1 分组机制
按照指定的行列取值进行分组,并按组进行计算(求和、均值、标准差等)
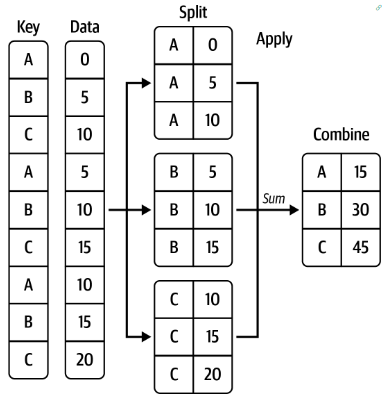
代码示例:
df = pd.DataFrame({'key1' : ['a', 'a', 'b', 'b', 'a'],
'key2' : ['one', 'two', 'one', 'two', 'one'],
'data1' : np.random.randn(5),
'data2' : np.random.randn(5)})
grouped = df['data1'].groupby(df['key1']) # 生成一个GroupBy对象
grouped.mean() # 计算每组的均值(自动过滤无法计算均值的非数值列)
means = df["data1"].groupby([df["key1"], df["key2"]]).mean() # 两层分组
for name, group in df.groupby('key1'): # GroupBy对象支持迭代
print(name)
print(group)
pieces = {name: group for name, group in df.groupby("key1")} # 分组转dict
people = pd.DataFrame(np.random.randn(5, 5),
columns=['a', 'b', 'c', 'd', 'e'],
index=['Joe', 'Steve', 'Wes', 'Jim', 'Travis'])
people.iloc[2:3, [1, 2]] = np.nan # 混杂一些缺失值
mapping = {'a': 'red', 'b': 'red', 'c': 'blue',
'd': 'blue', 'e': 'red', 'f' : 'orange'}
people.groupby(mapping, axis=1).sum() # 先映射再按照列进行聚合
people.groupby(len).sum() # 支持通过函数进行分组聚合
其他分组聚类常用技巧:
- 分组所依赖的键在分组后会转化为索引,所以多分组的聚合运算结果会是多层次索引的
- 可以通过参数
as_index=False显式地取消用于分组的键被用作索引 - 针对多层次索引,可以通过参数
level指定根据具体哪一层进行分组 - 不同分组方式(列,索引,函数,映射序列)之间可以混合使用
- 多分组的结果会是多层次索引的形式,可以使用
unstack或reset_index处理索引
2 数据聚合
常用聚合方法:size/count计数,sum求和,min/max最小值/最大值,first/last第一个/最后一个,mean均值,median中位数,prod积,any/all逻辑运算,cummin/cummax/cumsum/cumprob累积最小/最大/和/积,quantile分位数,rank次序,std/var标准差/方差,nth第N个数,ohlc开始/最高/最低/结束
对于数值型的聚合运算,会先弃置缺失值再进行
还可以使用agg方法自定义聚合函数:
grouped = df.groupby("key1")
def peak_to_peak(arr):
return arr.max() - arr.min()
grouped.agg(peak_to_peak)
grouped.agg(['mean', 'std', peak_to_peak]) # 一次性调用多个聚合函数
grouped.agg([('data1', 'mean'), ('data2', np.std)]) # 针对不同列定义不同的聚合函数
grouped.agg({'data1' : ['min', 'max'],'data2' : 'sum'}) # 使用字典进行更灵活的聚合
自定义聚合函数通常要比内置的聚合函数效率低很多
3 apply:更一般化的”拆分-处理-合并“
代码示例:
frame = pd.DataFrame({"data1": np.random.standard_normal(1000),
"data2": np.random.standard_normal(1000)})
quartiles = pd.cut(frame["data1"], 4) # cut函数将数值型转为类别数为4的类别型
def get_stats(group):
return pd.DataFrame(
{"min": group.min(), "max": group.max(),
"count": group.count(), "mean": group.mean()}
)
grouped = frame.groupby(quartiles)
grouped.apply(get_stats)
# 输出结果:
# min max count mean
# data1
# (-2.956, -1.23] data1 -2.949343 -1.230179 94 -1.658818
# data2 -3.399312 1.670835 94 -0.033333
# (-1.23, 0.489] data1 -1.228918 0.488675 598 -0.329524
# data2 -2.989741 3.260383 598 -0.002622
# (0.489, 2.208] data1 0.489965 2.200997 298 1.065727
# data2 -3.745356 2.954439 298 0.078249
# (2.208, 3.928] data1 2.212303 3.927528 10 2.644253
# data2 -1.929776 1.765640 10 0.024750
grouped.agg(["min", "max", "count", "mean"]) # 另一种等价写法
