中文标题:解耦上下文处理上下文增强语言建模
英文标题:Decoupled Context Processing for Context Augmented Language Modeling
发布平台:NeurIPS
发布日期:2022-10-11
引用量(非实时):7
DOI:10.48550/arXiv.2210.05758
作者:Zonglin Li, Ruiqi Guo, Sanjiv Kumar
关键字: #上下文增强
文章类型:preprint
品读时间:2023-07-02 0:08
1 文章萃取
1.1 核心观点
- 本文提出一种基于编码器-解码器架构的上下文增强语言模型,通过上下文编码的离线预计算和缓存生成,实现了具有上下文编码和在线语言推理分离的独特计算优势。最后,本文通过语言生成和问答实验分析,验证了这种简单架构的有效性,并表明上下文增强对模型的巨大改进
1.2 综合评价
- 解耦了上下文编码和在线语言推理,方便应用在真实场景下的落地
- 整体改动和创新点较小,实验分析部分中规中矩
1.3 主观评分:⭐⭐⭐⭐
2 精读笔记
2.1 背景知识
大模型的问题:随着模型的扩展,计算成本呈现指数级增长
一种自然的解决思路:利用外部检索的知识,减少神经网络对知识的记忆(以减少参数量)
借助上下文增强语言模型通常包括两个组成:
- 检索器,根据输入序列从外部知识中检索(向量相似项)相关的上下文
- 神经网络,集成输入序列和检索得到的外部上下文,预测输出目标序列
