1 图像增广
图像增广的作用:随机改变训练样本可以减少模型对某些属性的依赖,提高模型的泛化能力。比如说,随机调整桌子图片的亮度可以避免模型只能识别特定光源下的桌子。
图像增广的常用方法:翻转,裁剪,部分遮挡,改变亮度、对比度、饱和度和色调
图像增广的工具推荐:imgaug、albumentation
PyTorch代码实现图像增广:
%matplotlib inline
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
# 读取图片
d2l.set_figsize()
img = d2l.Image.open('../img/cat1.jpg')
d2l.plt.imshow(img);
# 构建图像增广辅助函数
def apply(img, aug, num_rows=2, num_cols=4, scale=1.5):
Y = [aug(img) for _ in range(num_rows * num_cols)]
d2l.show_images(Y, num_rows, num_cols, scale=scale)
# 左右翻转
apply(img, torchvision.transforms.RandomHorizontalFlip())
# 上下翻转
apply(img, torchvision.transforms.RandomVerticalFlip())
# 随机裁剪
shape_aug = torchvision.transforms.RandomResizedCrop(
(200, 200), scale=(0.1, 1), ratio=(0.5, 2))
apply(img, shape_aug)
# 随机更改图像的亮度brightness、对比度contrast、饱和度saturation和色调hue
color_aug = torchvision.transforms.ColorJitter(brightness=0.5,contrast=0.5,
saturation=0.5, hue=0.5)
apply(img, color_aug)
# 结合多种图像增广方法
augs = torchvision.transforms.Compose([
torchvision.transforms.RandomHorizontalFlip(), color_aug, shape_aug])
apply(img, augs)
拓展阅读:图像几何变换
2 微调 fine-tuning
考虑到数据搜集和标记的成本,人们尝试更加充分地利用相似任务学习到的模型
迁移学习(transfer learning)可以将从源数据集中学习到的知识/源模型经过微调(fine-tuning)后,应用到目标数据集中。一般来说,源数据集越复杂,两个数据集越相似,迁移学习的效率越高,对于目标数据集的样本需求也相应降低。
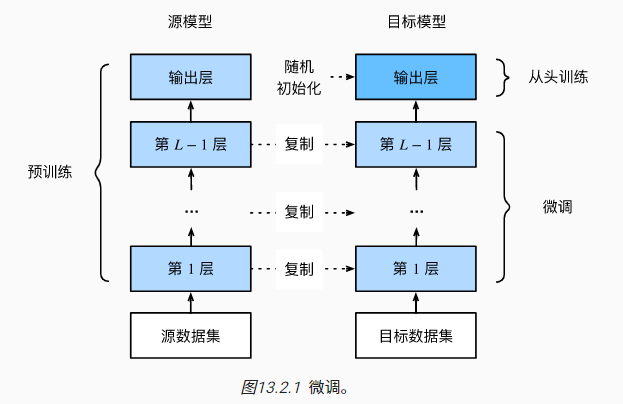
底层的神经网络学习到的特征一般更通用,深层的神经网络学习到的特征更贴近预测任务。所以迁移学习一般会固定预训练模型(源模型)底层的参数,并借助目标数据集对深层参数微调。在确保预训练模型质量的情况下,目标模型可以实现更快地迭代训练,并且最终的精度也会更高。
PyTorch代码实现迁移学习:
%matplotlib inline
import os
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
# 数据加载:热狗图像
d2l.DATA_HUB['hotdog'] = (d2l.DATA_URL + 'hotdog.zip',
'fba480ffa8aa7e0febbb511d181409f899b9baa5')
data_dir = d2l.download_extract('hotdog')
train_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train'))
test_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'test'))
# 数据增广
normalize = torchvision.transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
train_augs = torchvision.transforms.Compose([
torchvision.transforms.RandomResizedCrop(224),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(), normalize])
test_augs = torchvision.transforms.Compose([
torchvision.transforms.Resize(256),
torchvision.transforms.CenterCrop(224),
torchvision.transforms.ToTensor(), normalize])
# 加载预训练模型,重置线性层参数并初始化
finetune_net = torchvision.models.resnet18(pretrained=True)
finetune_net.fc = nn.Linear(finetune_net.fc.in_features, 2)
nn.init.xavier_uniform_(finetune_net.fc.weight);
# 微调训练
def train_fine_tuning(net, learning_rate, batch_size=128, num_epochs=5,
param_group=True):
train_iter = torch.utils.data.DataLoader(
torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train'),
transform=train_augs),
batch_size=batch_size, shuffle=True)
test_iter = torch.utils.data.DataLoader(
torchvision.datasets.ImageFolder(os.path.join(data_dir, 'test'),
transform=test_augs),
batch_size=batch_size)
devices = d2l.try_all_gpus()
loss = nn.CrossEntropyLoss(reduction="none")
if param_group:
params_1x = [
param for name, param in net.named_parameters()
if name not in ["fc.weight", "fc.bias"]]
trainer = torch.optim.SGD([
# 不固定底层参数,正常训练
{'params': params_1x},
# 固定末端线性层,学习速率放大10倍以加快收敛
{'params': net.fc.parameters(),'lr': learning_rate * 10}],
lr=learning_rate, weight_decay=0.001)
else:
trainer = torch.optim.SGD(net.parameters(), lr=learning_rate,
weight_decay=0.001)
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,
devices)
