LSH(locality sensitivity Hashing,局部敏感性哈希)算法
- 一种从海量数据中进行相似性搜索的算法
- 常用于文本查重、图像识别、推荐系统和搜索引擎
以相似文档检索为例,说明 LSH 的算法过程
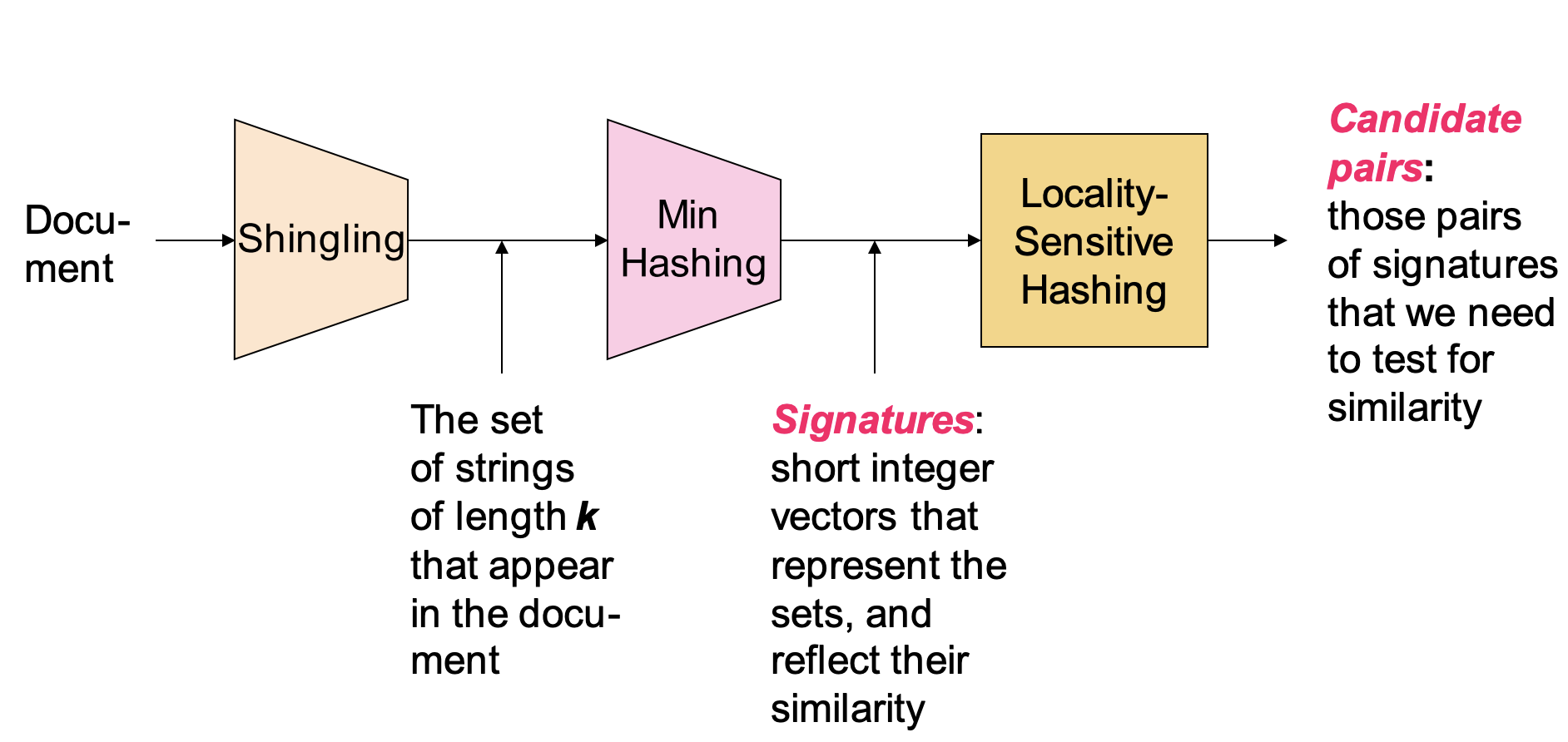
Shingling,文档进行向量化表示
- 统计 k 个文档中连续出现的 token(字符或单词)
- 按照 one_hot 的形式对文档进行向量化的矩阵表示
- 每一列表示一个文档,每一行表示文档的信息矩阵
Min-Hashing,对文档信息进行降维
- 依次对文档矩阵的每一列进行重排序
- 选择第一个非 0 行的行号作为的最小哈希值
- 重复多次,得到若干个最小哈希组成的文档矩阵
- 该矩阵的维度大幅降低,但依然包含相关性信息
最小哈希组成的文档矩阵,也被称为最小哈希 signature 矩阵
- 局部敏感性哈希,按照相似度实现文档检索
- 用哈希函数遍历文档矩阵的每一列,并映射到桶中
- 同一个桶中的文档可以作为一个候选对(Candidate Pair)
- 针对每一个候选对,分别计算 Jaccard 相似度
- 最终筛选出相似度不低于特定阈值的所有文档
分析与总结:
- LSH 是一种概率性算法,结果的准确性依赖于哈希函数的设计、距离度量方法和参数的选择(需要调参)
- LSH 非常适合处理大规模数据集,并且搜索效率很高,时间复杂度为 $O(n^{1/L})$,其中 $L$ 是哈希表的数量
- LSH 存储开销较大,并且 LSH 的结果只是一个近似最近邻,而不是精确最近邻(适合精确性要求不高的场景)
- LSH 还可以进一步优化,比如减少冗余表、压缩哈希表、优化查询效率、将哈希过程和桶查找过程进行并行化
参考: