中文标题:文本分类器模型鲁棒性改进的集成方法研究
英文标题:Investigating Ensemble Methods for Model Robustness Improvement of Text Classifiers
发布平台:EMNLP
Empirical Methods in Naturel Language Processing
发布日期:2022-10-28
引用量(非实时):
DOI:10.48550/arXiv.2210.16298
作者:Jieyu Zhao, Xuezhi Wang, Yao Qin, Jilin Chen, Kai-Wei Chang
文章类型:preprint
品读时间:2023-06-01 18:39
1 文章萃取
1.1 核心观点
- 本文基于PoE方法提出了一种全新的提高鲁棒性的方法。该方法首先基于“简单”子集(偏差训练集)和弱学习器训练偏差模型,之后通过“困难”子集(偏差挑战集)找到的最优偏差模型,最后通过$PoE$方法与主模型融合,避免主模型学习到偏差特征。最终模型在额外测试集上的表现出最佳鲁棒性。
1.2 综合评价
- 方法简单有效,利用偏差模型的集成规避偏差学习
- 实验分析不够丰富,部分细节描述略显粗糙
- 最终表现效果还不错,但是方法推广性存疑
1.3 主观评分:⭐⭐⭐⭐
2 精读笔记
2.1 背景介绍
偏差特征(bias feature):适用于当前分布的标签预测,但难以推广到其他分布的特征
如何减少模型对偏差特征的过度依赖?
- 基本思想是阻止模型从“简单”示例中仅根据偏差特征进行预测的学习
- 首先训练一个偏差模型来捕获偏差特征,然后训练一个主模型与偏差模型集成
- 调整主模型的预测,以避免主模型利用到偏差模型捕获的偏差特征
偏差模型的选择:
- 一般假设弱分类器(例如,逻辑回归)可以显式捕获偏差模式
- 固定模型大小(容量)的模型可能无法捕获不同的偏差特征
- 容量过大的偏差模型可能会捕获非偏差特征,干扰主模型的预测
- 经验表明,具有不同能力的模型能更好地捕获不同可学习性的偏差
专家乘积(product-of-experts,PoE)
- 一种常用的模型鲁棒性改进方法,由Hinton在2000年提出
- 每个专家/模型$f(x|\theta)$被定义为输入空间上的一个概率模型
- PoE假设不同模型间是独立的,并通过相乘+再归一化对多模型进行组合
- 更多PoE细节可参阅论文原文以及梯度公式的推导补充
2.2 方法细节
符号定义:
- 数据集为$D={(x_i,y_i)_{i\in [1,n]}}$,其中$y_i \in {1,2,...,C}$
- 偏置模型用$h$表示,其输出为$h(x_i;\theta_b)=<b_{i1},b_{i2},...,b_{iC}>$
- 主模型用$f$表示,其输出为$f(x_i;\theta)=<p_{i1},p_{i2},...,p_{iC}>$
- 所以对于样本$i$的类别$j$,两个模型的预测概率分别为$b_{ij},q_{ij}$
- 使用PoE方法对两个模型进行融合,对应预测概率可表示如下:
$$\hat{p}_i=softmax(log(p_i)+log(b_i))$$
整体的建模流程如下所示:
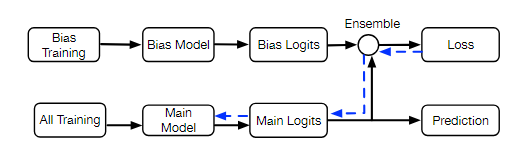
- 基于偏差数据集先进行偏差模型的训练,然后基于完整数据集训练主模型
- 两个模型通过PoE方法实现预测结果的集成,这样主模型就会直接用到偏差模型的输出
- 这样训练主模型(梯度更新)时主模型便不再会学到偏差特征,最终提高主模型的鲁棒性
本文使用两份数据集来研究不同偏差特征的影响
