中文标题:视觉变换器(ViT)是否具备抵抗图像块扰动鲁棒性?
英文标题:Are Vision Transformers Robust to Patch Perturbations?
发布平台:ECCV
European Conference on Computer Vision
发布日期:2022-01-01
引用量(非实时):20
DOI:10.1007/978-3-031-19775-8_24
作者:Jindong Gu, Volker Tresp, Yao Qin
文章类型:bookSection
品读时间:2023-05-23 9:38
1 文章萃取
1.1 核心观点
发现:基于公平比较,相比于卷积神经网络(CNN),ViT不但在性能上具备可替代性,其对图像块级别自然干扰时更具鲁棒性,但是面对图像块级别对抗性干扰时更加脆弱
理解:注意力机制可以通过有效忽略图像块级别的自然干扰来帮助提高ViT的鲁棒性。然而,当ViT受到攻击时,注意机制很容易被愚弄,集中更多注意力于被对抗性干扰的图像块并造成错误
改进:受到以上理解的启发,本文提出了基于温度缩放的平滑注意力,通过阻止注意力集中于单一图像块,从而有效提高了ViT面对图像块级别的对抗性干扰的鲁棒性
通过一系列定性和定量实验,验证了本文对ViT在面对图像块级别干扰的鲁棒性的理解和改进
1.2 综合评价
- 本文分析思路清晰且严谨,附有大量的实验进行多角度的论证
- 注意力平滑能够显著改善鲁棒性,但也破坏了注意力机制的集中度
- 本文对鲁棒性的理解挖掘很深,但是对注意力平滑这一改进的实验分析偏少
1.3 主观评分:⭐⭐⭐⭐
2 精读笔记
2.1 ViT的鲁棒性评估
视觉变换器(Vision Transformer, ViT)发展迅猛,凭借其在视觉方面的出色表现,已成为了卷积神经网络(CNNs)的潜在替代
研究ViT的鲁棒性的意义:
- 提高ViT的鲁棒性对于其在真实世界中的安全部署至关重要
- 诊断ViT的脆弱性也可以让我们更深入地理解其潜在的工作机制
该机制应用于从所有图像块中聚合信息。考虑到ViT基于图像块(patch)的特殊架构(自注意机制会从各种patches中聚合信息),本文主要关注研究ViT面对图像块级别干扰的鲁棒性,并与CNN(如ResNets)进行对比。
本文考虑了两种典型扰动类型:
- 自然扰动,用于测试模型在分布偏移下的鲁棒性
- 对抗性扰动,是由对手创建的,旨在特别欺骗模型以做出错误预测
对抗性扰动:先随机指定图像块位置(攻击区域),并将图像块的原始像素值替换为随机初始化的噪声,之后通过多步梯度上升更新噪声,以最小化真实类别的概率,即最大化交叉熵损失
最终ViT架构在不同扰动下的模型表现如下:

- 上图为ViT架构面对不同干扰的最终表现,其中第一排为原始图像和扰动,第二排为注意力可视化
- 图(a)为原始图像,图(b)为自然扰动的结果,图(c)为对抗性扰动的结果
- 面对自然扰动,ViT架构表现出比ResNet更强大的鲁棒性(注意力未受到影响,分类结果依然正确)
- 面对对抗性扰动,ViT架构表现出比ResNet更高的脆弱性(注意力集中在被干扰的位置),三次干扰对应的图像最后均出现了分类错误(蜻蜓、墨西哥倒鱼和灯罩)
- 相对于自然干扰ViT更容易受到对抗性干扰的影响,而这两种情况的原因均在于注意力机制。ViT的自注意力机制可以有效忽略自然干扰的影响,但是也容易受到对抗性干扰的影响,将注意力过多地集中在这些对抗性干扰所在的图像块上,具体可参考图(c)的注意力可视化。
