背景故事:啤酒与尿布
Aprior 算法的 3 个关键评价指标:
- 支持度(Support):商品 X 和商品 Y 同时在数据集中出现的概率
$$ Support(X,Y) = P(XY) = \frac{number(XY)}{num(All Samples)} $$ 2. 置信度(Confidence):商品 Y 出现后,商品 X 出现的概率 $$ Confidence(X \Leftarrow Y) = P(X|Y)=P(XY)/P(Y) $$ 3. 提升度(Lift):商品 X 出现的情况中,商品 Y 也出现的概率 $$ Lift(X \Leftarrow Y) = P(X|Y)/P(X) = Confidence(X \Leftarrow Y) / P(X) $$
评价指标的理解:
- 支持度高的数据不一定构成频繁项集,但支持度太低的数据肯定不构成频繁项集
- 提升度体先了 X 和 Y 间的关联关系, 提升度大于 1 则 $X \Leftarrow Y$ 是有效的强关联规则
- 用户需要自定义支持度、置信度和提升度的阈值,来筛选出最佳的关联规则
Aprior 算法计算过程示例:
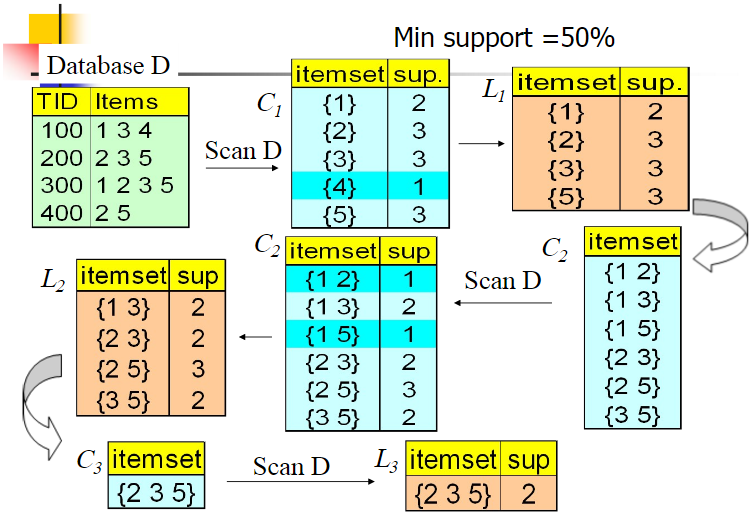
- 数据集 D 有 4 条记录,分别是134, 235, 1235和25;设置最小支持度为50%
- 遍历数据集,生成候选频繁1项集 $C_1$,然后进行剪枝(候选频繁 1 项
{4}由于支持度<50%被删除),最终的频繁 1 项集 $L_1$ 包含四个频繁 1 项:[{1},{2},{3},{5}] - 随机组合频繁 1 项集,得到候选频繁 2 项集 $C_2$,,然后进行剪枝(候选频繁 2 项
{12}和{15}由于支持度<50%被删除),最终的频繁 2 项集 $L_2$ 包含四个频繁 2 项:[{13},{23},{25},{35}] - 以此类推,最终可得到频繁 2 项集 $L_2$ 包含一个频繁 3 项:
[{235}]
Apriori 算法分析:当数据量较大时算法效率偏低
进阶算法:FP-Tree,GSP, CBA 等 #待补充