中文标题:标注分歧的处理:超越主观认知的多数投票法
英文标题:Dealing with Disagreements: Looking Beyond the Majority Vote in Subjective Annotations
发布平台:TACL
Transactions of the Association for Computational Linguistics
发布日期:2022-01-31
引用量(非实时):106
DOI:10.1162/tacl_a_00449
作者:Aida Mostafazadeh Davani, Mark Díaz, Vinodkumar Prabhakaran
文章类型:journalArticle
品读时间:2023-06-17 16:14
1 文章萃取
1.1 核心观点
- 本文提出了一种基于多任务学习框架的训练方式(把每个标注者的标注结果看作一种预测任务,不同任务间共享模型的学习表示),处理标注分歧问题;相比于传统方法,此策略能保留个体和集体的两种视角,并在实验分析中实现更好地性能表现;此外,本文提出了一种量化模型不确定性的可解释性方法,有助于对模型的内部逻辑理解,梳理模型在现实环境下部署时所面临的局限性
1.2 综合评价
- 本文提出的多任务学习模型思路比较简单,最终效果也只是略高于Baseline,但有给出合理的解释
- 本文的背景说明和实验分析较为全面严谨,验证了多任务学习框架在解决标注分歧上的合理性和有效性
- 本文提出的预测不确定性量化方法简单有效,并且相关的数据分析思路和可视化技巧也值得借鉴
- 本文的最后对模型的不足进行了坦诚而深刻的说明,也给出了很多可行的改进思路和探索方向
1.3 主观评分:⭐⭐⭐⭐⭐
2 精读笔记
2.1 背景知识
标注分歧:
- 不同标注者的标注结果可能是有认知差异的,因此标注结果就会不可避免的产生分歧
- 分歧可能来自生活经历、道德观念的不同;很多主观任务中不存在单一的“正确”答案
- 处理注释分歧问题的常见传统方法是投票法、平均法和”专家“决策
- 诸如多数投票法的聚合方法,会牺牲少数群体的特殊观点,加剧社会差异
- 两个相似的样本可能因为标注者的群体差别而导向完全不同的标注结果,增加数据噪声
背景综述:
- 对辱骂的文本检测一直是NLP研究中的一个活跃领域,有很多相关的开源数据和成熟方法;最近的研究表明这类检测算法可能存在偏见(比如认为非裔美国人更容易辱骂,将精神疾病与毒品/枪支/暴力等元素相关联),这类偏见一方面广泛存在于数据中(存在不代表合理),另一方面也可能是由于标注者本身存在的偏见影响到了下游的预测
- 从文本中检验情绪也一直是NLP研究中的一个重要领域,情绪对应的语义空间往往非常复杂,而对情绪的感知有时也需要考虑到上下文你中存在的细微差别(时间、说话者身份、性格、文化);对标注结果的粗暴聚合可能会丢失这种细微差别
标注分歧的三种来源:1. 标注的清晰度(如任务描述)2. 文本歧义 3. 标注者差异
几种处理标注分歧的思路:
- 对标注者按照标注行为进行聚类并分析,可能是一种解释标注差异的方法
- 也可以根据标注者所对应的群体特征,舍弃部分标注者在特定场景下的标注结果
- 借助信息熵或后验分布的熵,来评估标注的不确定性,筛选值得信赖的标注
- 根据标注内部的一致性,惩罚存在分歧的标注样本,或提取稳定的意见(分离噪声)
量化预测的不确定性:
- 经过Softmax函数输出的预测概率是最简单的一种方法;预测概率越接近0或1说明越确定
- MC dropout(Monte Carlo dropout)是2016年提出的一种简单评估不确定性的方法;该方法通过将dropout技巧迭代地应用到模型的每一层并计算预测输出的方差,该方差描述了预测输出的不确定性
2.2 方法说明
定义数据集D=(X,A,Y),其中X表示一组文本实例,A表示一组标注器,Y为标注结果(矩阵)
考虑一个Baseline和三种多标注器架构(集成Ensemble,多标签Multi-label,多任务Multi-task):
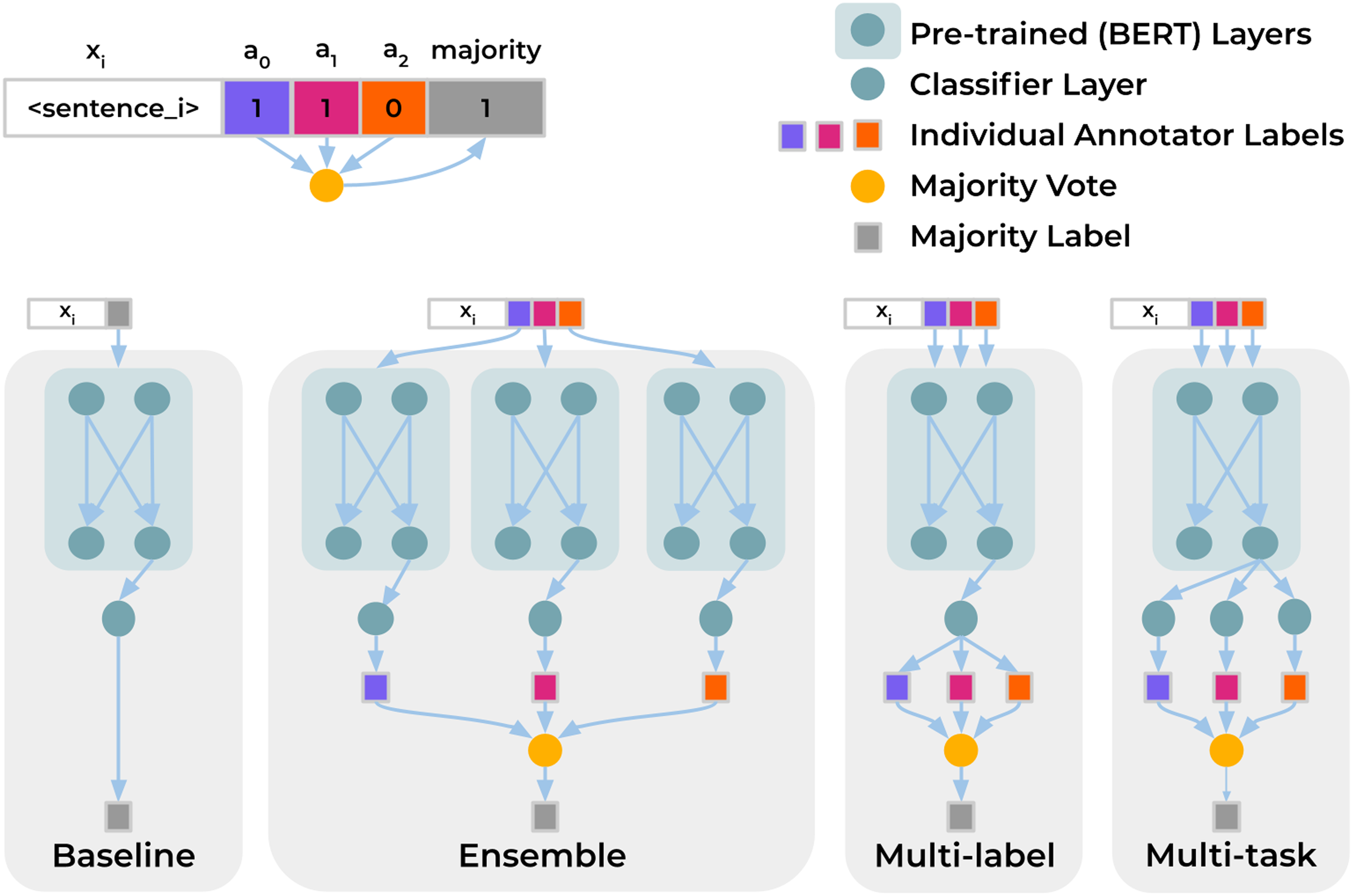
- 每个架构都使用预训练的双向Transformers编码器(BERT-base)作为BackBone
- Baseline属于单任务单分类器,预测目标为标注结果(矩阵)使用多数投票法进行聚合后的结果
- Ensemble属于多个单任务单分类器,每个模型仅针对一类标注器的标注进行训练,所有模型的预测输出按照多数投票法进行集成
- Multi-label属于单任务多分类器,模型一次性预测输出每个标注器的预测标签;由于每个标注器仅标注部分数据,因此标注结果矩阵Y中包含大量的缺失值,所以Multi-label的损失函数仅考虑不缺失的标签
- Multi-task属于多任务分类器,不同任务共享编码器层的输出(输入文本的嵌入表示),之后每个任务有担当的全连接层和softmax激活函数;与Multi-label相比, Multi-task的全连接层是根据任务独立的;与Ensemble相比, Multi-task的编码器层不是单独微调的;Multi-label的损失函数会考虑所有样本的所有标注结果
本文还提出了一种方差指标,用来描述预测的不确定性: $$\sigma^2(\overline{y_i,})=\frac{\Sigma[y_{ij}=1]\Sigma[y_{ij}=0]}{|\overline{y_i,}|^2}$$
- $\sigma^2(\overline{y_i,})$描述了第$i$个实例的预测不确定性,该指标使用标注者数量的平方进行规约
- 最终该指标的值域在0~0.25之间,0对应预测结果全为0或1的情况
2.3 实验分析
两份数据集:Gab Hate Corpus (GHC) 和 GoEmotions 数据集
- GHC数据集包含27665条来自网络的社交媒体贴,每个帖子都进行至少3次标注;共计18名标注者会判断文本是否包含仇恨言论(仇恨言论具体又细分为5种),最终共有86529个标注