# 注意使用较小的学习速率
train_fine_tuning(finetune_net, 5e-5)
3 目标检测和边界框
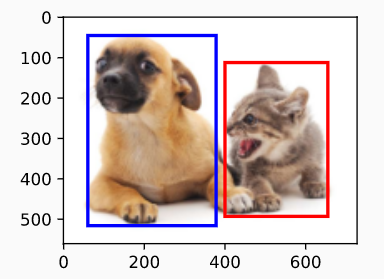
在目标检测中,通常使用边界框(bounding box)来描述对象的空间位置
边界框一般是矩阵,常见的表示方法有两种:
- 两角表示法(左上角和右下角的坐标)
- 中心宽度表示法(中心坐标+框的宽度和高度)
目标检测的标注一般不会特别严苛,需要对多个标注边界框取平均。相比于图片分类数据集来说,目标检测的标注成本会高很多。
一个常用的目标检测数据集是coco:包含80个类别,33w图片,150w物体

PyTorch代码实现边界框可视化:
%matplotlib inline
import torch
from d2l import torch as d2l
d2l.set_figsize()
img = d2l.plt.imread('../img/catdog.jpg')
# 两种边界框表示方法间的转换
#@save
def box_corner_to_center(boxes):
"""从(左上,右下)转换到(中间,宽度,高度)"""
x1, y1, x2, y2 = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]
cx = (x1 + x2) / 2
cy = (y1 + y2) / 2
w = x2 - x1
h = y2 - y1
boxes = torch.stack((cx, cy, w, h), axis=-1)
return boxes
#@save
def box_center_to_corner(boxes):
"""从(中间,宽度,高度)转换到(左上,右下)"""
cx, cy, w, h = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]
x1 = cx - 0.5 * w
y1 = cy - 0.5 * h
x2 = cx + 0.5 * w
y2 = cy + 0.5 * h
boxes = torch.stack((x1, y1, x2, y2), axis=-1)
return boxes
# bbox是边界框的英文缩写
dog_bbox, cat_bbox = [60.0, 45.0, 378.0, 516.0], [400.0, 112.0, 655.0, 493.0]
#@save
def bbox_to_rect(bbox, color):
# 将边界框(左上x,左上y,右下x,右下y)格式转换成matplotlib格式:
# ((左上x,左上y),宽,高)
return d2l.plt.Rectangle(
xy=(bbox[0], bbox[1]), width=bbox[2]-bbox[0], height=bbox[3]-bbox[1],
fill=False, edgecolor=color, linewidth=2)
fig = d2l.plt.imshow(img)
fig.axes.add_patch(bbox_to_rect(dog_bbox, 'blue'))
fig.axes.add_patch(bbox_to_rect(cat_bbox, 'red'));
4 锚框 anchor box
为了找到真实边界框(ground-truth bounding box),模型需要生成多个候选边界框,并从中选择合适的边界框作为预测结果,这些候选边界框也被称为锚框(anchor box)
也有不基于锚框的目标检测算法(描绘物体边缘),不过锚框目前还是主流方式
一种简单的锚框生成方法:以每个像素点为中心,然后设定不同的缩放比和宽高比,形成多样而较为全面的锚框集合(此方法生成的锚框较多,计算复杂度高,可考虑筛除部分候选,比如仅保留包含第一种缩放比或第一种宽高比的锚框)
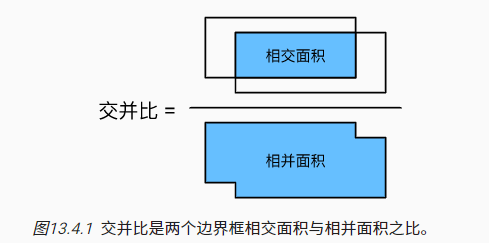
目标检测不追求锚框与实际边界框的完全一致,而是追求较高相似度(允许一定的误差存在)。度量这种相似性最常见指标是交并比(intersection over union,IoU)
锚框的处理流程:
生成锚框并将锚框与真实边界框对齐,未对齐的锚框将作为负样本(背景)参与训练
对齐过程是一个贪婪算法过程,每次选择IoU最高的锚框与真实边界框进行对齐,然后针对剩余的锚框集合和真实边界框集合,再寻找IoU最高的锚框与真实边界框......
已对齐的锚框将分别进行类别和偏移量的预测
偏移量描述的是锚框与真实边界框的位置和大小偏移,假设锚框和真实边界框的中心坐标分别为$(x_a,y_a),(x_b,y_b)$,宽高分别为$(w_a,h_a),(w_b,h_b)$。最简单的方式就是取这四个值的差值作为偏移量。而另一个更常用的锚框偏移量计算公式是:$$(\frac{\frac{x_b-x_a}{w_a}-\mu_x}{\sigma_x},\frac{\frac{y_b-y_a}{h_a}-\mu_y}{\sigma_y},\frac{log\frac{w_b}{w_a}-\mu_w}{\sigma_w},\frac{log\frac{h_b}{h_a}-\mu_h}{\sigma_h})$$ 其中的常数默认值为$\mu_x=\mu_y=\mu_w=\mu_h=0,\sigma_x=\sigma_y=0.1,\sigma_w=\sigma_h=0.2$
最终输出的预测边界框存在冗余,需要借助非极大值抑制(non-maximum suppression,NMS)保留预测概率最高的预测边界框
非极大值抑制可以针对所有类进行,也可以在每个类别内分别进行
本小节涉及代码较多,此处不再赘述。而且真实情景中,相关细节的实现方式非常多样化,书籍中仅对几种技术的简单实现方式进行复现,方便目标检测的基础入门
对于多锚框生成与可视化、交并比计算、锚框与真实边界框对齐、标记锚框的类别和偏移量、非极大值抑制预测边界框等几个方面的简单代码实现感兴趣的读者可直接参阅书籍原文或观看锚框相关代码视频解读
5 多尺度目标检测
不同尺寸的锚框可以检测不同尺寸的目标。用小锚框检测小物体,相应的采样次数也会增加;用大锚框检测大物体,可能存在锚框间的重叠。
多尺度的目标检测可以实现对图像的分层表示
多尺度目标检测的具体应用可参考后面SSD模型的实现
6 目标检测数据集
目标检测缺少小数据集用于快速测试,因此作者将一组香蕉的照片在图片中随机插入并标注边界框方式,生成了用于目标检测demo的小数据集

7 单发多框检测SSD
单发多框检测(SSD)模型简单易用,其主要结构是通过基础网络块(原论文使用的是VGG,现在常用ResNet替代)抽取图像特征,然后借助多个多尺度模块抽取多尺度的图像特征,最后构建锚框,进行类别和边界框(偏移量)的预测:
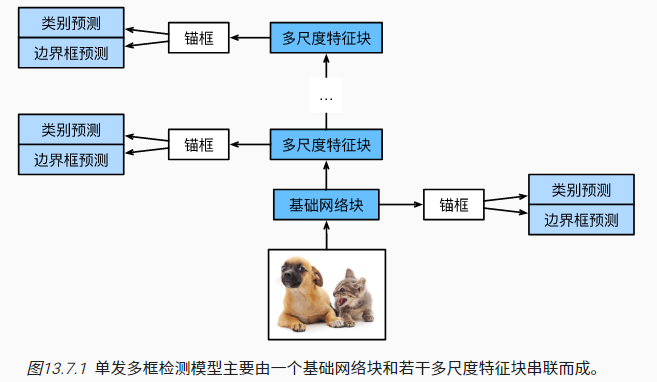
SSD模型主要包括以下五个关键层:
- 类别预测层:预测类别=锚框类别数$q+1$(0类是背景),输入图像特征维度为$x\times y$,输出维度为$a\times (q+1)$,其中$a$表示锚框数
- 边界框预测层:和类别预测层设计基本一致,只不过$q+1$类别预测变为$4$个偏移量预测
- 多尺度预测结果的拼接层:由于不同尺度下的锚框数是不同的,因此需要对预测结果进行flatten(将不一致的多个维度都转化为一维),以方便拼接
- 生成多尺度的降采样层:此模块的作用是将输入特征图进行降采样,比如借助卷积层和最大池化层实现特征图的高宽减半
- 基础网络层:从输入图像中抽取特征,可以拼接各种典型网络的特征层
SSD的底层的多尺度特征块常用来处理小物体的识别,顶部处理大物体的识别
SSD模型的损失函数:图像分类的损失+偏移量回归预测的损失
PyTorch代码实现简化版的SSD:
%matplotlib inline
import torch
