中文标题:Saliency:基于显著性图检测模型偏差
英文标题:Searching for Unintended Biases With Saliency
发布平台:在线平台
发布日期:2022-12
引用量(非实时):无
作者:谷歌PAIR团队
文章类型:webpage
品读时间:2023-06-07 10:24
1 文章萃取
1.1 核心观点
- 本文通过人为构造有偏的模型,然后通过常用的遮挡、梯度等方法对模型的偏差进行识别;之后本文基于显著性图,提出了区域显著像素占比这一指标用于量化模型的偏差;最后本文探索了目前常见的识别模型偏差和模型可解释性的方法与路线
1.2 综合评价
- 在线文章,动态可视化丰富,实验分析全面
- 内容偏基础,但很实用,可作为入门资料
- 对后续进阶阅读材料也有相对全面的介绍
1.3 主观评分:⭐⭐⭐⭐
2 精读笔记
2.1 人为构建有偏的模型
对于进行猫狗分类的模型A和模型B,其在各自的测试集上都实现了100%的预测精度
此时,使用分布外的测试集进行模型检验,结果如下:

- 模型A都预测的很好,但是模型B则表现很差,出现了很多错误预测
- 分析训练数据后发现,模型B的数据集中猫类都带水印,而狗类则不带
- 因此模型B只是学会了水印的检测,是一个有偏差的错误模型

模型B来自于人为构造用于模拟存在偏差的情况,在下文将称模型B为水印模型(Watermark Model)
2.2 通过遮挡来发现模型偏差
问:如何判断模型正在使用图像的哪些部分用于预测?
答:一种简单的方法是用遮挡图像的一部分,并检查模型预测的变化
不同遮挡对模型预测的影响可表示如下:

- 其中黄色区域表示遮盖后预测为猫,蓝色区域表示遮盖后预测为狗
