1 网格搜索
网格搜索(Grid Search)会遍历给定参数空间内的所有参数组合,并选择最优的一组,相对于暴力枚举法,有点浪费时间
2 随机搜索
随机选择(Randomized Search)参数空间内的参数组合,可能有的参数组合不会被选到,效率比网格搜索高
3 贝叶斯优化
贝叶斯优化(Bayesian Optimization)是一种通用的黑盒优化算法,不需要计算梯度便可快速解决最优化问题,贝叶斯优化适合处理目标函数计算成本高或求导困难的情况。贝叶斯优化最常用的场景是超参搜索(尤其是神经网络类算法,计算成本高,超参数还多)
更多细节可参阅:贝叶斯优化
4 贝叶斯优化进阶
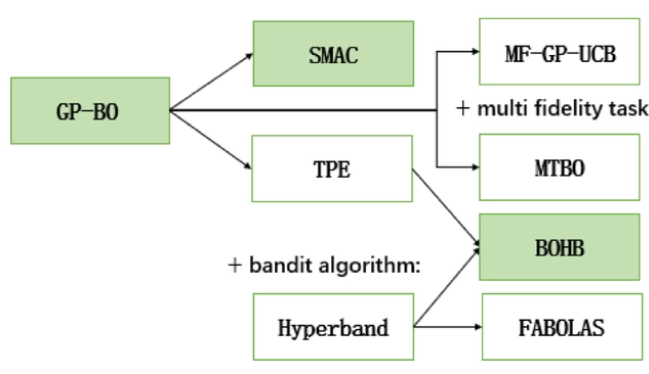 图源:
图源:- GP-BO表示基于高斯过程回归的贝叶斯优化(最常见)
- SMAC是基于随机森林的贝叶斯优化,用每棵子树的输出估计最终结果的均值和方差
- TPE在贝叶斯优化的基础上融入了树结构和Parzen,具体可参阅论文阅读-TPE算法
- Hyperband使用early stopping和Sccessive Halving算法,在给定资源预算下逐步筛选超参组合
5 其他自动调参方法
5.1 CMA-ES算法
协方差矩阵自适应进化策略算法(Covariance matrix adaptation evolution strategy,CMA-ES)是一种非线性的进化算法,可用于处理连续域中的非凸黑盒优化问题,不需要计算梯度,在2~100维的空间搜索中表现较好
CMA-ES算法的基本思路如下:根据服从协方差矩阵的多维高斯分布生成随机点,之后筛选出表现最好的$\lambda$个随机点,维护筛选结果的历史序列对多维高斯分布的参数进行平滑调整,最终的分布将逐渐逼近最优解
更多CMA-ES算法细节可参阅:进化策略算法(CMA-ES)理解,备用地址
5.2 NSGA 算法
前置知识:遗传算法
普通的多目标遗传算法:通过权重平衡不同目标,构建单一的目标函数
NSGA(Non-dominated Sorting Genetic Algorithms)
- NSGA 算法是一种基于 Pareto 最优的多目标遗传算法
- NSGA 算法使用非支配排序来对种群进行分层,进而引导优秀个体被保留的概率
- 在每一代中,算法会识别出不被任何其他个体支配的解(即 Pareto 最优解),这些解构成了第一层(front)。然后,这些解从种群中移除,对剩余的种群重复这个过程,形成第二层
- 以此类推。越靠前的分层,其中的个人越有可能被选择并进入下一代
非支配解(nondominated solutions)或 Pareto 最优解(Pareto optimal solutions)
针对多目标优化,无法在改进任何目标函数的同时不削弱至少一个其他目标函数
NSGAⅡ 算法相比于 NSGA 算法的三点改进:
- 使用了快速非支配排序法,降低了算法复杂度
- 保留精英个体并进行下一代非支配排序,增大搜索空间
- 使用拥挤度对同一级的个体进行排序,保持种群的多样性
更多 NSGA 算法细节可参阅:NSGA-II算法介绍
5.3 ASHA
ASHA(Asynchronous Successive Halving Algorithm)算法是一种将随机搜索和有原则的异步早停相结合的算法
更多ASHA细节可参阅:ASHA介绍-Massively Parallel Hyperparameter Optimization
5.4 更多启发式算法
补充:常用调参工具
skopt:小型搜索空间和良好的初始估计下效果好
Simple(x):Simple(x)和贝叶斯搜索一样,试图以尽可能少的样本进行优化,但不同的是它模拟搜索空间使用的是单形(n维三角形),而不是超立方体(n维立方体),从而将计算复杂度从n³降低到log(n),对大型搜索空间非常有用。(比较专一化的工具)
HyperOpt:主要实现了TPE贝叶斯优化,来寻找最优的模型超参,感兴趣的读者可以参阅HyperOpt入门使用示例
Ray.tune集成了多种超参优化方法,运行在Ray分布式计算框架上,拓展性强。Ray是一种高度集成的Automl框架,内容较多,我们在此只总结其结合超参优化的部分——Ray.tune
Chocolate使用通用数据库来联合执行各个任务;优势体现在它支持受约束的搜索空间和多损失函数优化(多目标优化)
GpFlowOpt使用TensorFlow在GPU上运行高斯过程任务。如果要用到贝叶斯优化且有可用的GPU计算资源,那GpFlowOpt库应该是上选。
FAR-HO在构建TensorFlow中基于梯度的超参数优化器的访问,允许在GPU或其他张量优化计算环境中进行深度学习模型的训练和超参数优化。
XcessivGUI界面,大规模模型开发、执行和集成, 优势在于能够在单个GUI界面中管理多个机器学习模型的训练、执行和评估。它包括一个贝叶斯搜索参数优化器,这个优化器支持高级别并行计算,还支持与TPOT库的集成。(任务队列结构支持多核运算及并行超参搜索)
HORD能为需要优化的黑盒模型生成一个代理函数,并用它来生成最接近理想状态的超参数组合,以减少对整个模型的评估。与Tree Parzen Estimators、SMAC和高斯过程方法相比,它始终具有更高的一致性和更低的错误率,而且这个方法特别适用于极高维数据分析。(基于paper的专一性超参优化工具)
Efficient_NAS使用参数共享来构建更高效的网络,使其适用于深度学习结构搜索。(基于Pytorch实现的Efficient Neural Architecture Search via Parameters Sharing)