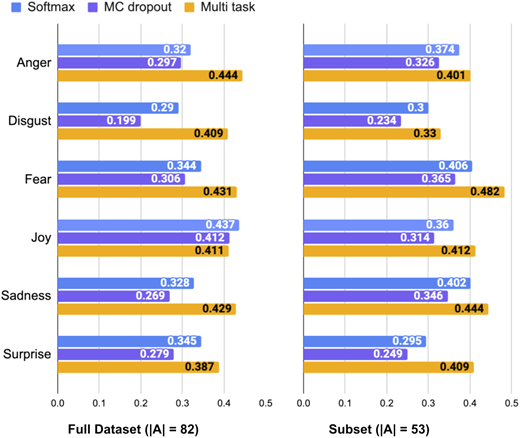
- GoEmotions 数据集包含标注了 28 种情绪的 Reddit 帖子(训练集 43410,验证集5427,测试集5426),本文实验分析仅考虑了其中6种情绪(愤怒、厌恶、恐惧、喜悦、悲伤和惊讶);本数据集共包括来自82位标注者的19441个标注
最终模型在GHC数据集上的表现如下:
| Majority Vote | Individual Labels | |||||
|---|---|---|---|---|---|---|
| Model | Precision | Recall | F1 | Precision | Recall | F1 |
| --- | --- | --- | --- | --- | --- | --- |
| Baseline | 49.53± 3.8 | 68.78± 4.4 | 57.32± 1.2 | – | – | – |
| Ensemble | 63.98± 1.1 | 46.09± 1.9 | 53.54± 1.0 | 60.92± 0.7 | 60.97± 0.8 | 60.94± 0.3 |
| Multi-label | 66.02± 2.2 | 50.16± 2.0 | 56.94± 1.0 | 67.22 ± 1.4 | 55.33± 2.0 | 60.65± 0.7 |
| Multi-task | 59.03± 0.9 | 59.98± 0.6 | 59.49± 0.2 | 63.71± 1.3 | 62.76 ± 1.5 | 63.20 ± 0.3 |
- 其中左半部分为针对聚合标签的测试表现,右半部分为针对单个标签的测试表现
- Baseline具备较高的召回率(Recall),这可能是由于标签聚合过程增强了数据内部一致性
- 综合来看Multi-task模型表现最好,其综合分数 (F1 = 59.49) 明显高于Baseline
Multi-task模型共享编码器层实现了全局视角,而单独微调的全连接层也照顾到了不同标注者的个体差异
最终模型在GoEmotions 数据集在细分类型上的表现如下:
| Full Dataset (\ | A\ | = 82) | Subset (\ | A\ | = 53) | |||
|---|---|---|---|---|---|---|---|---|
| Emotion | Baseline | Multi-task | Baseline | Multi-task | ||||
| Anger | 40.38 ± 4.4 | 39.01± 6.4 | 41.95± 6.1 | 42.75 ± 4.4 | ||||
| Disgust | 38.79 ± 3.9 | 38.31± 1.9 | 37.72 ± 2.0 | 35.77± 2.0 | ||||