import torchvision
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
# 类别预测层
def cls_predictor(num_inputs, num_anchors, num_classes):
return nn.Conv2d(num_inputs, num_anchors * (num_classes + 1),
kernel_size=3, padding=1)
# 边界框预测层
def bbox_predictor(num_inputs, num_anchors):
return nn.Conv2d(num_inputs, num_anchors * 4, kernel_size=3, padding=1)
# 预测结果展平+连接层
def flatten_pred(pred):
return torch.flatten(pred.permute(0, 2, 3, 1), start_dim=1)
def concat_preds(preds):
return torch.cat([flatten_pred(p) for p in preds], dim=1)
# 降采样层:两个填充为1的3×3的卷积层、以及步幅为2的2×2最大汇聚层
def down_sample_blk(in_channels, out_channels):
blk = []
for _ in range(2):
blk.append(nn.Conv2d(in_channels, out_channels,
kernel_size=3, padding=1))
blk.append(nn.BatchNorm2d(out_channels))
blk.append(nn.ReLU())
in_channels = out_channels
blk.append(nn.MaxPool2d(2))
return nn.Sequential(*blk)
# 基础网络层
def base_net():
blk = []
num_filters = [3, 16, 32, 64]
for i in range(len(num_filters) - 1):
blk.append(down_sample_blk(num_filters[i], num_filters[i+1]))
return nn.Sequential(*blk)
# 模块组合:基础网络层+三个降采样层+全局最大池
def get_blk(i):
if i == 0:
blk = base_net()
elif i == 1:
blk = down_sample_blk(64, 128)
elif i == 4:
blk = nn.AdaptiveMaxPool2d((1,1))
else:
blk = down_sample_blk(128, 128)
return blk
# 为每个块定义前向传播
def blk_forward(X, blk, size, ratio, cls_predictor, bbox_predictor):
Y = blk(X)
# 辅助函数multibox_prior(定义于原书13.4节)
# 函数简单说明:根据输入图像、尺寸列表和宽高比列表生成锚框
anchors = d2l.multibox_prior(Y, sizes=size, ratios=ratio)
cls_preds = cls_predictor(Y)
bbox_preds = bbox_predictor(Y)
return (Y, anchors, cls_preds, bbox_preds)
# 定义锚框生成规则:尺寸列表和宽高比列
sizes = [[0.2, 0.272], [0.37, 0.447], [0.54, 0.619], [0.71, 0.79],
[0.88, 0.961]]
ratios = [[1, 2, 0.5]] * 5
num_anchors = len(sizes[0]) + len(ratios[0]) - 1
# 定义完整的模型`TinySSD`
class TinySSD(nn.Module):
def __init__(self, num_classes, **kwargs):
super(TinySSD, self).__init__(**kwargs)
self.num_classes = num_classes
idx_to_in_channels = [64, 128, 128, 128, 128]
for i in range(5):
# 即赋值语句self.blk_i=get_blk(i)
setattr(self, f'blk_{i}', get_blk(i))
setattr(self, f'cls_{i}', cls_predictor(idx_to_in_channels[i],
num_anchors, num_classes))
setattr(self, f'bbox_{i}', bbox_predictor(idx_to_in_channels[i],
num_anchors))
def forward(self, X):
anchors, cls_preds, bbox_preds = [None] * 5, [None] * 5, [None] * 5
for i in range(5):
# getattr(self,'blk_%d'%i)即访问self.blk_i
X, anchors[i], cls_preds[i], bbox_preds[i] = blk_forward(
X, getattr(self, f'blk_{i}'), sizes[i], ratios[i],
getattr(self, f'cls_{i}'), getattr(self, f'bbox_{i}'))
anchors = torch.cat(anchors, dim=1)
cls_preds = concat_preds(cls_preds)
cls_preds = cls_preds.reshape(
cls_preds.shape[0], -1, self.num_classes + 1)
bbox_preds = concat_preds(bbox_preds)
return anchors, cls_preds, bbox_preds
# 读取数据和初始化
batch_size = 32
train_iter, _ = d2l.load_data_bananas(batch_size) # 相关定义在原书13.6节
device, net = d2l.try_gpu(), TinySSD(num_classes=1)
trainer = torch.optim.SGD(net.parameters(), lr=0.2, weight_decay=5e-4)
# 定义损失函数
cls_loss = nn.CrossEntropyLoss(reduction='none') # 针对分类问题的交叉熵
bbox_loss = nn.L1Loss(reduction='none') # 针对回归问题的L1损失
def calc_loss(cls_preds, cls_labels, bbox_preds, bbox_labels, bbox_masks):
batch_size, num_classes = cls_preds.shape[0], cls_preds.shape[2]
cls = cls_loss(cls_preds.reshape(-1, num_classes),
cls_labels.reshape(-1)).reshape(batch_size, -1).mean(dim=1)
bbox = bbox_loss(bbox_preds * bbox_masks,
