中文标题:ShorT:用于医疗AI公平的捷径学习检测和预防
英文标题:Detecting and Preventing Shortcut Learning for Fair Medical AI using Shortcut Testing (ShorT)
发布平台:无
预印本
发布日期:2022-07-21
引用量(非实时):
DOI:10.48550/arXiv.2207.10384
作者:Alexander Brown, Nenad Tomasev, Jan Freyberg, Yuan Liu, Alan Karthikesalingam, Jessica Schrouff
文章类型:preprint
品读时间:2023-05-16 15:05
1 文章萃取
1.1 核心观点
- 本文在多任务学习的基础上,通过改变梯度更新调整模型对敏感属性的编码程度,并评估其对模型公平性的影响,借助二者的负相关性来识别和量化捷径学习。之后本文提出并论证了抽样法和反向梯度更新这两种缓解策略对模型公平性和预测性能的影响,并通过放射学和皮肤科的临床实验说明了便捷学习的评估算法(ShorT)和缓解策略的有效性
1.2 综合评价
- 通过多任务学习+调整梯度更新的方式操纵模型对信息的编码程度
- 找到了一种识别捷径学习的合理框架,并在实际数据中进行了验证
- 实证分析阶段使用了抽样的有偏数据,掩盖了算法在真实数据的表现
- 评估公平性和编码能力的方法可以根据业务进行调整,算法进化空间大
1.3 主观评分:⭐⭐⭐⭐⭐
2 精读笔记
2.1 捷径学习的背景
机器学习的公平性核心:理解不同子群间的分布及其潜在的机制
公平的定义:由敏感属性分组后的患者子群间表现出相近的模型性能表现
"捷径学习(shortcut learning)":指ML模型依靠训练数据集中的虚假关联来学习预测规则,这些预测规则在面对新场景或新数据时通常泛化能力较差
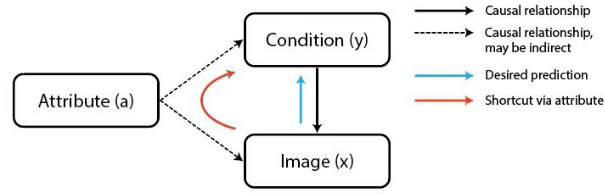
- 上图中,蓝色表示期望的正常学习,根据图像x预测病种y
- 上图中,红色表示捷径学习,模型使用敏感属性a来预测病种y
- 在皮肤病诊断任务中,预测错误的样本体现出与年龄的虚假关联性
- 模型对这类敏感属性的错误跟踪,导致医疗领域中不公平危害的延续