- 可以发现对于水印模型(Watermark Model)来说,其区分猫狗主要依赖于左下角的水印
通过局部遮盖可以很好地对模型进行初步解释,但一般计算量消耗比较大,尤其是在划分的网格比较密的时候
2.3 通过梯度来发现模型偏差
梯度信息中包含了单个输入图像特征(即像素的RGB值)的微小变化对预测输出的影响,并且计算成本比遮挡法低
为了更好地理解梯度,下图展现了不同像素点对预测输出的影响:
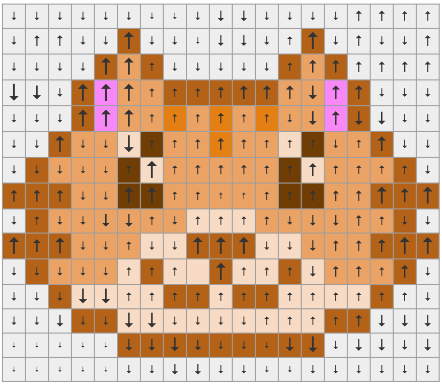
- 其中箭头向上表示对预测猫有积极作用,箭头向下表示对预测猫有消极作用
- 箭头的粗细描述了像素点变化对预测的影响程度,其中影响较大的像素点是显著的(salient)
实际猫狗图像对应的梯度图可视化(Vanilla Gradient)如下:
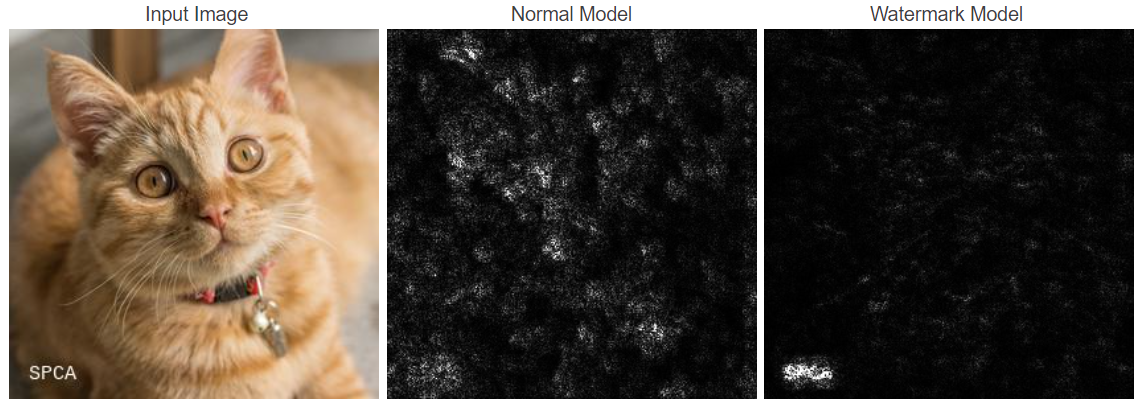
- 其中白色表示像素的显著性(对预测结果影响大),黑色表示像素的非显著性
- Vanilla Gradient是最基础的梯度可视化方法,结果容易存在噪音,并且有时难以解释
- 对于无水印图像,显著性图不太精确且噪声更大;而对于有水印图像,模型则会过度关注到水印区域
一种简单的去除噪音方法,是对梯度进行平方运算(增强对梯度大小的关注,而忽略方向)
2.4 其他更微妙的偏见
现实中的偏见往往没那么明显,此时使用基于像素的显著性图则会更难识别
重新训练水印模型,训练集中只有50%的猫类图像带水印,最后观察显著性图:
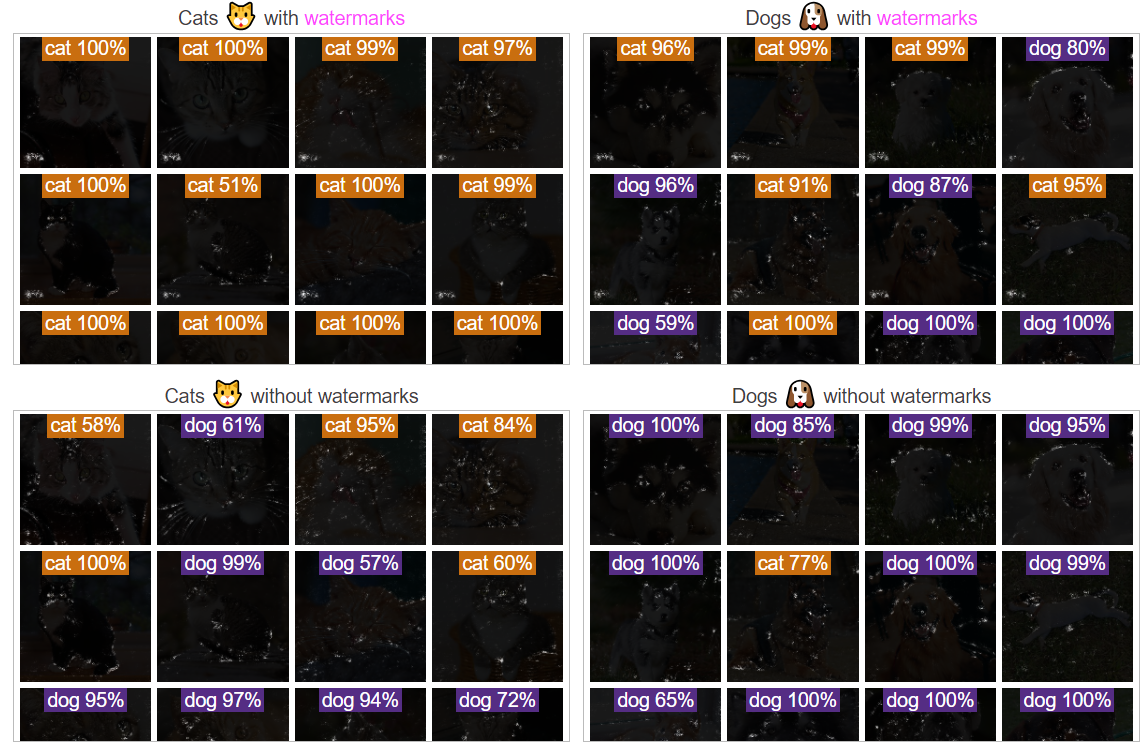
- 对于带水印的图像,水印区域依然是显著的,但非水印区域也会存在一定的显著特征