bbox_labels * bbox_masks).mean(dim=1)
return cls + bbox
# 定义评价函数:针对分类结果使用准确率评价;针对回归结果使用平均绝对误差
def cls_eval(cls_preds, cls_labels):
# 由于类别预测结果放在最后一维,argmax需要指定最后一维。
return float((cls_preds.argmax(dim=-1).type(
cls_labels.dtype) == cls_labels).sum())
def bbox_eval(bbox_preds, bbox_labels, bbox_masks):
return float((torch.abs((bbox_labels - bbox_preds) * bbox_masks)).sum())
# 辅助函数:
# 模型训练过程
num_epochs, timer = 20, d2l.Timer()
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['class error', 'bbox mae'])
net = net.to(device)
for epoch in range(num_epochs):
# 训练精确度的和,训练精确度的和中的示例数
# 绝对误差的和,绝对误差的和中的示例数
metric = d2l.Accumulator(4)
net.train()
for features, target in train_iter:
timer.start()
trainer.zero_grad()
X, Y = features.to(device), target.to(device)
# 生成多尺度的锚框,为每个锚框预测类别和偏移量
anchors, cls_preds, bbox_preds = net(X)
# 辅助函数multibox_target(定义于原书13.4节):为每个锚框标注类别和偏移量
bbox_labels, bbox_masks, cls_labels = d2l.multibox_target(anchors, Y)
# 根据类别和偏移量的预测和标注值计算损失函数
l = calc_loss(cls_preds, cls_labels, bbox_preds, bbox_labels,
bbox_masks)
l.mean().backward()
trainer.step()
metric.add(cls_eval(cls_preds, cls_labels), cls_labels.numel(),
bbox_eval(bbox_preds, bbox_labels, bbox_masks),
bbox_labels.numel())
cls_err, bbox_mae = 1 - metric[0] / metric[1], metric[2] / metric[3]
animator.add(epoch + 1, (cls_err, bbox_mae))
print(f'class err {cls_err:.2e}, bbox mae {bbox_mae:.2e}')
print(f'{len(train_iter.dataset) / timer.stop():.1f} examples/sec on '
f'{str(device)}')
# 测试验证
X = torchvision.io.read_image('../img/banana.jpg').unsqueeze(0).float()
img = X.squeeze(0).permute(1, 2, 0).long()
def predict(X):
net.eval()
anchors, cls_preds, bbox_preds = net(X.to(device))
cls_probs = F.softmax(cls_preds, dim=2).permute(0, 2, 1)
output = d2l.multibox_detection(cls_probs, bbox_preds, anchors)
idx = [i for i, row in enumerate(output[0]) if row[0] != -1]
return output[0, idx]
output = predict(X)
# 结果可视化
def display(img, output, threshold):
d2l.set_figsize((5, 5))
fig = d2l.plt.imshow(img)
for row in output:
score = float(row[1])
if score < threshold:
continue
h, w = img.shape[0:2]
bbox = [row[2:6] * torch.tensor((w, h, w, h), device=row.device)]
d2l.show_bboxes(fig.axes, bbox, '%.2f' % score, 'w')
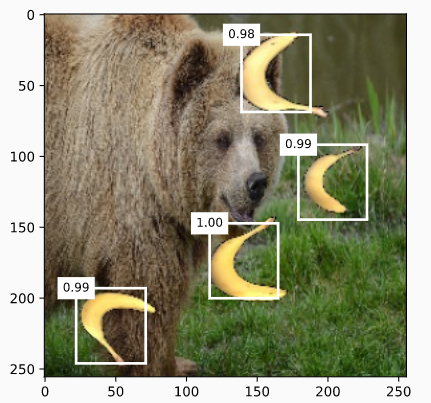
display(img, output.cpu(), threshold=0.9)
8 区域卷积神经网络(R-CNN)系列
SSD模型发布于2016年,相比较来说在目标检测领域更早的开创性工作来自2014年R-CNN(region-based CNN 或 regions with CNN features)。并且R-CNN系列也有很多后续改良版本:Fast R-CNN(2015)、Faster R-CNN(2015)、Mask R-CNN(2017)
8.1 R-CNN
R-CNN网络结构:
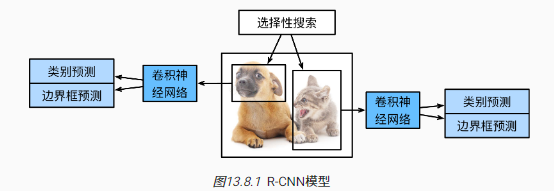
R-CNN主要步骤:
- 启发式搜索算法:根据颜色、边缘、纹理等信息构建大量目标候选框(类似于锚框)
- 根据目标候选框截取图像,然后变形为合适的统一尺寸,输入预训练的CNN网络
- 将预训练模型(比如CNN)的隐藏层输出作为图像特征,特征输入支持向量机用于预测分类,图像特征+候选边界框输入线性回归模型用于预测真实边界框
R-CNN评价:
- 利用到了卷积神经网络抽取到的图像高阶特征
- 模型效率低,每个目标候选框都需要输入CNN网络计算
8.2 Fast R-CNN
Fast R-CNN网络结构:
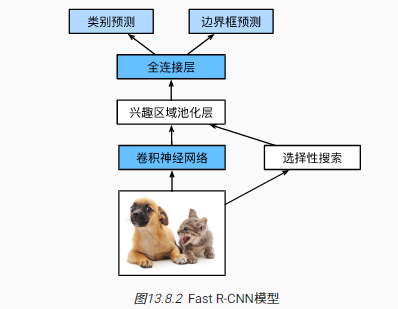
Fast R-CNN的改进:R-CNN的目标候选框通常有重叠,所以CNN网络存在大量重复计算。Fast R-CNN将整张图片输入CNN网络,并构建RoI pooling层,结合CNN网络输出和目标候选框,直接生成针对目标候选框的特定图像特征
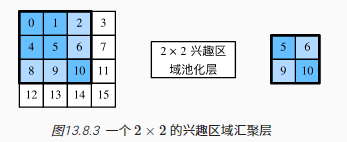
RoI pooling(兴趣区域池化层)输入:CNN抽取的图像特征+目标候选框
计算过程:假设图像特征输出为$4\times 4$,选择一个位于左上角$3\times 3$的目标候选框,然后根据目标候选框截取图像特征,最后进行固定输出维度$2\times 2$的最大池化计算
8.3 Faster R-CNN
Faster R-CNN网络结构:
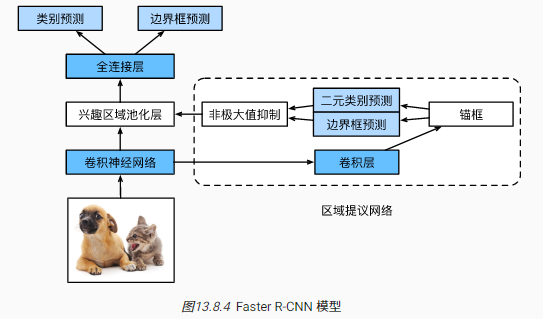
Faster R-CNN的改进:提出RPN(region proposal network)网络替代之前复杂的目标候选框的搜索过程,在保证目标检测精度的同时,减少目标候选框的生成量
RPN(区域提议网络)的计算过程 :
- 通过卷积层变换CNN网络所得的图像特征输出
- 以特征图的每个像素为中心,根据不同的尺寸和宽高比生成锚框
- 针对锚框进行二元类别预测(是否包含目标)和边界框(偏移量)预测