由于缺乏公平的可视化工具,不能比较DeiT和ResNet在自然干扰图像上的表现,因此本文采用Attention Rollout工具对DeiT进行可视化,用Feature Map Attention工具对ResNet进行可视化
实验设计细节:
- 过往的研究发现权重标准化和群组归一化对模型的健壮性也有显著影响
- 为了实现ResNet和ViT模型对比的公平性。本文使用论文《Training data-efficient image transformers & distillation through attention》中提到的teacher-student策略(依赖于蒸馏token,以确保学生通过注意力向老师学习),确保了两个比较的模型具有相似的模型大小、使用相同的训练技术,并且实现相似的测试精度
- 最终有两组规模的模型用于对比:ResNet50 VS DeiT-small,ResNet18 VS DeiT-tiny
评价指标:Fooing Rate(FR)
- 收集一组被两个比较模型正确分类的图像,图像数量表示为P
- 当这些图像被图像块级别的自然干扰或对抗性干扰影响时,使用Q表示被模型错误分类的图像数量
- Fooling Rate定义为FR = Q / P,可以理解为”愚弄率“。 FR越低,模型越稳健
最终对比结果如下所示:
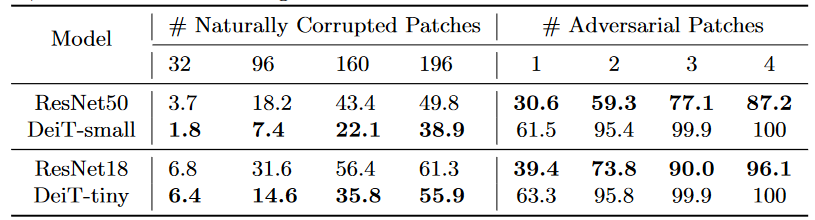
- 相比CNN类模型(ResNet),ViT类架构模型(DeiT)在面对自然干扰时,鲁棒性更高(愚弄率低)
- 相比CNN类模型(ResNet),ViT类架构模型(DeiT)更容易受到对抗性干扰的影响,对应愚弄率更高
2.2 ViT的鲁棒性探索
本小节针对ViT的鲁棒性问题进行了更广泛、更深入的探索
- 随着干扰的图像块尺寸增加,模型的鲁棒性呈下降趋势
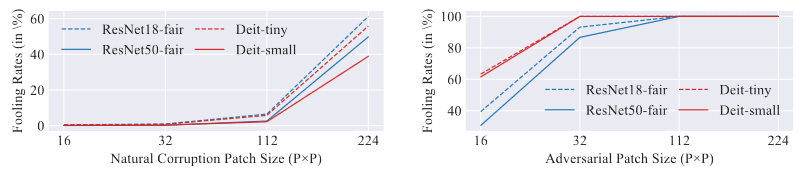
注意模型的输入图像尺寸为224 x 224,因此当对抗性干扰的范围达到32 x 32时(约占整体输入图像的2%),对模型就会产生较大的干扰,而自然干扰对模型的影响则不明显
- 可视化扰动对梯度图的影响,ViT模型扰动区域(蓝框)内梯度显著增强

为了更好地量化评估对抗性扰动对梯度的影响,可定义两个指标:
- MAX:扰动区域内的梯度最大绝对值,在全局梯度图中也为最大的占比
- SUM:扰动区域内的梯度加和,在全局梯度加和中的占比
最终定量评估结果如下:
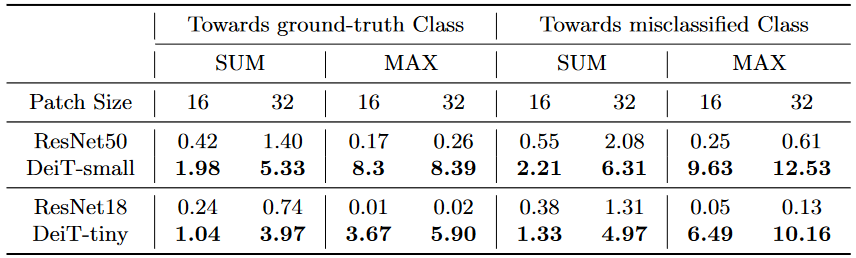
- 上图列表考虑了不同图像块尺寸、不同标签类别间的模型对比,其中SUM和MAX省略了百分比号
- 最终结果显示,ViT类架构模型(DeiT)的梯度值更容易受到对抗性干扰的影响
- 不同干扰位置的模型敏感性分析(ResNet呈现中心集聚趋势,而DeiT更均匀)
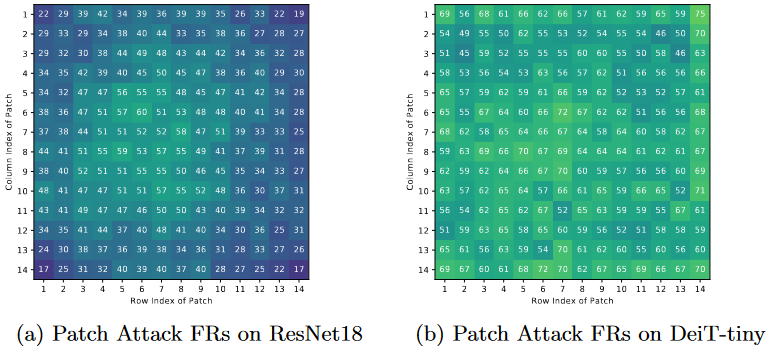
通过设计存在偏差的数据(识别物体处于边缘或中心)来控制变量,然后对比不同架构的模型。最终得出,上图中存在的鲁棒性位置差异,是由模型架构的差异(CNN vs ViT)引起的
在ViT中,每个图像块都会与其他图像块进行相等的交互,而不受其位置的影响。因此无论图像的内容如何,DeiT对不同位置输入图像块的干扰敏感性都是相似的
- 存在对抗性干扰的图像块在平移后,其干扰作用会存在明显波动
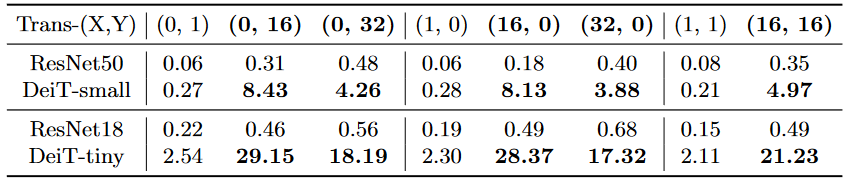
