中文标题:基于负增强的视觉转换器(ViT)鲁棒性的理解和改进
英文标题:Understanding and Improving Robustness of Vision Transformers through Patch-based Negative Augmentation
发布平台:NeurIPS
Advances in Neural Information Processing Systems
发布日期:2022-12-06
引用量(非实时):17
DOI:10.48550/arXiv.2110.07858
作者:Yao Qin, Chiyuan Zhang, Ting Chen, Balaji Lakshminarayanan, Alex Beutel, Xuezhi Wang
文章类型:journalArticle
品读时间:2023-05-24 17:23
1 文章萃取
1.1 核心观点
ViT的鲁棒性理解:本文研究发现,面对图像块变换后人类不可识别的图像,ViT类模型展现出了极强的抗干扰能力,说明模型学到了不同于人类语义的特征信息。进一步研究表明,这类特征在分布迁移的情况下容易崩溃,即不利于模型的鲁棒性
建模改进ViT的鲁棒性:我们提出了一组基于图像块操作的负面增强视图,这些视图是对现有着重于保留语义(“积极”)增强的作品的补充,以使训练规范化远离使用这些特定的非鲁棒性特征;
鲁棒性改进的实验分析:我们展示了在20多个实验设置中,我们提出的基于补丁的负面增强视图可以始终提高ViT的鲁棒性,并且作为“积极”增强方法以及对比学习中基于批次的负样本的补充。
1.2 综合评价
- 本文通过设计基于图像块、破坏语义的转换对模型进行了“负面增强”
- 本文实验设计丰富,考虑的维度全面,确保了改进方案的可靠性
- 本文从理解到改善的思路和方法,具备一定的通用性
- 本文借鉴了对抗训练+对比学习的思路,创新性一般
1.3 主观评分:⭐⭐⭐⭐
2 精读笔记
2.1 ViT的鲁棒性理解
相比传统架构,ViT架构展现出显着的精度改进,在某些情况下也具备稳健性优势
ViT的架构特点:
- ViT在不重叠的图像块上运行,并允许在较低层之间进行长距离相互作用
- 非局部注意力可能是ViT的鲁棒性比ConvNets更好的原因之一
本文使用的模型说明:
- ViT 是Transformer用于图像处理的典型架构,通过将图像分割成一个图像块网格并进行嵌入表示,再融合位置信息和类信息后用于图像类型的预测
- 本文使用的基准ViT模型为ViT-B,模型先在ImageNet-21k(含约14百万张图片)上预训练,再在ImageNet-1k (含约1.3百万张图片)上微调;本文使用的另一个模型ViT-L参数量会更大一些
- ViT-B/16最后的数字表示具有输入的图像块大小为16×16
本文尝试理解从鲁棒性的角度理解ViT的性质:

- 基于图像块的干扰(随机旋转/乱序/背景填充)会极大地破坏图像原始语义,并使得人类无法识别
- 由上图可知,ViT类模型可以高置信度地进行类型的识别,说明ViT类模型对图像块的变换不敏感,即模型学到了不会因为图像块的变换而转移的特征信息
本文使用的验证数据集说明:
- 本文包含三个基于ImageNet偏移的鲁棒性评估基准数据集
- ImageNet-A包含来自不同于ImageNet训练分布的难分类图像
- ImageNet-C包括19种经常遇到的自然图像失真类型,每种失真具有5个严重性级别
- ImageNet-R由通过艺术处理(比如漫画)ImageNet类获得的图像组成
本文使用三种干扰策略:
- 随机打乱(shuffle)图像块:等价于干扰ViT模型的位置编码
- 随机旋转(rotate)图像块:一般选择${0,90,180,270}$这几种角度
- 随机填充(infill)图像块:使用边缘图像块填充区域内部图像块
更进一步的,ViT模型在不同数据集上应对不同类型干扰的表现如下:
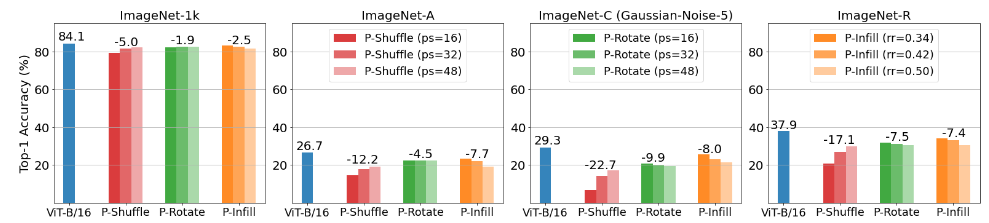
- 模型在普通测试集上存在精度下降,但下降幅度较少,验证了ViT在鲁棒性上的优秀表现。说明ViT学到了不受干扰的特征信息,并且这类特征信息是图像块级别的(无法很好地被人类理解)
- 模型在三个鲁棒性评估基准数据集下降更明显,说明这类图像块级别的特征信息反而会影响模型应对复杂场景,也影响了模型在实际应用部署时的迁移能力
因此本文希望能解决以下两个问题:
- 如何训练ViT不依赖此类特征?