如果不希望结果的行索引是数据间隔,可以在使用
cut方法时添加参数labels=False
案例1:借助apply进行缺失填补
states = ["Ohio", "New York", "Vermont", "Florida",
"Oregon", "Nevada", "California", "Idaho"]
group_key = ["East", "East", "East", "East",
"West", "West", "West", "West"]
data = pd.Series(np.random.standard_normal(8), index=states)
data[["Vermont", "Nevada", "Idaho"]] = np.nan # 人为捏造缺失
def fill_mean(group):
return group.fillna(group.mean())
data.groupby(group_key).apply(fill_mean) # 均值填补缺失
fill_values = {"East": 0.5, "West": -1}
def fill_func(group):
return group.fillna(fill_values[group.name])
data.groupby(group_key).apply(fill_func) # 按组 依次用固定值填补缺失
案例2:分组计算加权平均值
df = pd.DataFrame({'category': ['a', 'a', 'a', 'a',
'b', 'b', 'b', 'b'],
'data': np.random.randn(8),
'weights': np.random.rand(8)})
grouped = df.groupby('category')
get_wavg = lambda g: np.average(g['data'], weights=g['weights'])
grouped.apply(get_wavg)
原文中还有蒙特卡洛模拟,分组计算相关性,分组回归等案例,此处不再赘述
4 transform:“解包”分组聚合结果
df = pd.DataFrame({'key': ['a', 'b', 'c'] * 4,
'value': np.arange(12.)})
g = df.groupby('key')['value']
def get_mean(group):
return group.mean()
g.transform(get_mean)
# 此方法会将分组计算的结果再传给原始数据(分组前的数据)
def normalize(x):
return (x - x.mean()) / x.std()
g.transform(normalize) # 直接对数据进行分组标准化
g.apply(normalize) # 另一种等价写法
(df['value'] - g.transform('mean')) / g.transform('std') # 等价写法
transform方法可以实现非常灵活、高效的向量化操作
5 透视表和交叉表
pandas中包含pivot_table函数,可以很方便地制作透视表
在计算多因子的分组计数时,使用crosstab制作交叉表会更方便
### 透视表示例
df = pd.DataFrame({"A": ["foo", "foo", "foo", "foo", "foo",
"bar", "bar", "bar", "bar"],
"B": ["one", "one", "one", "two", "two",
"one", "one", "two", "two"],
"C": ["small", "large", "large", "small",
"small", "large", "small", "small",
"large"],
"D": [1, 2, 2, 3, 3, 4, 5, 6, 7],
"E": [2, 4, 5, 5, 6, 6, 8, 9, 9]})
table = pd.pivot_table(df, values='D', index=['A', 'B'],
columns=['C'], aggfunc=np.sum)
table
# C large small
# A B
# bar one 4.0 5.0
# two 7.0 6.0
# foo one 4.0 1.0
# two NaN 6.0
### 交叉表示例
a = np.array(["foo", "foo", "foo", "foo", "bar", "bar",
"bar", "bar", "foo", "foo", "foo"], dtype=object)
b = np.array(["one", "one", "one", "two", "one", "one",
"one", "two", "two", "two", "one"], dtype=object)
c = np.array(["dull", "dull", "shiny", "dull", "dull", "shiny",
"shiny", "dull", "shiny", "shiny", "shiny"],
dtype=object)
pd.crosstab(a, [b, c], rownames=['a'], colnames=['b', 'c'])
# b one two
# c dull shiny dull shiny
# a
# bar 1 2 1 0
# foo 2 2 1 2
更多细节可参阅官方API说明:pandas.pivot_table, pandas.crosstab