- 针对预测包含目标的候选边界框进行修正,然后借助非极大值抑制移除相似结果
- RPN网络的最终输出为精挑细选后的目标候选框
Faster R-CNN的损失函数:在原有目标检测中的类别和边界框预测的损失函数基础上,增加了RPN网络中针对锚框的二元类别和边界框预测的损失函数。最终用一套网络结构统一了目标检测的流程(端到端,统一训练)
8.4 Mask R-CNN
Mask R-CNN网络结构:
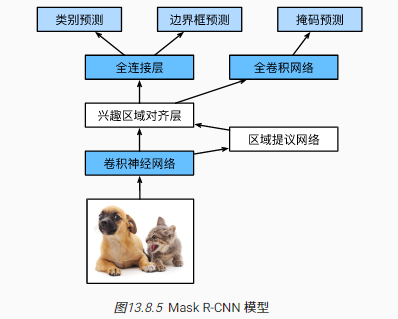
Mask R-CNN的改进:有时目标检测的标注会包含目标的像素级位置信息,所以Mask R-CNN提出了RoI Align层以取代Faster R-CNN的RoI pooling层用于更好地保留特征图上的空间信息,从而更适于像素级预测
RoI pooling(兴趣区域对齐层)计算过程:
- 输入依然为CNN网络抽取的图像特征+候选目标框
- 当特征图经过缩放类操作后,继续保持坐标为整型会导致匹配不精确的问题,所以应该构建浮点型坐标,同时还要借助双线性插值(bilinear interpolation)以计算特征图中浮点型坐标对应的像素值。
- 借助第2步,RoI pooling实现了对图像像素级特征信息的保留,最终RoI pooling层的输出还会通过一个全卷积网络预测目标的像素级位置

8.5 补充-YOLO系列
R-CNN系列都属于two-stage目标检测算法,相比于two-stage算法,one-stage算法不再进行候选目标框的生成过程,而是直接输出物体的预测类别和位置坐标,所以速度更快,但是精度也有所降低。YOLO v1是第一个one-stage的深度学习检测算法。
YOLO v1的主要步骤:
- 对输入图像进行网格化切分,借助预训练模型抽取图像特征
- 对于每一个网格,进行类别与边框的预测并计算置信度
- 通过设定阈值和NMS(非极大值抑制)去除冗余窗口
YOLO v2引入了联合训练算法(引入两种数据集分别进行分类和位置预测的学习)、批量归一化(BN)、高分辨率图像微调、预设尺寸组的锚框、多尺度图像训练等技巧,在精准度和运行效率方面均有显著提高
YOLO v3更新了更优质的预训练模型、引入来自FPN模型的多尺度预测、修改了分类损失函数;YOLO v4继续更新预训练模型,并且对超参数进行精细调整,同时引入了各种正则化、数据增强等技巧;YOLO v5在确保精度的情况下,对模型进行轻量化处理
此处只是简述相关特性,进阶阅读可参考YOLO算法综述或论文原文
8.6 补充-目标检测相关总结与拓展
目标检测发展史(截至20210701):
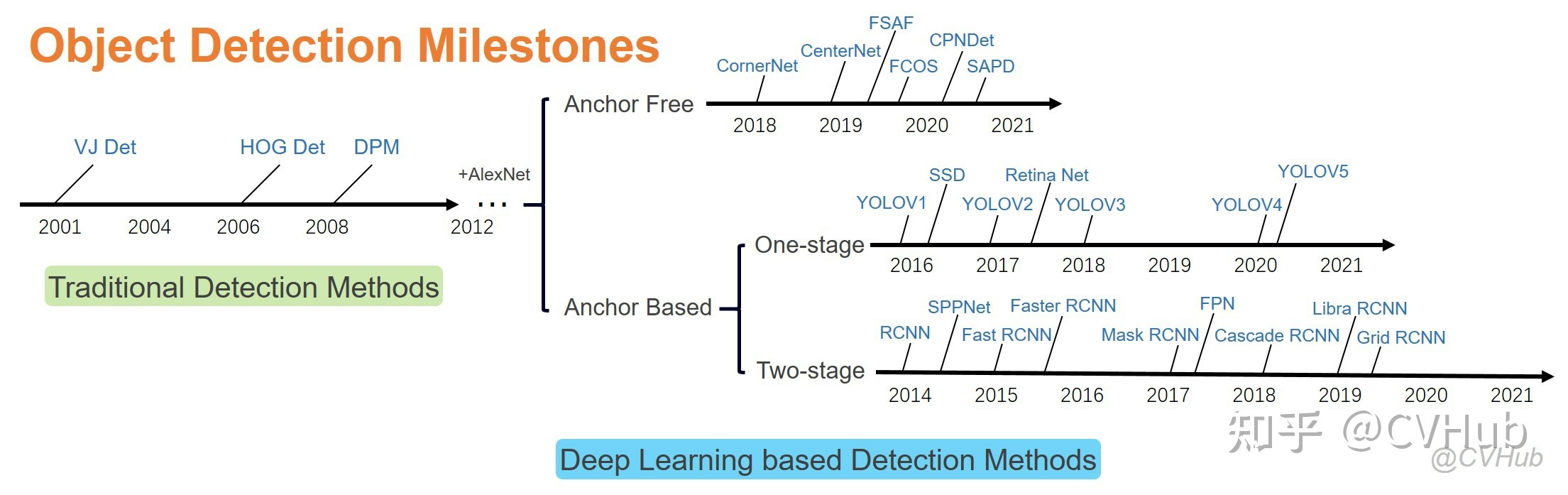
评估指标补充说明:
- AP值:PR(Precision和Recall)曲线下的面积,描述的是一种平均召准率
- mAP:多个类别的AP值的平均
- FPS:模型一秒钟能检测图片的数量
以VOC-07数据集为测试集,验证指标为mAP,各模型性能表示大致如下:
| 年份 | 模型 | 速度FPS | 精度mAP |
|---|---|---|---|
| 2014 | RCNN | 0.071 | 58.5% |
| 2015 | Fast RCNN | 0.5 | 69.9% |
| 2015 | Faster RCNN | 5 | 73.2% |
| 2016 | YOLO v1 | 21 | 66.4% |
| 2016 | SSD | 59 | 74.3% |
| 2017 | YOLO v2 | 67 | 76.8% |
拓展阅读:
目标检测概述(20200701) 目标检测相关github项目汇总
9 语义分割和数据集
相比于目标检测,语义分割需要标注和预测更精细的像素级边框

注意区分
- 图像分割:不关注语义和标签,通常利用像素间的相关性
- 实例分割:在语义分割的基础上,需要继续识别分割同一语义的不同实例
语义分割常用数据集:Pascal VOC2012
语义分割常见应用:背景虚化、路面分割
原书中还有部分关于此数据集的读取和简单使用代码,本笔记对此暂略
注意:为了确保像素的一一对应,输入图像会被随机裁剪为固定尺寸而不是缩放
10 转置卷积
11 全卷积网络
全卷积网络(fully convolutional network,FCN)的计算步骤:
- 使用卷积神经网络抽取图像特征
- 通过1×1卷积层将通道数变换为类别个数
- 通过转置卷积层将特征图的高和宽变换为输入图像的尺寸
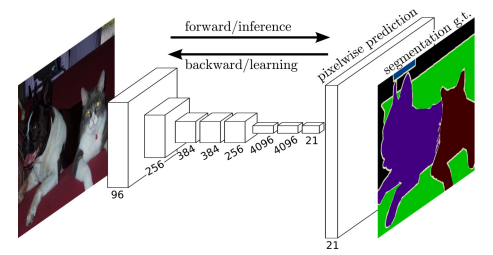
全卷积网络实现了像素级的分类,常用于语义分割等领域。双线性插值作为一种常见的上采样方法 ,常用于转置卷积层的初始化。
12 风格迁移
风格迁移(style transfer)能将一个图像中的风格应用在另一图像中

一个典型的风格迁移模型:
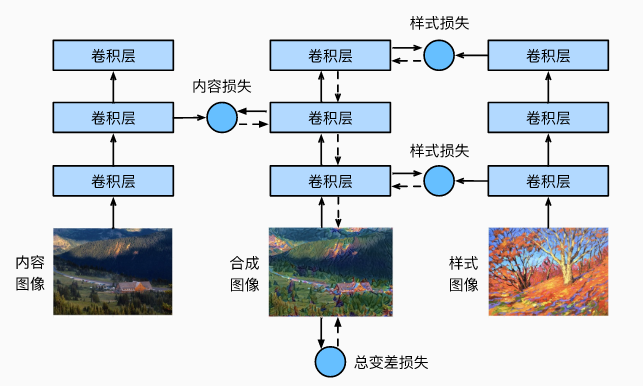
上图是一个基于CNN的三层神经网络,第二层输出内容特征,第一层和第三层输出风格特征。其中实线箭头部分表示前向传播过程,虚线箭头部分表示反向传播过程。
整个模型的损失函数主要由以下三部分组成:
内容损失,最终合成图像和原始图像的内容需要尽可能一致 直接计算平方误差,用于描述内容特征差异
风格损失,最终合成图像和风格图像的风格需要尽可能接近
根据输入构建gram矩阵,然后计算平方误差,用于表达风格特征差异
- 全变分损失,最终合成图像的噪点需要尽可能少(邻近像素尽可能相似) 累积邻近像素值间的绝对差异,用于描述图像的噪声情况
补充:实际进行风格迁移时,神经网络的层数主要依赖于具体的预训练模型,但一般来说层数都会比较多,此时的风格损失可以选择更多的层输出以尽可能捕捉到不同层次的风格,而内容损失则可以根据需求选择不同深度的层输出,一般来说越深的层对原始图像的扰动越大,最终的合成图像也越抽象。
13 实战 Kaggle 比赛:图像分类 (CIFAR-10)
CIFAR-10是计算机视觉领域中的一个重要的数据集。在Kaggle比赛中训练集包含5w张图片,测试集30w张图片(实际测试只用了1w张)。数据集涵盖10个类别:飞机、汽车、鸟类、猫、鹿、狗、青蛙、马、船和卡车。

PyTorch代码实现baseline:
import collections
import math
import os
import shutil
import pandas as pd
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
#@save
d2l.DATA_HUB['cifar10_tiny'] = (d2l.DATA_URL + 'kaggle_cifar10_tiny.zip',
'2068874e4b9a9f0fb07ebe0ad2b29754449ccacd')
# 如果你使用完整的Kaggle竞赛的数据集,设置demo为False
demo = True
if demo:
data_dir = d2l.download_extract('cifar10_tiny')
else:
data_dir = '../data/cifar-10/'
#@save
def read_csv_labels(fname):
"""读取fname来给标签字典返回一个文件名"""
with open(fname, 'r') as f:
# 跳过文件头行(列名)
lines = f.readlines()[1:]
tokens = [l.rstrip().split(',') for l in lines]
return dict(((name, label) for name, label in tokens))
labels = read_csv_labels(os.path.join(data_dir, 'trainLabels.csv'))