- 如果减少对这些特征的依赖性,是否提高模型面对偏移分布场景下的性能?
2.2 改进ViT的鲁棒性
本小节提出了一组基于图像块的负增强鲁棒训练算法:
- 该算法通过负增强正则化训练,防止模型依赖于基于图像块级别的非鲁棒特征
- 给定输入图像$x$,通过基于图像块的干扰/变换来生成$x$的负面视图$\widetilde{x}$
- 原本的模型训练过程被称为“正向增强”,对应损失函数为交叉熵(cross-entropy):
$$L_{ce}(B;\theta)=-\frac{1}{B}\Sigma_{(x,y)\in B}ylog(softmax(f(x;\theta)))$$
- 其中$B$表示某一批次的样本集合,$\theta$表示模型参数,$y$表示真实标签
- 用$\widetilde{B}$表示负样本视图组成的集合,模型可以基于这些负样本进行“负面增强”
- 在针对负样本进行训练时,其对应损失函数为$l^2$(追求正负样本的差异最大化):
$$L_{neg}(B;\widetilde{B};\theta)=-\frac{1}{\widetilde{B}}\Sigma_{x\in B,\widetilde{x}\in \widetilde{B}}||softmax(f(x;\theta))-softmax(f(\widetilde{x};\theta))||^2$$
- 最终整体训练的损失函数可表示如下(其中$\lambda$为平衡正负增强的超参数)
$$L_{ce}(B;\theta)+\lambda \cdot L_{neg}(B;\widetilde{B};\theta)$$
除此之外,本文还实验了另一种有监督的对比损失:
- 对于样本集合$B$,将其中与样本$x_i$标签一致的样本归到一起,作为正样本集合$P_i$:
$$P_i={x_j\neq x_i, x_j\in B|y_i=y_i}$$
- 与样本$x_i$标签不一致的样本组成负样本集合,最终的对比损失可表示如下:
$$L_{cont}(B;\theta)=-\frac{1}{B}\Sigma_{x_i\in B}\frac{1}{P_i}\Sigma_{x_j\in P_i}log \frac{exp(sim(x_i,x_j)/\tau) }{\Sigma_{x_k\neq x_i, x_k\in B}exp(sim(x_i,x_k)/\tau)}$$
- 其中$\tau$是温度参数,用来平滑对比损失;$sim$常用余弦相似度,以描述样本间的距离
