中文标题:为什么基于树的模型在表格数据上仍然优于深度学习?
英文标题:Why do tree-based models still outperform deep learning on tabular data?
发布平台:NIPS
Advances in neural information processing systems
发布日期:2022-01-01
引用量(非实时):1483
DOI:10.48550/ARXIV.2207.08815
作者:Léo Grinsztajn, Edouard Oyallon, Gaël Varoquaux
文章类型:conferencePaper
品读时间:2025-01-31 19:32
1 文章萃取
1.1 核心观点
本文搜集了很多领域的优质数据集,并通过重复的筛选和清洗,构建了一个包含 45 个数据集的测试集合,并设置了严格的流程与评价方法用于对比分析树模型与深度学习。最终发现,树模型在表格数据上的表现优于深度学习
在后续的分析中,本文先从目标的不规则性,分析了两类模型在目标函数拟合上的特质;然后分别从冗余特征和特征旋转这两种干扰上入手,发现了一个关键结论:神经网络类模型由于存在对特征不变性的学习,导致其更容易受到冗余特征的干扰
1.2 综合评价
- 实验设计严谨,代码和数据开源,可复现性强
- 论文简练,表达清晰,直命主题,冗余信息少
- 对两类模型进行了深入浅出的剖析,受益匪浅
1.3 主观评分:⭐⭐⭐⭐⭐
2 精读笔记
2.1 结论:树模型在表格数据集上表现优于深度学习
实验设计:
- 严格筛选数据,排除标签偏斜、数据缺失、信息过少、样本量过少的数据集
- 最终定义了一个包含 45 个数据集的集合,数据集涵盖了不同的领域
- 树模型主要考虑三个经典模型:RandomForest,GradientBoostingTrees, XGBoost
- 深度学习主要考虑四个经典模型:MLP、Resnet、FT_Transformer、SAINT
- 对于分类/回归问题,分别用准确率/ $R^2$ 衡量模型在每类数据集上的性能
- 对于每个模型,用类似平均最小距离(ADTM)的综合指标来衡量模型表现
主要结论:对于不同类型的任务和特征,树模型的收敛速度和最终性能均高于深度学习模型
1.不同模型随着迭代次数的收敛情况(仅考虑了数值类特征)
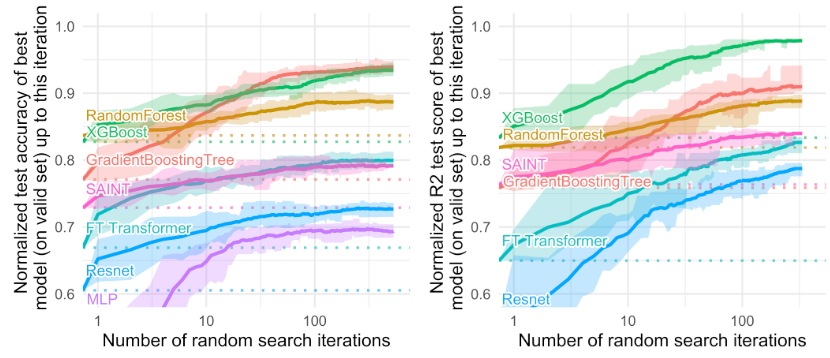 2.不同模型随着迭代次数的收敛情况(同时考虑了数值类特征和类别型特征)
2.不同模型随着迭代次数的收敛情况(同时考虑了数值类特征和类别型特征)
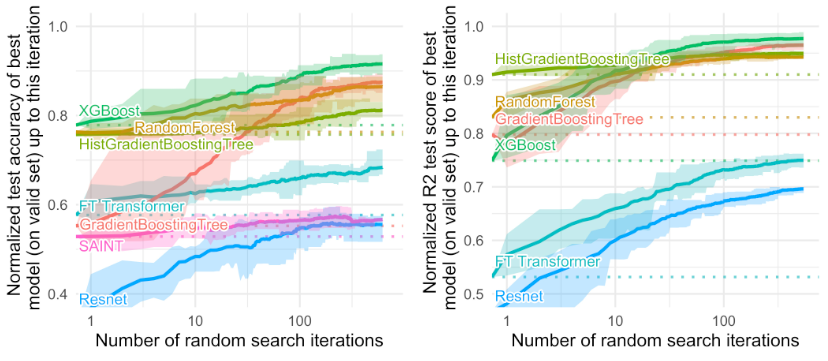
神经网络对于表格数据具备充足的表达力,但可能缺乏合理的正则化?
2.2 分析:为什么树模型的表现优于深度学习?