不过主流LLM还是通过海量非结构化知识进行预训练,使得模型权重内存储/记忆丰富的信息
外部知识源通常以键值的方式存储:
- 键主要用于相似度匹配,可以是稀疏向量(如BM25),也可以是网络某一层提取的密集嵌入
- 值则会输入到神经网络中作为信息的补充,可以是上下文对应的密集嵌入,也可以是原始文本
知识检索/相似度匹配一般使用成熟的最近邻搜索算法,比如 FAISS、ScaNN、HNSW 或 SPTAG
更多向量检索方法的横向对比可参阅向量检索研究系列文章
模型如何集成上下文信息?
- 最常用的方法是将检索结果与原始输入连接起来并联合处理
- 其次是利用某种形式的交叉注意力来进行上下文集成
2.2 方法说明
整体模型架构如下所示:
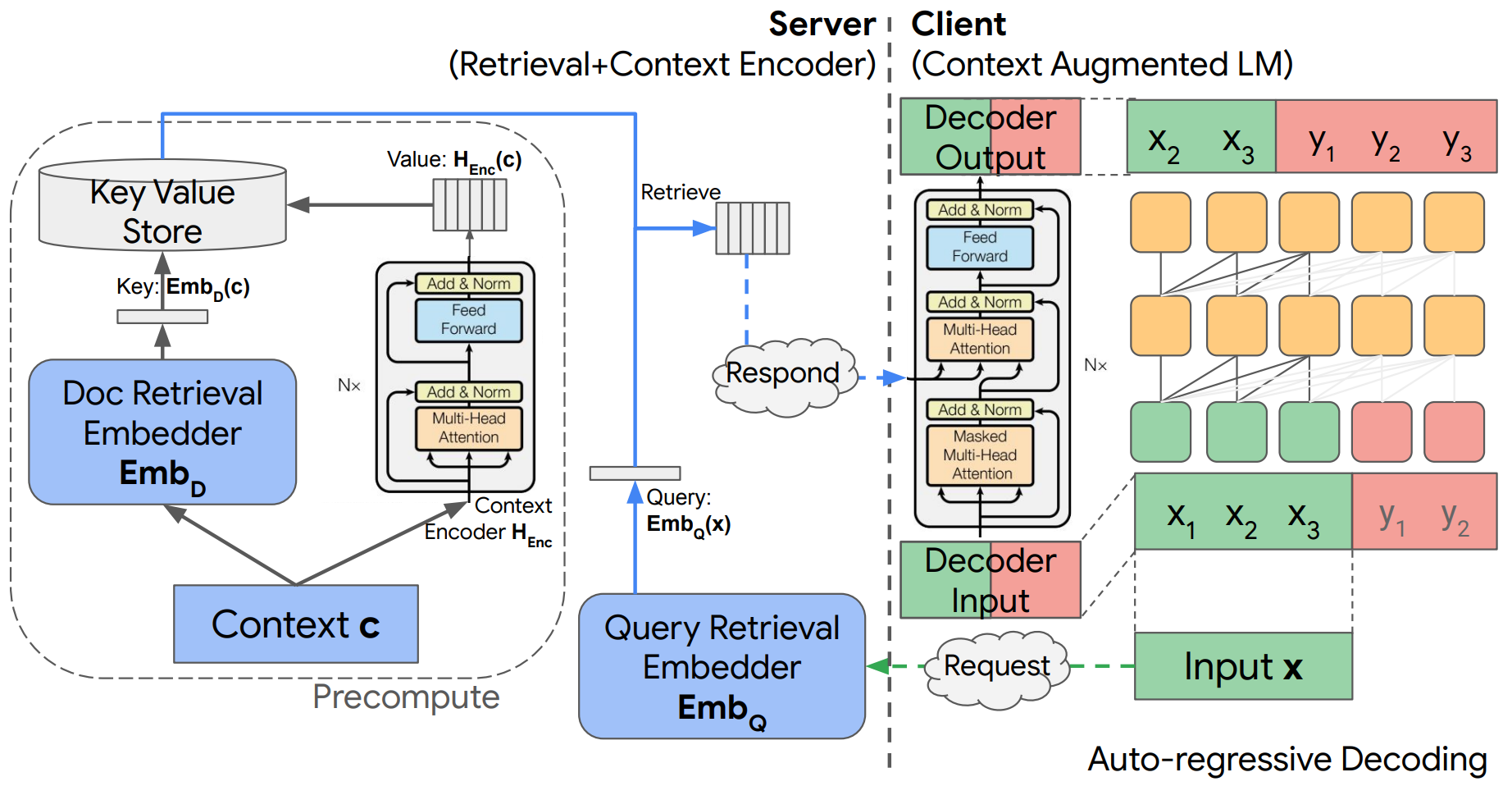
- 整体模型是标准的编码器(绿)-解码器结构(橙),而上图左侧是一套独立的上下文检索和编码机制(蓝)
- 假设客户端(Client)输入信息为$x=(x_1,x_2,...,x_n)$,该信息会发送给服务端(Server)以进行信息检索;之后检索到的上下文信息$c=(c_1,...,c_m)$会再以离线预计算的编码格式$H_{Enc}(c)$返回给客户端
- 检索过程:输入信息$x$会先转化为查询嵌入$Emb_Q(x)$,之后在数据库$D$中进行向量相似度搜索,并返回与查询嵌入内积最高的文档嵌入/索引$Emb_D(c)$,之后再将对应的上下文编码$H_{Enc}(c)$输出
- 返回的上下文编码信息会通过编码器-解码器交叉注意力机制进行集成,影响最终的预测