print('# 训练样本 :', len(labels))
print('# 类别 :', len(set(labels.values())))
#@save
def copyfile(filename, target_dir):
"""将文件复制到目标目录"""
os.makedirs(target_dir, exist_ok=True)
shutil.copy(filename, target_dir)
#@save
def reorg_train_valid(data_dir, labels, valid_ratio):
"""将验证集从原始的训练集中拆分出来"""
# 训练数据集中样本最少的类别中的样本数
n = collections.Counter(labels.values()).most_common()[-1][1]
# 验证集中每个类别的样本数
n_valid_per_label = max(1, math.floor(n * valid_ratio))
label_count = {}
for train_file in os.listdir(os.path.join(data_dir, 'train')):
label = labels[train_file.split('.')[0]]
fname = os.path.join(data_dir, 'train', train_file)
copyfile(fname, os.path.join(data_dir, 'train_valid_test',
'train_valid', label))
if label not in label_count or label_count[label] < n_valid_per_label:
copyfile(fname, os.path.join(data_dir, 'train_valid_test',
'valid', label))
label_count[label] = label_count.get(label, 0) + 1
else:
copyfile(fname, os.path.join(data_dir, 'train_valid_test',
'train', label))
return n_valid_per_label
#@save
def reorg_test(data_dir):
"""在预测期间整理测试集,以方便读取"""
for test_file in os.listdir(os.path.join(data_dir, 'test')):
copyfile(os.path.join(data_dir, 'test', test_file),
os.path.join(data_dir, 'train_valid_test', 'test',
'unknown'))
def reorg_cifar10_data(data_dir, valid_ratio):
"""整合封装之前定义的三个函数"""
labels = read_csv_labels(os.path.join(data_dir, 'trainLabels.csv'))
reorg_train_valid(data_dir, labels, valid_ratio)
reorg_test(data_dir)
# 设置模型基本参数
batch_size = 32 if demo else 128
valid_ratio = 0.1
reorg_cifar10_data(data_dir, valid_ratio)
# 图像增广
transform_train = torchvision.transforms.Compose([
# 在高度和宽度上将图像放大到40像素的正方形
torchvision.transforms.Resize(40),
# 随机裁剪出一个高度和宽度均为40像素的正方形图像,
# 生成一个面积为原始图像面积0.64到1倍的小正方形,
# 然后将其缩放为高度和宽度均为32像素的正方形
torchvision.transforms.RandomResizedCrop(32, scale=(0.64, 1.0),
ratio=(1.0, 1.0)),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
# 标准化图像的每个通道
torchvision.transforms.Normalize([0.4914, 0.4822, 0.4465],
[0.2023, 0.1994, 0.2010])])
transform_test = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.4914, 0.4822, 0.4465],
[0.2023, 0.1994, 0.2010])])
# 读取训练集、验证集、测试集
train_ds, train_valid_ds = [torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'train_valid_test', folder),
transform=transform_train) for folder in ['train', 'train_valid']]
valid_ds, test_ds = [torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'train_valid_test', folder),
transform=transform_test) for folder in ['valid', 'test']]
# 构建数据生成器
train_iter, train_valid_iter = [torch.utils.data.DataLoader(
dataset, batch_size, shuffle=True, drop_last=True)
for dataset in (train_ds, train_valid_ds)]
valid_iter = torch.utils.data.DataLoader(valid_ds, batch_size,
shuffle=False,drop_last=True)
test_iter = torch.utils.data.DataLoader(test_ds, batch_size,
shuffle=False,drop_last=False)
# 定义网络结构:ResNet18
def get_net():
num_classes = 10
net = d2l.resnet18(num_classes, 3)
return net
# 定义损失函数
loss = nn.CrossEntropyLoss(reduction="none")
# 定义训练过程
def train(net, train_iter, valid_iter, num_epochs, lr, wd,
devices, lr_period, lr_decay):
trainer = torch.optim.SGD(net.parameters(), lr=lr, momentum=0.9,
weight_decay=wd) # 动量法 + 权重衰减
scheduler = torch.optim.lr_scheduler.StepLR(trainer, lr_period, lr_decay) # 学习速率随着迭代周期逐渐衰减,有助于最终的收敛
num_batches, timer = len(train_iter), d2l.Timer()
legend = ['train loss', 'train acc']
if valid_iter is not None:
legend.append('valid acc')
