前置知识:思维链提示 CoT 和自洽性 self-consistency
思维树 ToT
思维树 ToT (Tree of Thoughts,2023-05):
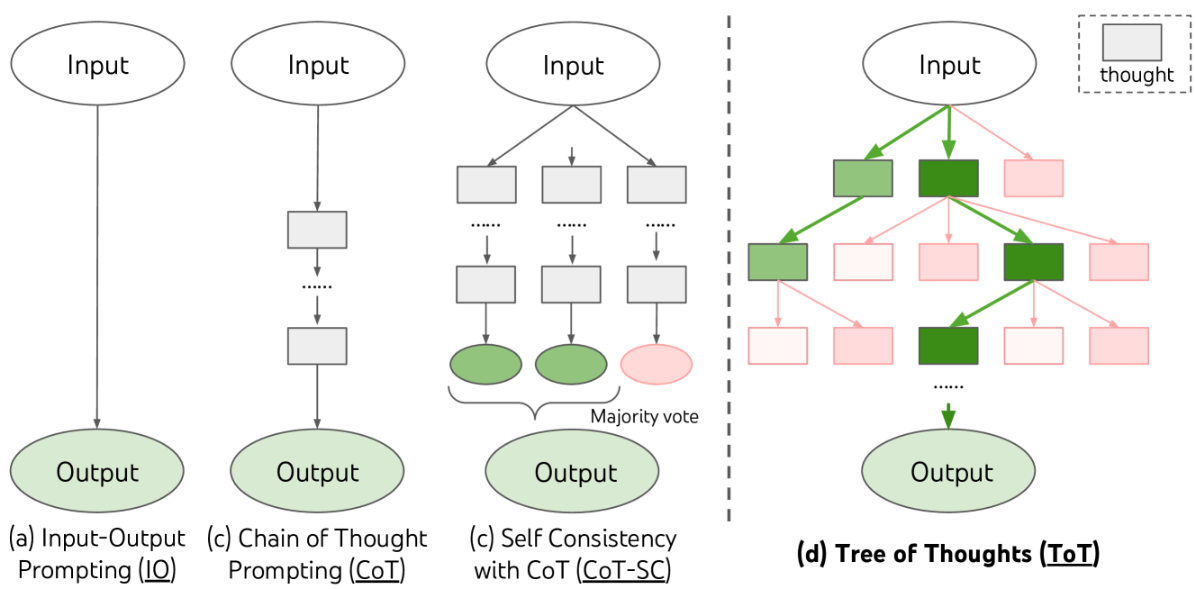
- ToT 的核心思想是将问题解决过程视为在思想树中的搜索,其中每个节点代表一个部分解决方案,每个分支代表对解决方案的修改,通过多条推理路径评估实现更优的推理决策
以“24 点数字”游戏为例来说明 ToT 的实现步骤:
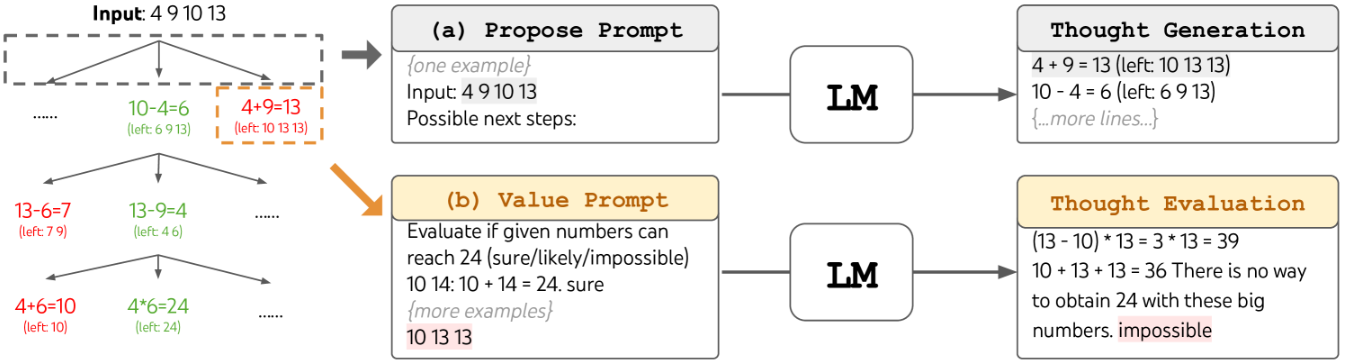
- “24 点数字”是一种简单的数字推理游戏,给定 4 个数字,比如 $[4,9,10,13]$;游戏目标是将 4 个字数进行加减乘除的四则运算组合得到 24 的答案,比如:$(13-9)\times (10-4)=24$