- 训练目标是预测下一个标记,也可以理解为文本生成:$y=(y_1,y_2,...,y_s)$;在没有外部上下文信息补充的情况下,该任务就是一个传统的自回归语言建模
其他模型细节:
- 该模型的一个特点是上下文信息的编码是提前预处理的,与在线语言模型的推理解耦
- 由于解耦,解码器和检索器都不需要存储额外的编码器参数,节省客户端存储和计算资源
- 检索器可以是任意黑盒;也支持多个上下文信息的情况(输出时直接用
concat的方式拼接)
2.3 实验分析
模型训练细节:
- 输入长度$n=448$,输出长度$s=64$,上下文信息长度为$m=512$
- 针对英文C4数据库的每篇文章,使用滑动窗口(步长为64)的方式生成训练的$x$和$y$
- 上下文序列使用相同的处理方式,并构建键值对为${Emb_Q(x):H_{Enc}(c)}$的检索数据库
- 检索器使用BM25算法;上下文增强编码器-解码器的骨干架构是mT5
最终不同模型的困惑度和问答精度对比:
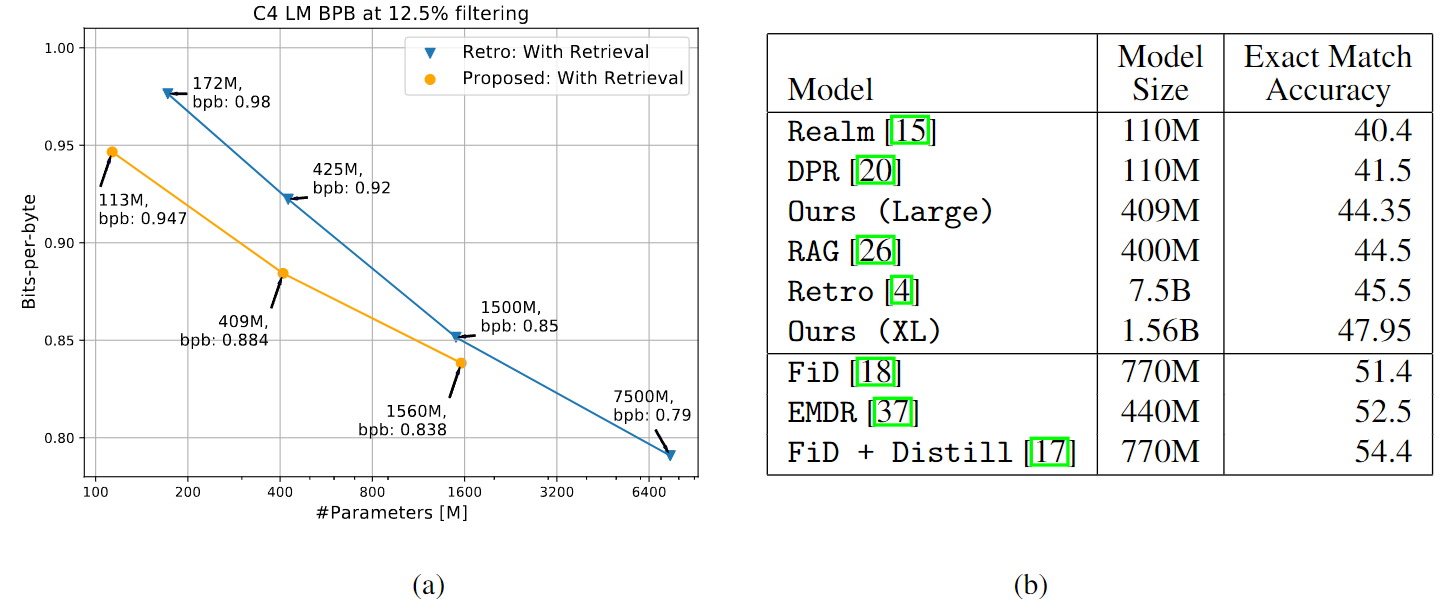
- Bits-per-byte(bpb,越低越好),这是按token长度归一化后的困惑度
- 图(a)中可发现,随机掩盖12.5%文本后,随着参数量增加,有上下文模型的困惑度降低更显著
- 图(b)中可发现,本文模型虽然部署专门为QA设计的模型,但依然展现了较为有竞争力的结果
消融实验(有上下文信息 VS 无上下文信息):