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=legend)
net = nn.DataParallel(net, device_ids=devices).to(devices[0])
for epoch in range(num_epochs):
net.train()
metric = d2l.Accumulator(3)
for i, (features, labels) in enumerate(train_iter):
timer.start()
l, acc = d2l.train_batch_ch13(net, features, labels,
loss, trainer, devices)
metric.add(l, acc, labels.shape[0])
timer.stop()
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(metric[0] / metric[2], metric[1] / metric[2],
None))
if valid_iter is not None:
valid_acc = d2l.evaluate_accuracy_gpu(net, valid_iter)
animator.add(epoch + 1, (None, None, valid_acc))
scheduler.step()
measures = (f'train loss {metric[0] / metric[2]:.3f}, '
f'train acc {metric[1] / metric[2]:.3f}')
if valid_iter is not None:
measures += f', valid acc {valid_acc:.3f}'
print(measures + f'\n{metric[2] * num_epochs / timer.sum():.1f}'
f' examples/sec on {str(devices)}')
# 开始训练
devices, num_epochs, lr, wd = d2l.try_all_gpus(), 20, 2e-4, 5e-4
lr_period, lr_decay, net = 4, 0.9, get_net() # 每隔4个epoch,学习速率降低10%
train(net, train_iter, valid_iter, num_epochs, lr, wd, devices, lr_period,
lr_decay)
# 调参后用所有带标注数据重新训练
net, preds = get_net(), []
train(net, train_valid_iter, None, num_epochs, lr, wd, devices, lr_period,
lr_decay)
# 测试集结果保存,用于提交
for X, _ in test_iter:
y_hat = net(X.to(devices[0]))
preds.extend(y_hat.argmax(dim=1).type(torch.int32).cpu().numpy())
sorted_ids = list(range(1, len(test_ds) + 1))
sorted_ids.sort(key=lambda x: str(x))
df = pd.DataFrame({'id': sorted_ids, 'label': preds})
df['label'] = df['label'].apply(lambda x: train_valid_ds.classes[x])
df.to_csv('submission.csv', index=False)
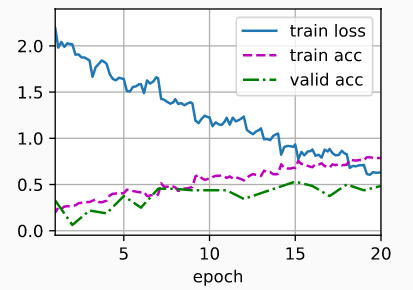
14 实战 Kaggle 比赛:狗的品种识别(ImageNet Dogs)
Kaggle基于ImageNet子集,举办了识别狗的品种比赛 。相关数据集包含1w多张图片,涵盖了120个品种。

PyTorch代码实现baseline:
import os
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
#@save
d2l.DATA_HUB['dog_tiny'] = (d2l.DATA_URL + 'kaggle_dog_tiny.zip',
'0cb91d09b814ecdc07b50f31f8dcad3e81d6a86d')
# 如果你使用Kaggle比赛的完整数据集,请将下面的变量更改为False
demo = True
if demo:
data_dir = d2l.download_extract('dog_tiny')
else:
data_dir = os.path.join('..', 'data', 'dog-breed-identification')
# 读取训练数据标签、拆分验证集并整理训练集
def reorg_dog_data(data_dir, valid_ratio):
labels = d2l.read_csv_labels(os.path.join(data_dir, 'labels.csv'))
d2l.reorg_train_valid(data_dir, labels, valid_ratio)
d2l.reorg_test(data_dir)
batch_size = 32 if demo else 128
valid_ratio = 0.1
reorg_dog_data(data_dir, valid_ratio)
# 图像增广
transform_train = torchvision.transforms.Compose([
# 随机裁剪图像,所得图像为原始面积的0.08到1之间,高宽比在3/4和4/3之间。
# 然后,缩放图像以创建224x224的新图像
torchvision.transforms.RandomResizedCrop(224, scale=(0.08, 1.0),
ratio=(3.0/4.0, 4.0/3.0)),
torchvision.transforms.RandomHorizontalFlip(),
# 随机更改亮度,对比度和饱和度
torchvision.transforms.ColorJitter(brightness=0.4,
contrast=0.4,
saturation=0.4),
# 添加随机噪声
torchvision.transforms.ToTensor(),
# 标准化图像的每个通道
torchvision.transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
transform_test = torchvision.transforms.Compose([
torchvision.transforms.Resize(256),
# 从图像中心裁切224x224大小的图片
torchvision.transforms.CenterCrop(224),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
# 读取整理后的数据集(包含原始图像)
train_ds, train_valid_ds = [torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'train_valid_test', folder),
transform=transform_train) for folder in ['train', 'train_valid']]
valid_ds, test_ds = [torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'train_valid_test', folder),