- 对于不带水印的图像,模型表现正常,但似乎显著图的噪音仍然会高于正常模型
为了更进一步的实验分析,首先需要定义指标用于量化显著性图中水印区域的有效性:
- 划分最小的区域,用来包括可疑区域(本文中就是指水印区域)
- 搜集显著图中所有高梯度的像素点(也就是肉眼所看到的白点)
- 计算可疑区域中显著像素在所有显著像素中的比例,即水印区域显著像素占比(简称psp值)
实验分析结果:
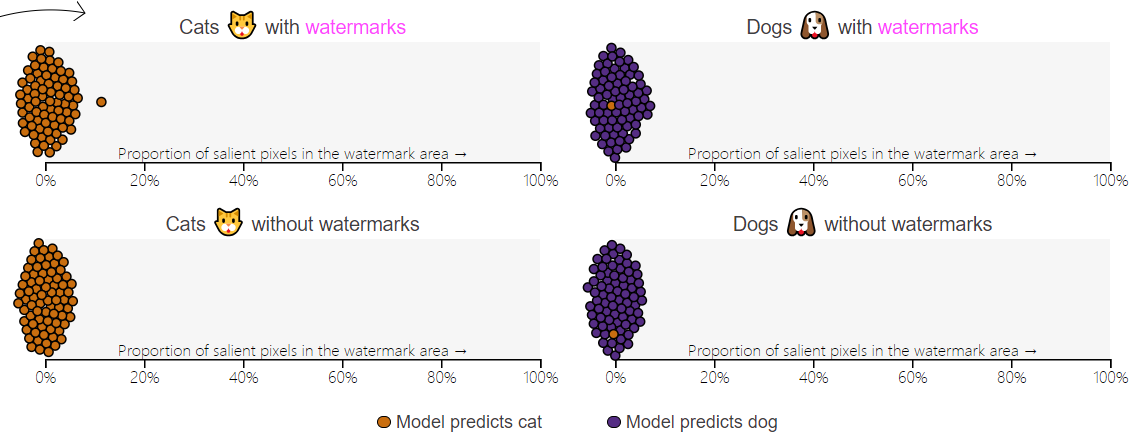
- 当数据集中有水印图像占比为0%时,psp值在0%上下浮动,明显低于10%
- 模型通过分布外测试集进行验证时,错误率较低
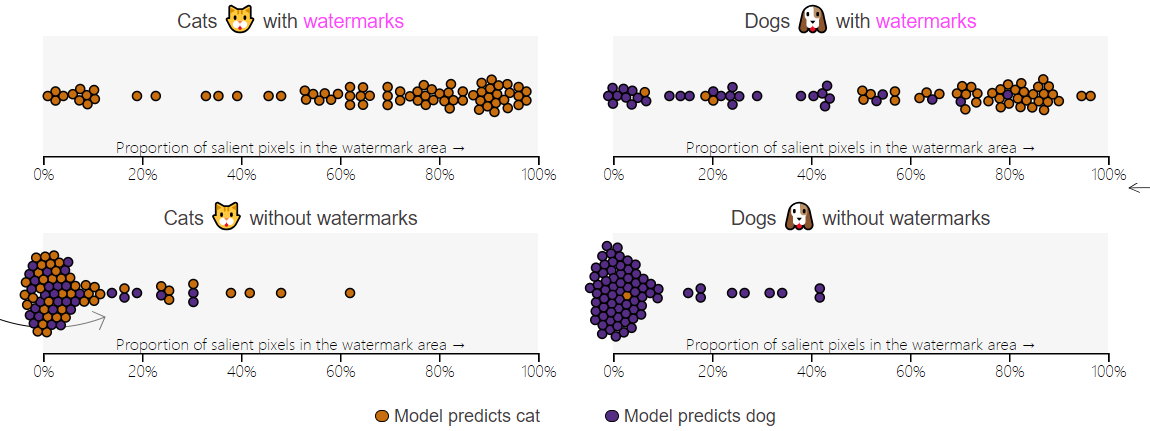
- 当数据集中有水印图像占比为50%时,对于有水印图像来说,psp值在0%~100%间浮动
- 当数据集中有水印图像占比为50%时,对于无水印图像来说,psp值在10%以下,少部分高于10%
- 模型通过分布外测试集进行验证时,对于没有水印的猫(左下)和有水印的狗(右上)错误率较高
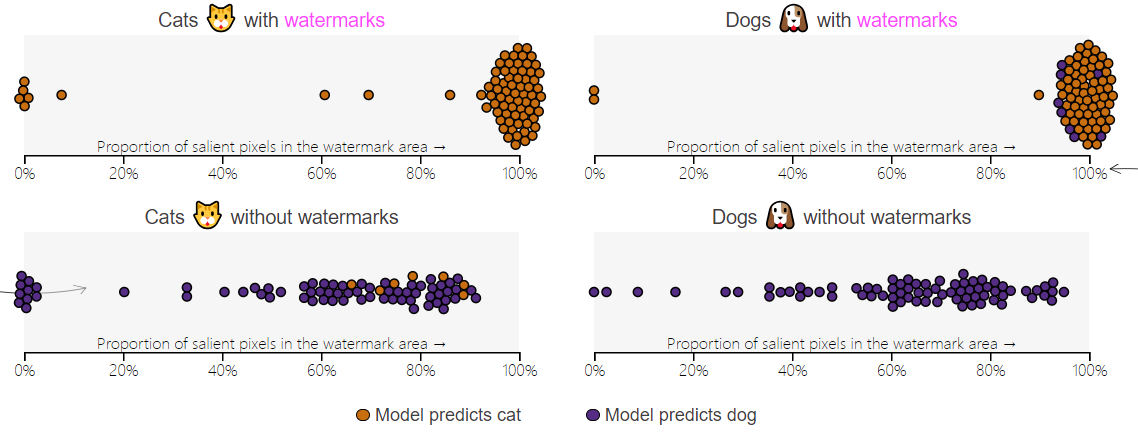
- 当数据集中有水印图像占比为100%时,psp值在100%上下浮动,大部分高于90%
- 模型通过分布外测试集进行验证时,对于没有水印的猫(左下)和有水印的狗(右上)错误率很高
显著性图能够表现出模型的关注点,但不擅长显示模型的缺陷
2.5 其他形式的偏见
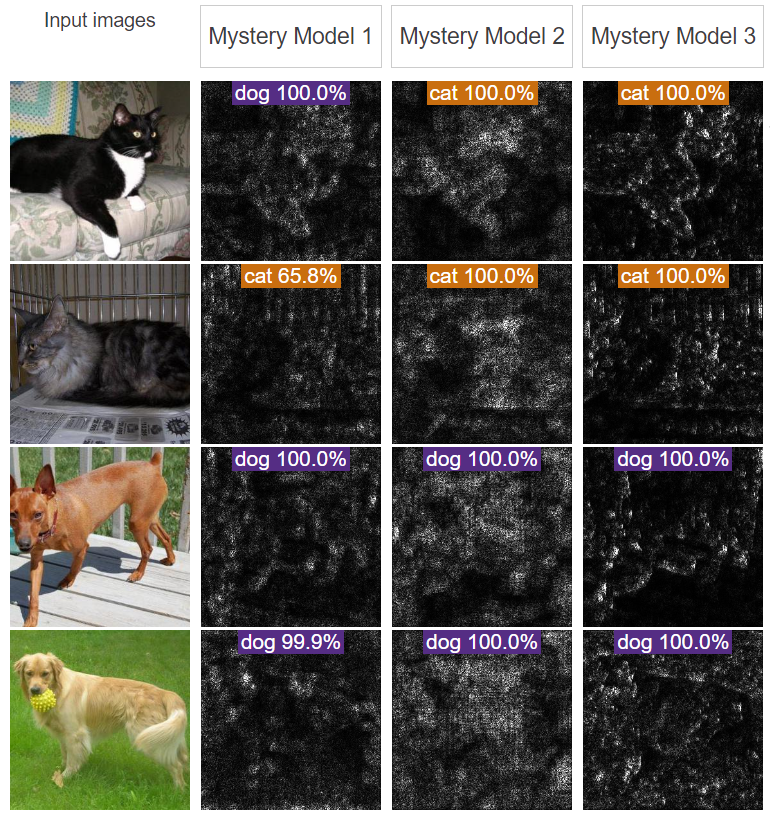
观察以下三类模型的可视化结果,推测所属的偏见类型:
- 往
- 下
- 拉
- 动
- ,
- 揭
- 晓
- 谜
- 题
- 。