| Fear | 58.96 ± 5.0 | 54.97± 6.1 | 57.68± 3.7 | 58.58 ± 2.3 | ||||
| Joy | 47.80± 2.2 | 49.53 ± 3.6 | 47.45 ± 3.1 | 46.26± 1.2 | ||||
| Sadness | 49.22± 5.2 | 50.36 ± 3.2 | 47.55± 5.4 | 48.00 ± 3.4 | ||||
| Surprise | 40.96 ± 2.9 | 38.97± 3.6 | 39.44± 5.7 | 40.22 ± 2.2 |
- Multi-task模型在预测快乐/悲伤方面优于Baseline,但其他四种情绪方面的表现却低于Baseline
- Multi-task模型在GoEmotions 数据集上的F1评分标准差明显高于刚刚的GHC数据集,初步推断可能与标注者偏斜(部分标注者的标注量很少)有关;因此本文进一步筛选了测试子集(Subset),仅考虑标注量超过1000的53位标注者,结果如上表右半部分所示
- 除此之外,模型性能表现还和类别偏斜有关,当正样本充足的情况下,Multi-task模型是明显优于Baseline的
不同情绪类型对应的预测不确定性评估:’
不同样本对应的预测不确定性分布:
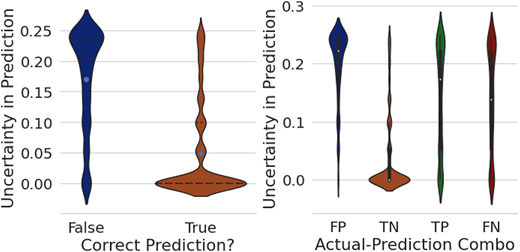
- 大部分正确预测的样本对应的不确定性都比较低,不能正确预测的样本对应的不确定性偏高
- 模型对真阴(TN)类样本的预测不确定性最低,对假阳(FP)类样本的预测不确定性最高
- 真阳(TN)类和假阴(FN)类样本的不确定性分布都存在双峰性(有的很确定,有的不确定)
其他结论:
- Multi-task与Multi-label在量化不确定性方面相似度较高,但和MC dropout方法差异较大
- 在训练耗时方面,Multi-task(22.3 mins)相比于Baseline(20.5 mins)并不会多耗费太多训练时间
- 针对Multi-task模型和Baseline的预测错误样本进行交叉分析后发现,Baseline中有22.31%的错误来自多数投票法导致的错误标注,而Multi-task中有12.19%的错误来自少数标注错误(可被多数投票法修正的错误)产生的误报
- Multi-task模型充分发挥了所有标注的价值;最终的多预测输出可以结合标注者的可信度聚合出更综合贴切的预测
- Multi-task模型可以通过融合不同视角标注器的方式进行针对性增强,也能适应不同文化/价值体系下的合理预测
局限性与改进方向:
- Multi-task模型不适合大量标注器的大型众包数据集(任务过多,微调的计算成本过高),但可考虑标注器的聚类
- 每个标注器需要有充足的标注量才能实现有效的建模,这也提高了众包平台的标注收集门槛和建模预测的成本,解决这一问题的一种可行思路是仅考虑部分高质量的标注器用于最终的预测
- 未来可考虑以脱敏合理的方式搜集标注者的数据,更全面地考虑不同标注者的认知差异和注释差异