transform=transform_test) for folder in ['valid', 'test']]
# 构建数据迭代器
train_iter, train_valid_iter = [torch.utils.data.DataLoader(
dataset, batch_size, shuffle=True, drop_last=True)
for dataset in (train_ds, train_valid_ds)]
valid_iter = torch.utils.data.DataLoader(valid_ds, batch_size,
shuffle=False,drop_last=True)
test_iter = torch.utils.data.DataLoader(test_ds, batch_size,
shuffle=False,drop_last=False)
# 微调预训练模型-ResNet34
def get_net(devices):
finetune_net = nn.Sequential()
finetune_net.features = torchvision.models.resnet34(pretrained=True)
# 定义一个新的输出网络,共有120个输出类别
finetune_net.output_new = nn.Sequential(nn.Linear(1000, 256),
nn.ReLU(),
nn.Linear(256, 120))
# 将模型参数分配给用于计算的CPU或GPU
finetune_net = finetune_net.to(devices[0])
# 冻结参数
for param in finetune_net.features.parameters():
param.requires_grad = False
return finetune_net
# 构建损失函数
loss = nn.CrossEntropyLoss(reduction='none')
def evaluate_loss(data_iter, net, devices):
l_sum, n = 0.0, 0
for features, labels in data_iter:
features, labels = features.to(devices[0]), labels.to(devices[0])
outputs = net(features)
l = loss(outputs, labels)
l_sum += l.sum()
n += labels.numel()
return (l_sum / n).to('cpu')
# 定义训练过程
def train(net, train_iter, valid_iter, num_epochs,
lr, wd, devices,lr_period, lr_decay):
# 只训练小型自定义输出网络
net = nn.DataParallel(net, device_ids=devices).to(devices[0])
trainer = torch.optim.SGD((param for param in net.parameters()
if param.requires_grad), lr=lr,
momentum=0.9, weight_decay=wd)
scheduler = torch.optim.lr_scheduler.StepLR(trainer, lr_period
, lr_decay)
num_batches, timer = len(train_iter), d2l.Timer()
legend = ['train loss']
if valid_iter is not None:
legend.append('valid loss')
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=legend)
for epoch in range(num_epochs):
metric = d2l.Accumulator(2)
for i, (features, labels) in enumerate(train_iter):
timer.start()
features,labels = features.to(devices[0]),labels.to(devices[0])
trainer.zero_grad()
output = net(features)
l = loss(output, labels).sum()
l.backward()
trainer.step()
metric.add(l, labels.shape[0])
timer.stop()
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(metric[0] / metric[1], None))
measures = f'train loss {metric[0] / metric[1]:.3f}'
if valid_iter is not None:
valid_loss = evaluate_loss(valid_iter, net, devices)
animator.add(epoch + 1, (None, valid_loss.detach().cpu()))
scheduler.step()
if valid_iter is not None:
measures += f', valid loss {valid_loss:.3f}'
print(measures + f'\n{metric[1] * num_epochs / timer.sum():.1f}'
f' examples/sec on {str(devices)}')
# 设定参数,开始训练
devices, num_epochs, lr, wd = d2l.try_all_gpus(), 10, 1e-4, 1e-4
lr_period, lr_decay, net = 2, 0.9, get_net(devices)
train(net, train_iter, valid_iter, num_epochs, lr, wd, devices, lr_period,
lr_decay)
# 调参后用所有带标注数据重新训练
net = get_net(devices)
train(net, train_valid_iter, None, num_epochs, lr, wd, devices, lr_period,
lr_decay)
# 测试集结果保存,用于提交
preds = []
for data, label in test_iter:
output = torch.nn.functional.softmax(net(data.to(devices[0])), dim=0)
preds.extend(output.cpu().detach().numpy())
ids = sorted(os.listdir(
os.path.join(data_dir, 'train_valid_test', 'test', 'unknown')))
with open('submission.csv', 'w') as f:
f.write('id,' + ','.join(train_valid_ds.classes) + '\n')
for i, output in zip(ids, preds):
f.write(i.split('.')[0] + ',' + ','.join(
[str(num) for num in output]) + '\n')