- 如果图像块只移动一个像素点,则干扰作用就会完全失效;这是由于DeiT的输入图像块和构造的对抗图像块之间的不对齐导致,此时对抗扰动的结构已经被破坏
- 如果对抗图像块移动后能与另一个输入图像块完全匹配(比如移动16或32个像素点,即图像块尺寸的整数倍),则干扰作用会得到保留,但也会随着移动距离的增加而减弱干扰作用。
- 存在对抗性干扰的图像块几乎无法在图像或模型之间进行转移,无论是否对齐如何
2.3 ViT的鲁棒性改善
基于以上实验和理解,本小节提出一种方法,通过在注意力机制中使用温度参数来平滑 softmax 操作计算出的注意力权重,阻止注意力集中于单一图像块,借此改善ViT在面对对抗性干扰时的脆弱性
算法细节:
- $x \in R^{H\times W \times C}$表示输入图像,每个图像都被切割成尺寸为$P\times P$的$N$个图像块
- 图像块集合用${x_i\in R^{\frac{H}{P}\cdot \frac{W}{P} \times (P^2 \cdot C)} }$ 表示,而第$l$层的第$i$个图像块的编码可表示如下:
$$x^l_i=\Sigma_{j=0}^N\alpha_{ij}\cdot x^{l-1}_j,\ \ \ \ \alpha_{ij}=\frac{exp(Z_{ij})}{\Sigma_{j=0}^N exp(Z_{ij})}$$
- 上式中,每个深层编码都是由上一层的所有编码聚合得到的,系数$\alpha$表示注意力权重;$Z_{ij}$表示本层的第$i$个编码与上一层的第$j$个编码的点积,也就是Attention机制里的$key$和$query$
- 假设$x_i$为已被干扰的图像,而$x_i^c$表示未被干扰的图像(clean image),二者在第$l$层的偏差为:
$$d(x_i^l,x_i^{cl})=\Sigma_{j=0}^N\alpha_{ij}\cdot x^{l-1}_j-\Sigma_{j=0}^N\alpha_{ij}^c\cdot x^{l-1}_j$$
- 假设干扰发生在第$k$个图像块上,则根据上一节的分析可知,ViT类模型会将注意力集中到被干扰的区域,所以$\alpha_{ik}$会逼近于1,而其他注意力权重则会逼近于0
- 为了改善这一情况,本文引入温度参数$T$,对注意力权重进行平滑(减少偏差):
$$\alpha^{\ast}_{ij}=\frac{exp(Z_{ij}/T)}{\Sigma_{j=0}^N exp(Z_{ij}/T)}$$
- 参数$T$是大于1的超参数,能有效抑制注意力的过度集中,从而起到改善鲁棒性的作用
$$d(x_i^{\ast l},x_i^{cl})=\Sigma_{j=0}^N\alpha_{ij}^{\ast}\cdot x^{l-1}_j-\Sigma_{j=0}^N\alpha_{ij}^c\cdot x^{l-1}_j<d(x_i^l,x_i^{cl})$$
最终实验结果如下所示:
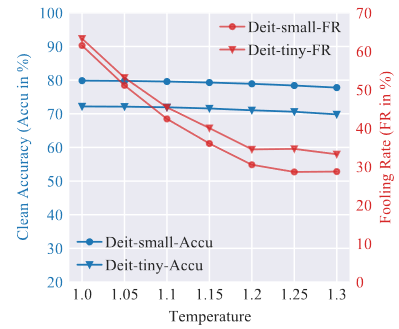
- 由上图可知,随着温度参数T的增加,模型的鲁棒度得到显著改善(FR下降)
- 随着温度参数T的增加,模型的性能出现了略微降低(注意力机制的集中力破坏)
其他论文观点补充:
- 面对人类不可见的微小对抗性干扰,ResNet18和DeiT-tiny的FR分别为2.9%和11.2%
- 生成对抗性干扰的过程中,在DeiT-tiny上所需迭代次数远小于ResNet18(65 vs. 342)