当敏感属性与任务有因果关系时,识别捷径学习将变得更加困难
- 雄激素性脱发在男性中更常见,乳腺癌在女性中更常见
- 瘢痕疙瘩多见于深色皮肤,黑色素瘤多见于浅色皮肤
- 这种情况下,忽略或减弱某些细节信息可能会降低临床疗效
- 因此当敏感属性与任务有因果关系时,需要一种更合理的改进方式
2.2 捷径学习的识别
模型中蕴含着对敏感属性的编码,可用于便捷学习的识别
- 对于基于图像的建模来说,模型可以根据图像信息预测出敏感属性(如年龄)
- 因此即使不显式地输入敏感属性,模型也可能包含与敏感属性相关的信息
- 而当训练模型用于性别或年龄的预测时,模型可能产生关于敏感属性的编码
- 通过干预模型对敏感属性编码的程度,可以评估模型是否存在捷径学习的问题
评估是否存在捷径学习的三要素:
- 敏感属性编码:冻结临床预测模型的主干权重后,”迁移“模型用于敏感属性(如年龄)的预测,根据结果的平均绝对误差(MAE)来评估编码程度,误差越小,说明敏感属性编码越全面
- 公平性度量:使用年龄作为自变量,分组拟合”临床预测模型的精度“;用多组回归系数的绝对值平均(分离度)评估临床预测模型的公平性,绝对值平均越接近0,模型的公平性越高
- 捷径学习测试(ShorT):计算敏感属性编码与公平性度量之间的相关性(Spearman相关系数)
ShorT算法核心假设:如果模型存在捷径学习,则干预其对敏感属性的编码将影响公平性指标
具体来说,本文使用胸部 X 光(NIH Chest X Ray,CXR)数据集进行实验分析。不同学习任务使用同一套深度学习架构的"特征提取器",并根据任务的不同配置相应的预测头。
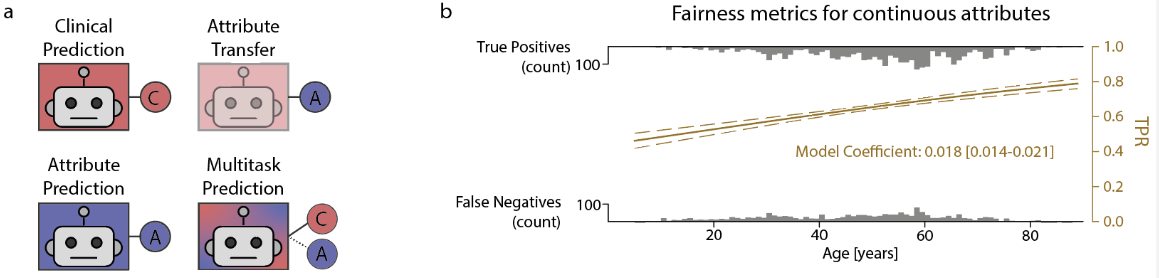
- 上图中(a)包含了四种学习任务,”方框“表示特征提取器主干,”圆圈“表示预测头
- 临床预测(左上)和敏感属性/年龄预测(左下)任务仅使用单个头
- 迁移任务(右上)使用临床预测的预训练模型,冻结特征提取器后使用单个头
- 多任务预测(右下)模型使用两个头,其中年龄预测头用于调控模型对年龄的编码程度
- 上图中(b)使用逻辑回归(LR)拟合进行公平性度量的计算
- 灰色分布表示不同年龄(x轴)中真阳性样本(上)和假阴性样本(下)的计数