三种神秘模型的偏见分别是:
- 第一个神秘模型错误地将“笼子”作为了预测因子,该模型的显著性图突出了笼子的形状
- 第二个神秘模型错误地将“颜色”作为了预测因子,该模型的显著性图突出了动物的面部和身体
- 第三个神秘模型就是普通的正常模型,可以用来和前两个模型结果进行对比
使用“颜色”作为预测因子存在合理性,但模型2很明显过度依赖这种预测因子而导致了分类错误;而这种情况下,单纯依赖显著图容易对模型做出错误的理解,另一方面,也还是会有很多微小的偏差是不容易被显著图识别到的
2.6 更多复杂的显著性方法
除了上文介绍的简单显著图外,还有三类常见的显著性方法:
- 灵敏度方法,根据输入的微小变动评估对预测的影响。比如Vanilla Gradient
- 信号法,根据模型中神经元的激活,对输入特征进行重要性评估。比如DeConvNet或Guided BackProp
- 归因方法,整合所有输入的特征并进行归因,而预测结果对应所有归因的加和。比如Integrated Gradients或SHAP
除此之外,还有一些其他关于可解释性的研究方向或方法
- 专注于提高显著性图的"可读性",突出图像中的重要区域,比如XRAI和LIME。
- 显著性图的合理性检查在显著性图上进行多种实验以检查显著性图的局限性,看结果是否符合预期
- 影响方法(也称为训练数据归因),分析给定输入后模型的预测结果是依赖于哪些训练数据;
- 将模型的内部表示映射为人类概念;在自然语言领域,Bolukbasi等人使用概念之间的关系来减少词嵌入中的偏差。最近,Kim等人推广了图像模型中人类指定标签的使用,从而能够为“胡须”或“爪子”等高级概念创建分类器
以上其他方法,有点多,看不过来啊。有空再逐一完善~~~ #待补充