- FEVER是用于事实验证的数据集,每个实例包含一个论点(索赔句)和论据(判决依据);模型目标是判断论据与论点的关系,关系类型包括(支持,反驳或信息不足)三种。对应的训练模型集会使用Fever-Symmetric数据集测试鲁棒性
- MNLI是用于自然语言推理任务(Natural Language Inference,NLI)的数据集,每个实例包含一个先决前提和假设,关系类型包括(蕴涵,矛盾或中性)三种;对应的训练模型集会使用HANS数据集测试鲁棒性
构建偏差特征:
- 对于FEVER数据集,本文使用两种方式构建偏差特征:1.仅使用论据(EVIDENCE-ONLY)进行预测 2.仅使用论点(CLAIM-ONLY)进行预测
- 对于MNLI数据集,本文使用三种方式构建偏差特征:1.假设的所有token是否都出现在先决前提中(ALL-IN-P)2.假设是否是先决前提中的子序列(H-IS-SUBSEQ)3.假设中是否包含否定词(NEG-IN-H)
构建“简单”子集(偏差训练集)和“困难”子集(偏差挑战集):
- 在MNLI数据集中,ALL-IN-P和H-IS-SUBSEQ与“蕴涵”标签密切相关,而NEG-IN-H与“矛盾”标签密切相关,将满足相关性的数据作为“简单”子集;而“困难”子集则是具备相应偏差但不遵循训练数据集中偏差模式的样本(比如满足NEG-IN-H但不是“矛盾”标签的数据)
- 在FEVER数据集中,使用BERT base模型基于数据进行微调,将仅通过论点实现正确预测的样本作为(CLAIM-ONLY)的“简单”子集,而无法正常预测的样本作为“困难”子集;对于(EVIDENCE-ONLY)的情况同理可得
- 将训练集拆分为“简单”和“困难”子集主要是用来选择“最佳”偏差模型
2.3 实验分析
FEVER数据集中,不同类型偏差模型的评价结果:
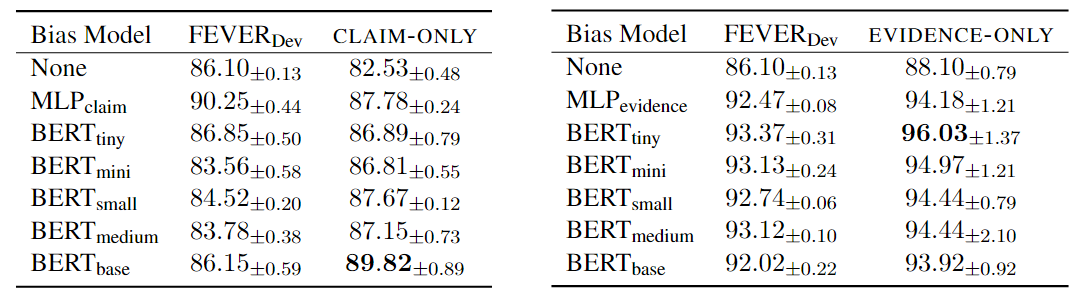
- 左子图为仅使用论点(CLAIM-ONLY)训练偏差模型,右子图为仅使用论据(EVIDENCE-ONLY)
- 每个子图的第1列表示用于训练偏差模型类型:包括多层感知器MLP和其他不同量级的BERT模型
- 每个子图的第2列表示在验证集上的表现,第3列表示在“困难”子集(偏差挑战集)上的表现
- 评价指标为准确率,两种情况的最优偏差模型分别为$BERT_{base}$和$BERT_{tiny}$
MNLI数据集中,不同类型偏差模型的评价结果:
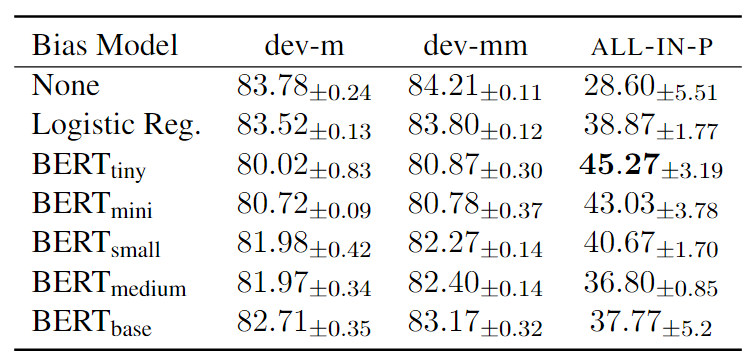
- 上图中
dev-m表示推理成立(match)的部分验证集,dev-mm表示推理不成立(mismatch)的部分验证集 - 第1列表示用于训练偏差模型的类型,包括逻辑回归模型和其他不同量级的BERT模型
- 评价指标为准确率,对于(ALL-IN-P)的情况最优偏差模型是$BERT_{tiny}$
模型鲁棒性测试结果:

- 左子图表示基于MNLI数据训练模型在最终测试集中的表现,左子图表示基于FEVER数据训练模型在最终测试集中的表现
- 其中$BERT-base$表示不融合偏差模型的基准模型;$PoE_{LogisticRge}$和$PoE_{MLP}$是两种基于融合最弱偏差模型后的性能表现;$SelfDistill$是一种基于知识蒸馏的模型融合方法(teacher-student架构);$Reweight$是一种基于样本加权(权重是偏差模型的正确率)的简单模型融合方法
- 最终发现,本文提出$PoE$方法最好。该方法基于“困难”子集(偏差挑战集)找到的最优偏差模型,之后通过$PoE$方法与主模型融合,最终的集成模型在额外测试集上的鲁棒性表现最好,远高于其他模型融合方法。