- 整体对比损失都在促使模型在训练过程中,尽可能拉近正样本对,分离负样本对
- 在本文中,对比损失主要用于平衡”负面增强”的损失$L_{neg}$(相当于正则项);因此实际使用时,还会将干扰前后的样本也作为负样本对,强化模型对干扰所能产生的影响的感知
2.3 鲁棒性改进的实验分析
本小节通过实验分析,充分验证本文提出的负增强鲁棒改进方法的实际效果
模型在经过改进后在不同测试集上的实验结果:
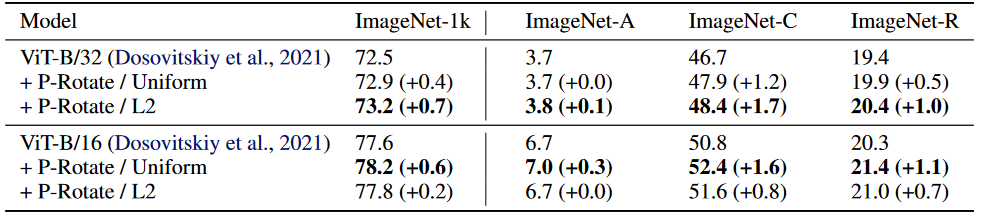
- 以上结果主要考虑了“旋转(Rotate)干扰“样本的负面增强
- 其中,Uniform表示距离平均损失,L2表示距离平方和损失
- 基于图像块的负面增强改善了模型在不同测试集上表现(鲁棒性加强)
本文方法在常用数据增强技巧的基础上仍然能起到改善模型性能的作用:
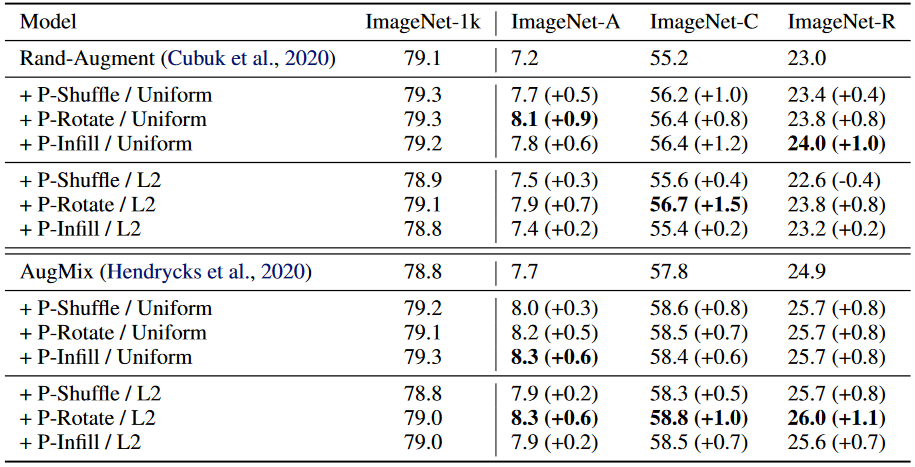
- Rand-Augment和AugMix是两种常用的数据增强方法
- Rand-Augment:基于强化学习方法对数据增强策略(每种策略都会包含操作概率和数据增强幅度)进行搜索,通过对搜索空间和搜索效率进行了优化
- AugMix:将两张图片按权重逐像素相加,同时标签向量也按相应的权重逐个元素相加,得到的新的图像和对应的标签就是一个新的样本,其中权重由beta分布产生
融入有监督的对比损失后,模型表现能够得到进一步改善:

对模型”负面增强”前后的注意力进行可视化,结果如下:
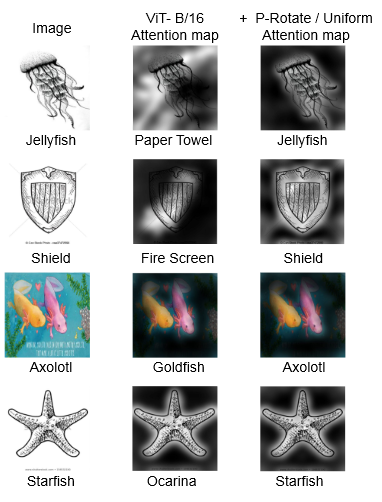
- 相比于原始ViT,改进后的模型更关注物体(符合人类的语义理解)
- “负面增强”缓解了模型对非鲁棒偏差的依赖,例如局部偏差、颜色偏差、纹理偏差等
- 在最后两个示例中,ViT虽然具备正常的注意力但是预测结果是错误的,这表明对物体的正确关注并不能保证模型确实是在依赖语义上有意义且鲁棒的特征来进行预测
其他补充:
- 原文附录B包含每个模型的超参数的选择,附录C包含不同$\lambda$取值对模型的影响
- 即使是大规模的预训练模型,使用”负面增强“训练也能改善模型的鲁棒性
- 作者后续还提供了20多种不同的实验设置,而”负面增强“表现出了一致的性能改善
总结:训练模型不仅要对不重要的数据分布更改不敏感(正向增强),还要避免模型依赖非鲁棒特征(负向增强),这两者结合在一起可以有效提高ViT的鲁棒性。