2.2.1 发现 1:神经网络倾向于过度平滑的解,难以拟合不规则的函数
通过高斯核平滑器对训练集的标签进行平滑后,树模型的性能下降明显而神经网络无影响:
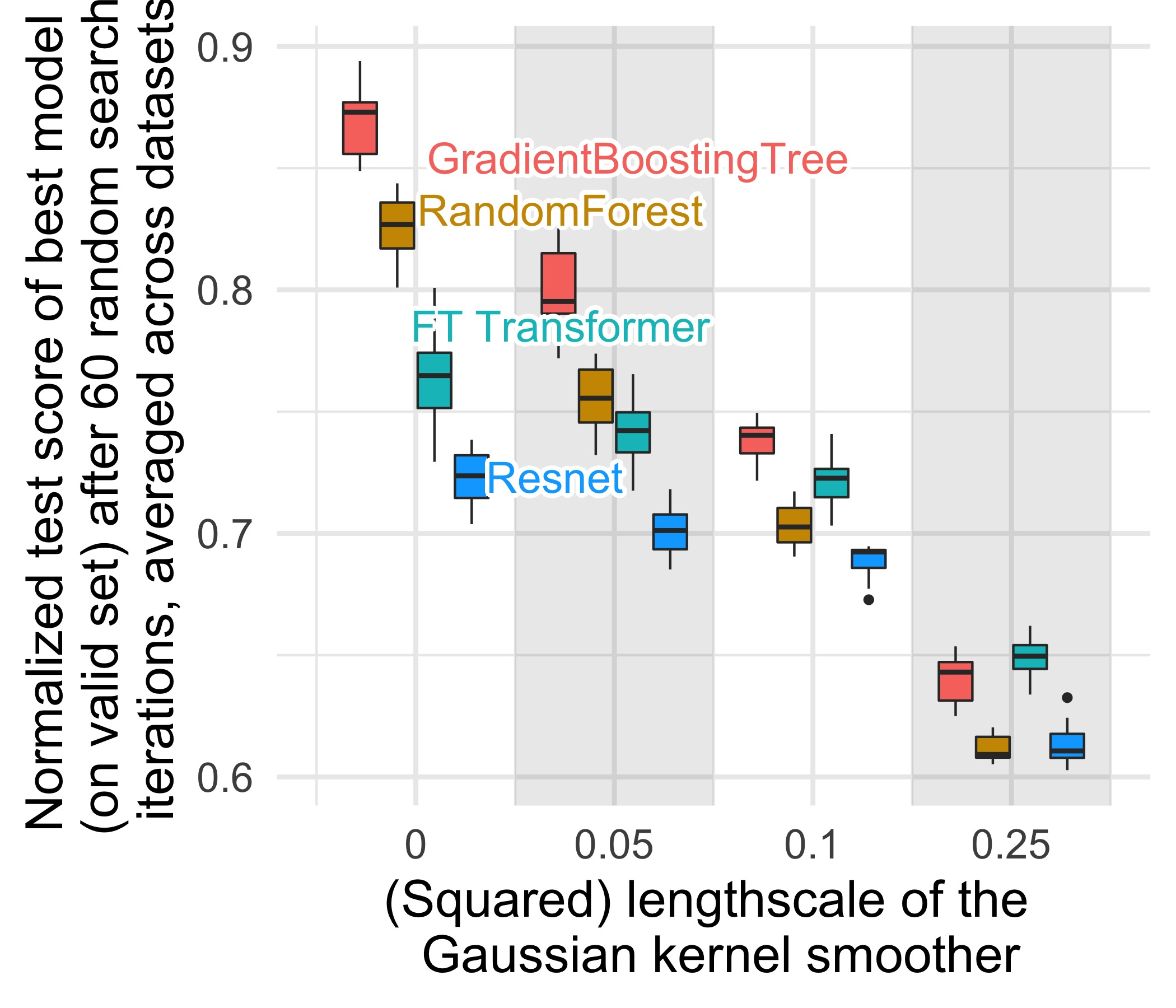
2.2.2 发现 2:神经网络类模型更容易受到无信息的冗余特征影响
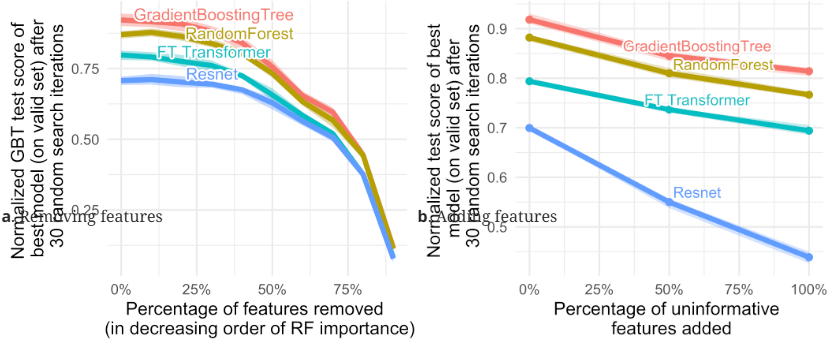
- 移除一半的特征对于 GBT 类树模型的精度影响不大,但对神经网络类模型影响更明显
- 添加冗余的无效特征对神经网络类模型的负面影响,也要远大于对 GBT 类树模型的影响
2.2.3 发现 3:数据旋转干扰对神经网络类模型的性能影响更小,尤其是ResNet
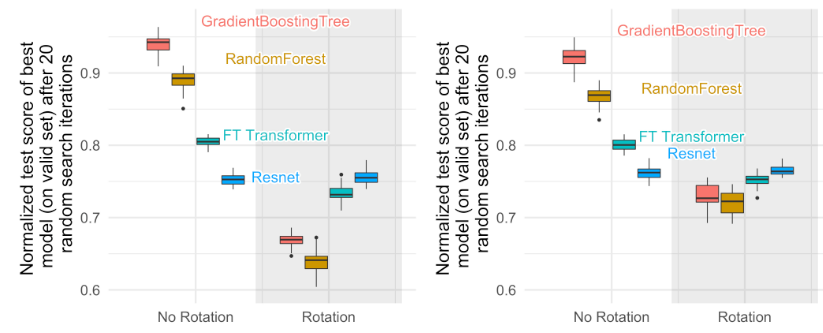 研究表明,对于需要学习旋转不变性的模型来说,在数据中加入大量冗余的特征,会导致算法需要更多的训练数据来学习和适应这些冗余特征(在预期性能不变的情况下,冗余特征的增加会导致训练所需样本量线性增加)
研究表明,对于需要学习旋转不变性的模型来说,在数据中加入大量冗余的特征,会导致算法需要更多的训练数据来学习和适应这些冗余特征(在预期性能不变的情况下,冗余特征的增加会导致训练所需样本量线性增加)
这可能在一定程度上解释,为什么神经网络类模型更容易受到冗余特征的影响(因为它们会学习旋转不变性)