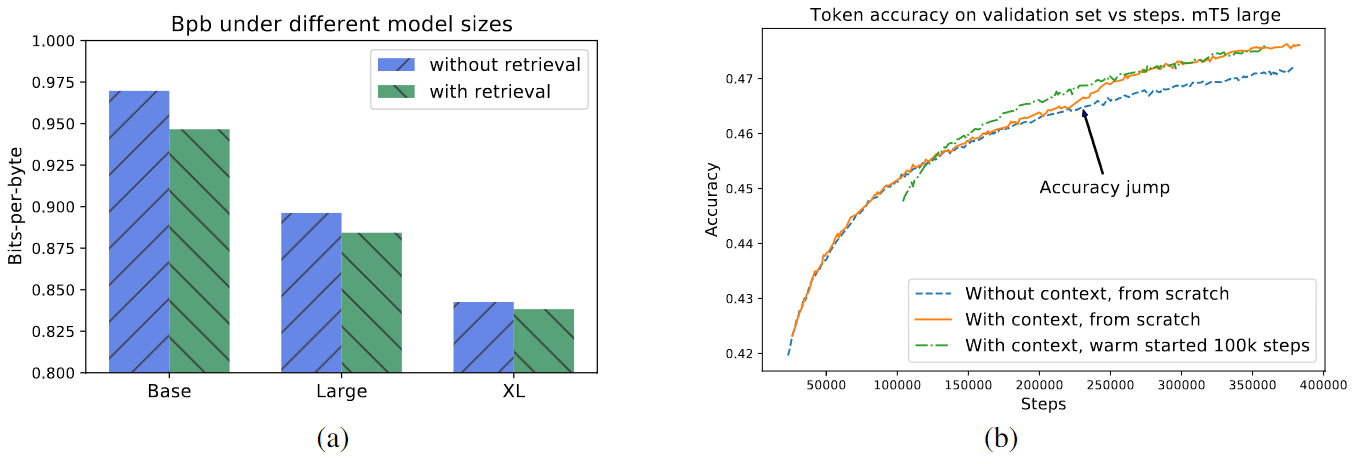
- 图(a)中可发现,对于不同参数的模型,有上下文信息的情况总是由于无上下文信息的
- 图(b)中可发现,随着训练次数的增加,有上下文信息的优势将会逐渐显现出来
不同类型用词的潜在受益分析:
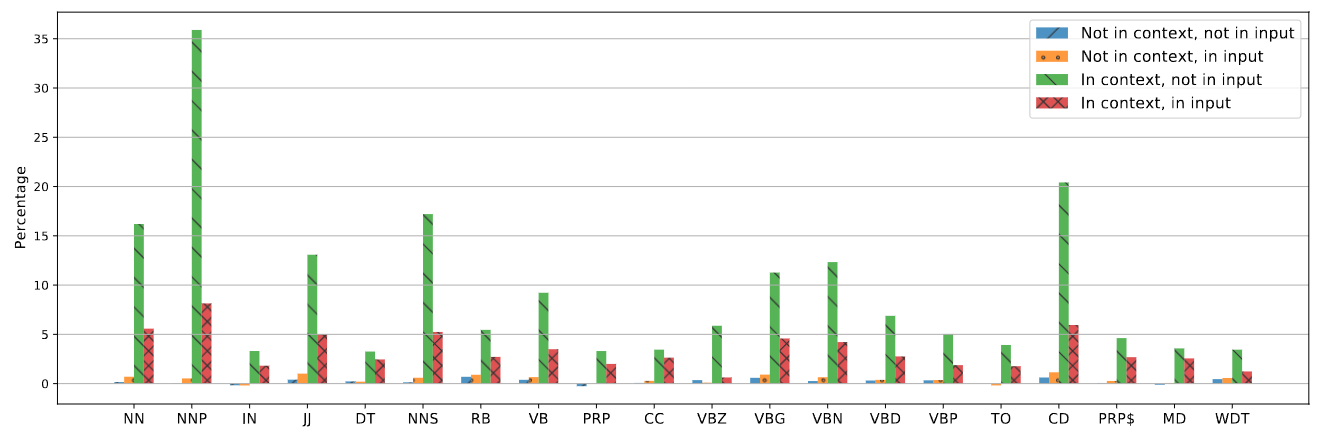
- 名词(NN,NNP,NNS,NNPS)和数字(CD)从上下文信息中受益最大
- 其次是形容词(JJ)和动词(VB,VBZ,VBG,VBN,VBD,VBP)
- 对于介词 (IN)、并列连词 (CC) 等情况,上下文信息的帮助较少
其他分析补充:
- 上下文增强模型倾向于通过将上下文信息直接传输到输出中并生成答案,本文针对这一现象也进行了分析;最终发现有76%的输出存在此类问题,但是这类情况对应的问答精度反而高于其余部分(51.5% vs 35.4%)
最后,本文还针对推理延迟进行了简单评估:
- 单个 TPUv3 内核,对所有 20 个检索到的上下文信息进行编码需要 200 ms
- 单个 TPUv2 内核推断查询嵌入大约需要8ms;用ScaNN检索20个邻接上下文需要大约12ms
- (固态硬盘)读取上下文编码大约需要1.5毫秒;端到端网络传输大约需要0.8毫秒
- 不考虑(解耦)上下文信息编码,整体耗时为66ms =(1.5 + 0.8)* 20 + 12 + 8
- 考虑上下文信息编码的话,整体耗时为266ms =(1.5 + 0.8)* 20 + 12 + 8 + 200