- 逻辑回归模型以年龄为输入,拟合临床预测结果的真阳率(TPR,右y轴)
- 另一组逻辑回归模型也是以年龄为输入,拟合假阴率(FPR,未在图中显示)
- 对两组回归系数的绝对值取平均,得到度量模型公平性的分离度
其他实验细节:
- 年龄预测模型提供了一个经验误差下限(LEB),测试集患者的平均年龄(可看作一个基准模型)提供了一个实证误差上限,最终临床预测模型的”迁移“精度应该在二者之间
- 多任务预测模型通过控制年龄预测任务时的梯度更新来调整模型对年龄的编码程度,放大梯度更新鼓励模型对年龄信息的编码,而反向(负值)的梯度更新则削弱编码,最终可以衡量不同年龄编码程度对结果的影响
- 用预测年龄的平均绝对误差(MAE)量化编码程度,用分离度评估临床预测模型的公平性;当MAE越低而分离度越高时(存在负相关),说明对年龄的编码增强会降低模型的公平性,即存在捷径学习
- 临床预测模型”迁移“时,会冻结特征提取器主干(ResNet 101x3架构),然后使用倒数第二层作为模型编码,后接一个简单的线性预测器进行年龄的训练和预测
- 本次实验设置了重复的模型训练来评估结果的变异性,相关超参数详见原文附录
2.3 实验结果与总结
CXR实验结果:
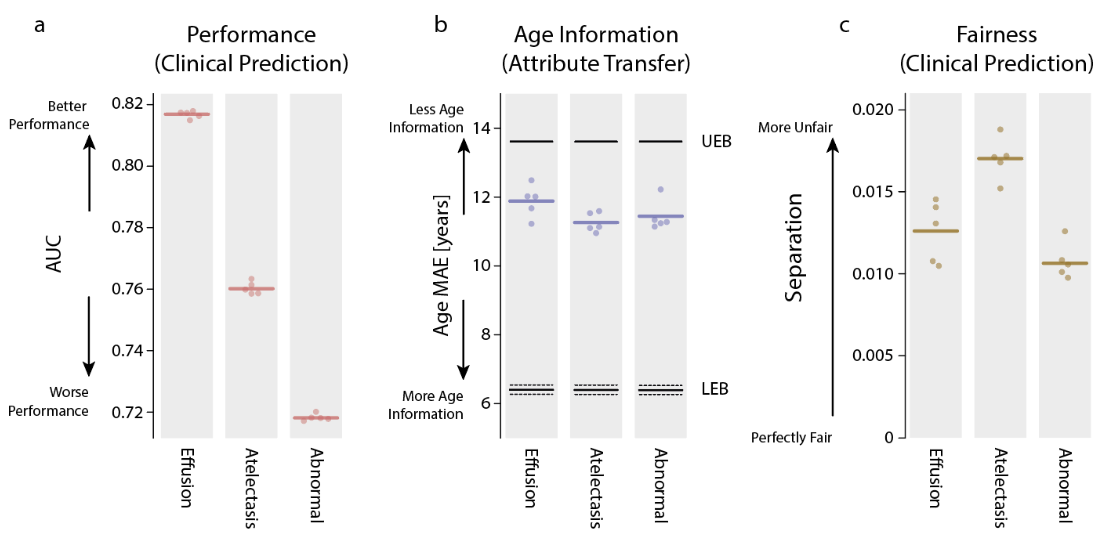
- 图(a)表示临床预测模型的性能表现-ROC值;CXR实验的预测是多个二分类标签,主要包括“积液(effusion)”,“肺不张(atelectasis)”和“其他异常(abnormal)”这三种类型。
- 图(b)表示临床预测模型的“迁移”任务表现,三个模型均存在对年龄的编码(MAE都低于UEB)
- 图(c)表示临床预测模型的公平性度量,三个模型均存在一定程度的不公平问题(分离度大于0)
公平性度量“分离度”-关注不同子组的错误率差异,并且不希望假定临床任务与年龄无关
- 假设分离度为$s$,年龄差异为$\Delta a$,则年龄对模型性能的影响可用$e^{S\Delta a}$表示
- $s=0.01$意味着当年龄相关10年时,模型性能表现会有10.5%波动
- $s=0.02$意味着当年龄相关10年时,模型性能表现会有22.1%波动
对“积液(effusion)”分类问题的深入分析:
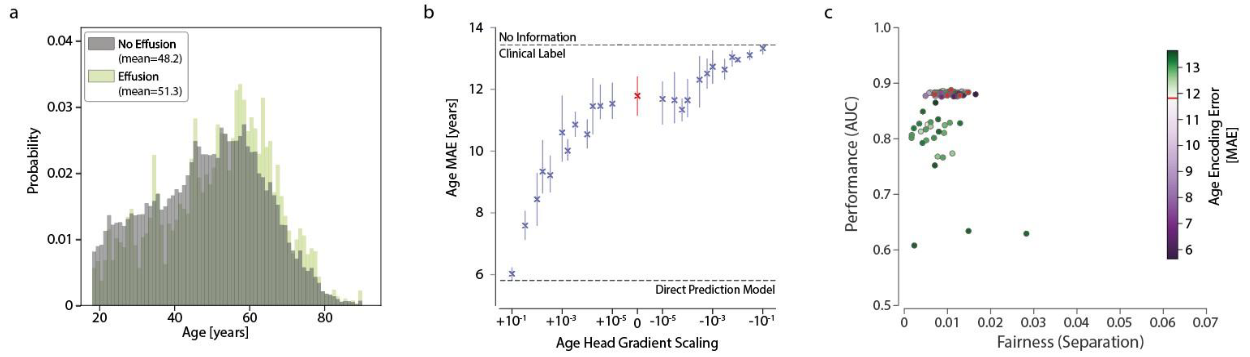
- 图(a)描述了正(浅绿色)样本和负(灰色)样本的年龄分布,明显正样本中患者年龄普遍更大
- 图(b)描述了在多任务预测模型中缩放/反转梯度更新对年龄编码的影响(由随后的“迁移”任务确定),反向(负值)梯度更新会导致MAE逐渐逼近实证误差上限(UEB)
- 图(b)中红色点表示基准模型,即仅进行临床预测训练,而不进行年龄预测训练
- 图(c)同时描述了模型的性能表现(AUC)、公平性(分离度)和年龄编码程度(MAE);年龄编码程度高于基准模型(红色)的模型(紫色)性能表现似乎不存在显著差异;削弱模型对年龄的编码能力(绿色)略微改善了公正性特性,但代价是降低了整体模型性能
- 同样的结果也适用于“肺不张(atelectasis)”和“其他异常(abnormal)”两类问题
为了更好地评估 ShorT 检测捷径学习的能力,本文通过抽样构建了两份数据集:
- 一个有偏数据集,正类和负类间存在约11.2年的年龄差
- 一个平衡数据集,两个类别的年龄分布大致匹配
- 预计有偏数据集会存在的捷径学习,而平衡数据集则不会产生捷径学习
最终在这两份数据集上的深入分析如下:
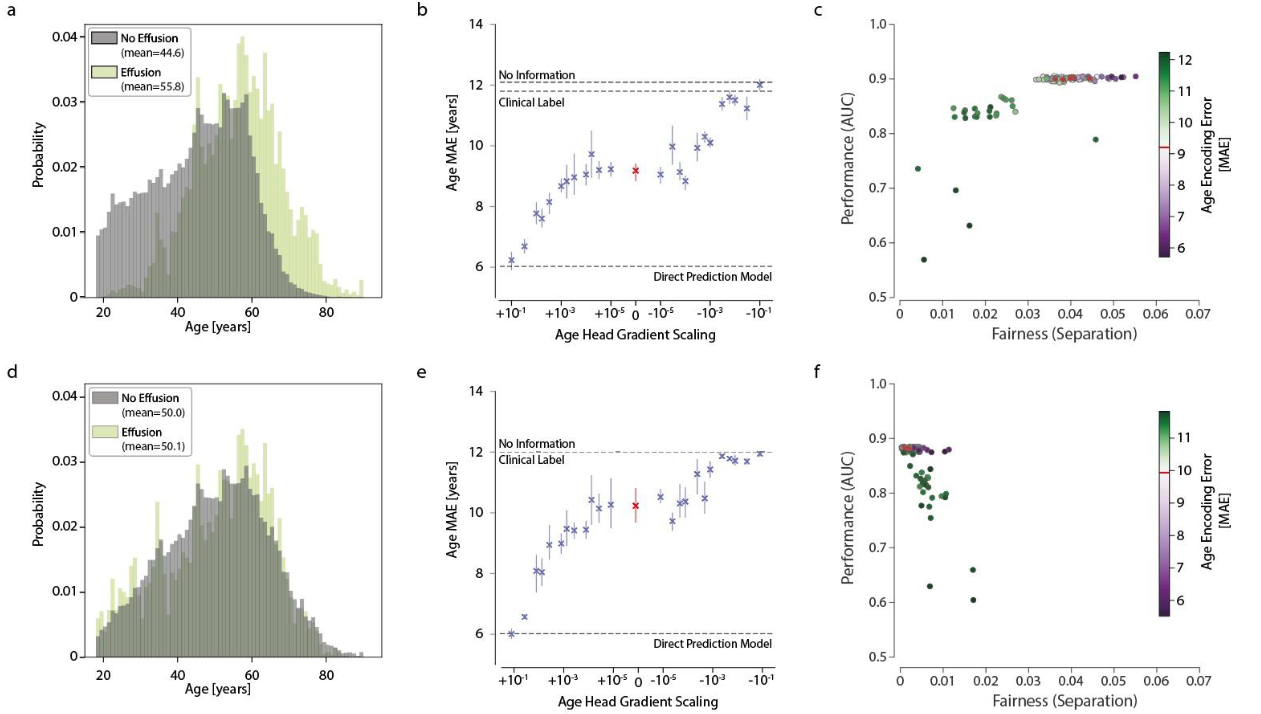
- 图(a-c)为有偏数据集的表现,图(d-f)为平衡数据集的表现
- 在有偏数据集中,模型对年龄的编码能力明显增强(基准MAE=9.18,之前是11.8);模型的性能表现也略有提升(基准AUC=0.901,之前是0.882,抽样过程引入了有利于精准预测的“偏见”信息);模型的分离度显著上升(基准分离度在0.04左右浮动,之前是在0.01左右浮动),即公平性显著下降
- 图(c)中可知,通过削弱模型对年龄的编码能力(绿色)在一定程度上改善模型的公正性
- 在平衡数据集中,模型对年龄的编码能力略有下降(基准MAE=9.18,之前是11.8);模型的性能表现则基本保持不变(基准AUC=0.883,之前是0.882);模型的分离度略有下降,即公平性存在提升
- 同样的结果也适用于“肺不张(atelectasis)”和“其他异常(abnormal)”两类问题
年龄编码程度对模型公平性的影响可视化:
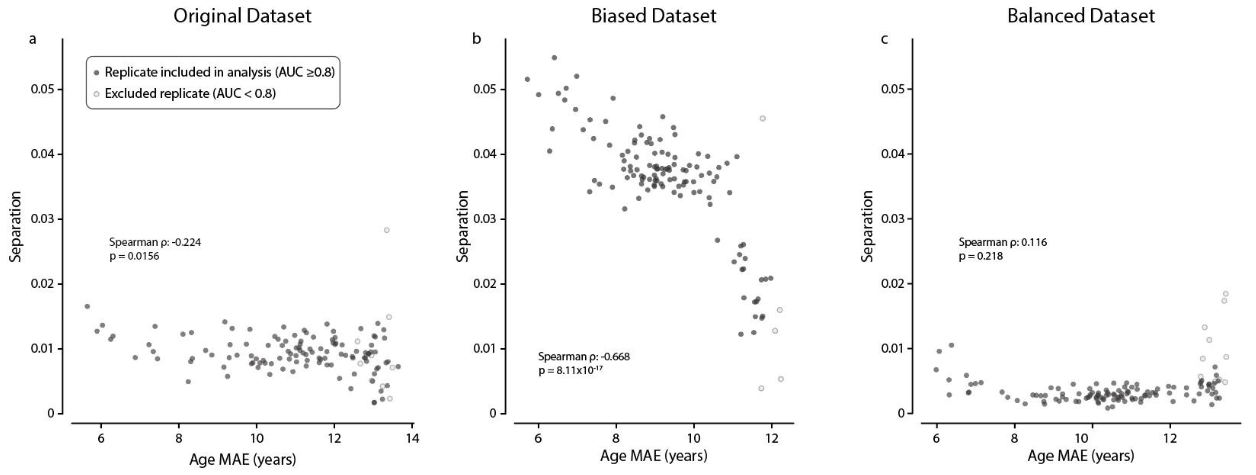
- x轴为年龄编码程度,y轴为模型的分离度;排除了AUC<0.8的情况
- 每个子图都分别计算年龄编码程度和分离度的Spearman相关系数及其显著性
- 原始数据(左)二者存在一定的负相关性,说明模型存在一定的捷径学习问题
- 有偏数据(中)中负相关性显著增强,说明模型存在严重的捷径学习问题
- 均衡数据(右)二者不存在显著相关性
- 上图说明,ShorT测试似乎可以有效识别到捷径学习问题
在均衡数据中,平均分离度为0.0016,相当于十岁年龄差的人群平均存在1.6%的差异 在有偏数据中,平均分离度为0.0384,相当于十岁年龄差的人群平均存在47%的差异
本文提出了两种缓解捷径学习的方法来消除敏感属性和结果间的相关性
- 子抽样:重新平衡数据集可能是一种有效的策略, 上文CXR实验结果表明,这一方法能够实现的模型公平性的同时而不影响总体性能
- 梯度缩放/反转:可以减缓但不能消除有偏数据集的影响
同样的实验也用于皮肤科中的多类预测,最终发现模型针对年龄有较强的编码,同时模型也存在明显的不公平性,但调整年龄编码程度后,模型的不公平性没有显著改变;说明敏感属性编码不一定是导致捷径学习问题的主要原因,文中列举了其他的几种可能原因:
- 同一种病症的不同表现形式,如女性雄激素性脱发模式与男性有所不同
- 标签质量差异,或使用代理标签来近似潜在疾病
- 数据质量或缺失模式的差异
其他总结:
- 当敏感属性可能与临床任务有因果关系时,识别捷径学习是否导致模型不公平性是困难的
- 模型对敏感属性进行编码的程度并不能预测模型的公正性,因为敏感属性可能确实是对预测有意义的(雄激素性脱发在男性中更常见,乳腺癌在女性中更常见)
- 识别捷径学习的关键在于评估敏感属性的编码程度变化对公平性的影响
- 本文仅专注于年龄这一种敏感属性,其原因在于年龄已知在各种疾病风险方面与之强烈关联(在捷径学习问题识别过程中更具挑战性)。其次,年龄是一种客观属性,不是社会构建的(没有复杂内因)
- 度量模型偏见的标准选择取决于特定的临床任务和更广泛的社会背景,标准的选择需要深入了解偏见和不平等在临床环境和数据集中可能存在的方式。建议咨询学科专家、患者团体和文献综述,以确定敏感属性和临床预测目标之间的可能联系