alabdulmohsin等人提出的方法进行预测输出后处理后,模型迁移前后的性能表现差异显著缩小,但经过本文算法进行检验测试后,发现数据的公平性并没有得到有效缓解
- 本文提出的算法考虑了因果结构和全部的直接影响因素,能有效指导缓解策略的选择
- 本文工作并没有评估不同模型架构和训练策略的影响,也没有考虑社会因素等无法观察到的变量影响
- 未来的工作可以拓展到更多类型的变量,要重视对偏见来源的探究
- 医疗领域的公平性是值得探索的方向,但在应用前一定要注意严格的验证
通过在皮肤科和电子健康记录( Electronic Health Records,EHR )中的试验分析可知,算法结果对于选择适当的缓解策略至关重要。此外,我们的工作还表明,临床上可能发生的变化往往比目前的缓解技术所能处理的更复杂,这突出表明需要进一步研究整个ML处理流程中更广泛的补救措施