- 步骤 1:根据实际问题的特性来进行思维过程的设计和分解,得到一个足够多样化且具备解决方案的思考步骤(树节点),比如 $10-4=6$ 或 $4+9=13$ 等中间计算过程
- 步骤 2:针对每个节点继续提出 $k$ 个候选方案;对于思路相对宽泛的场景,采用 CoT 的重复采样来保证候选方案的多样性;对于思路相对受限的场景,采用“propose prompt”来顺序生成候选方案,避免方案的重复
- 步骤 3:针对每个节点进行状态评估,判断哪些节点是值得继续探索的并选择探索策略
- 步骤 4:重复以上步骤以构建包含多条推理路径的树结构思维框架;探索策略主要包括广度优先算法 BFS(每次生成 $k$ 个候选方案) 和深度优先算法 DFS (当判断不值得探索后退回父节点)两种
- 实验效果:在 24 点游戏中,虽然仅使用思维链提示的 GPT-4 仅解决了 4%的任务,而 ToT 方法达到了 74%的成功率;ToT 方法在创意写作和迷你填字游戏等实验中的表现也有显著改善
思维树 ToT 小结:
- 考虑了多种推理路径分支,具备回溯能力,模型决策表现有显著改善
- 存在冗余的思考过程(算力浪费超 70%),计算成本与推理时间增加
思维图 GoT
思维图 GoT (Graph of Thoughts,2023-08)
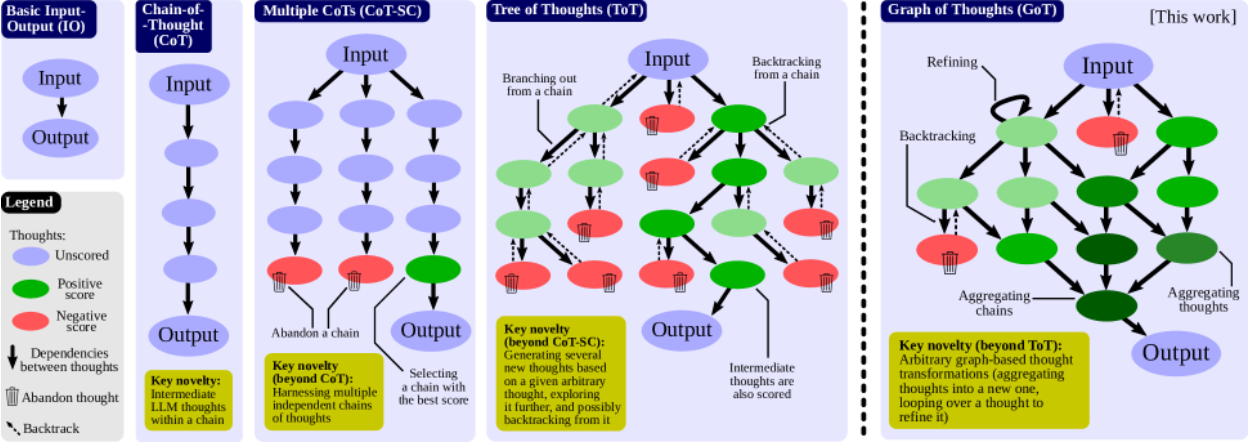
- GoT 的核心思想是将 LLM 生成信息建模为任意图,其中信息单元(“LLM 思维”)是顶点,边对应于这些顶点之间的依赖关系;GoT 将任意 LLM 思维进行组合协同与反馈增强,构建出解决问题的思维网络
思维图 GoT 架构与模块
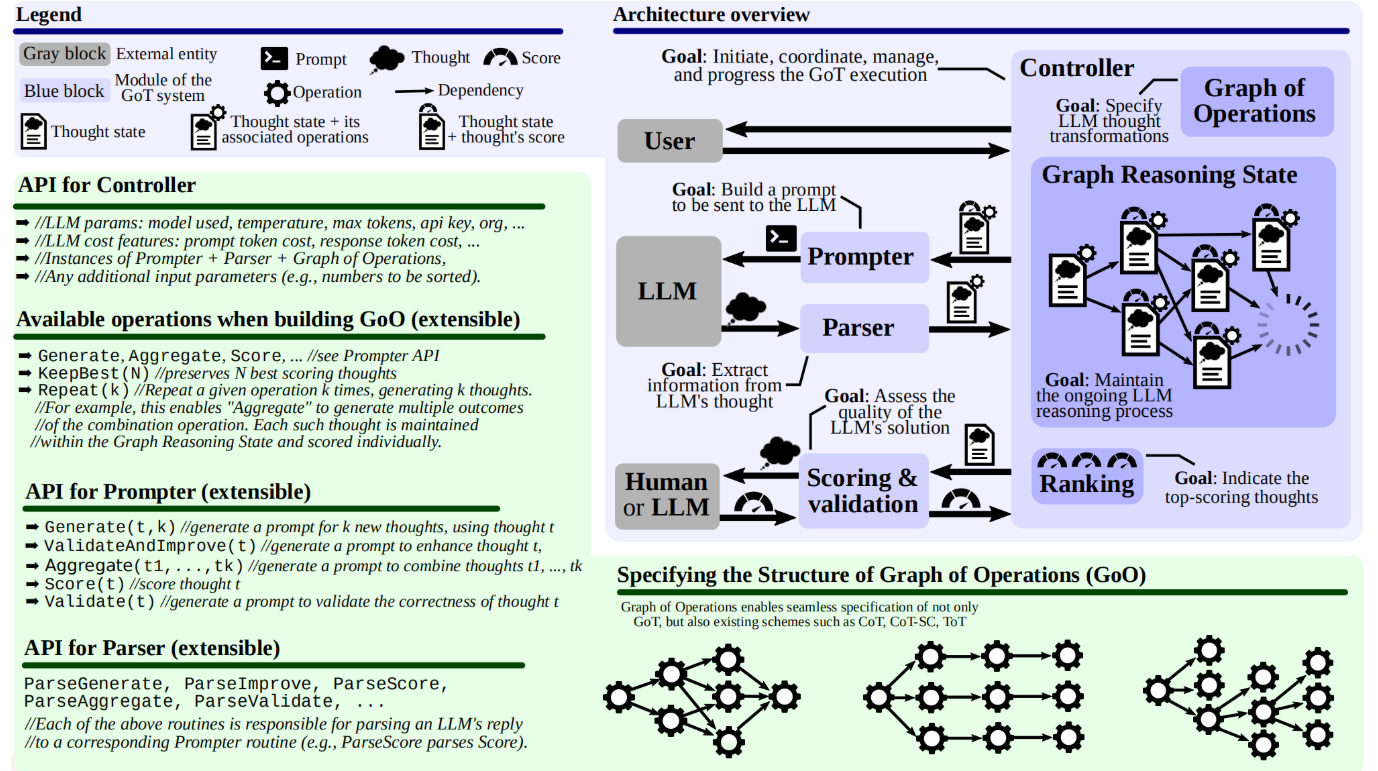
- GoT 架构包含一组可交互、可拓展的模块:(1)提示器 Prompter,准备并发送提示文本给 LLMs(2)解析器 Parser,从 LLMs 输出中构建思维状态,用于后续的 GRS 更新(3)评分与验证,验证 LLMs 输出是否满足潜在的正确条件,评分方式包括函数、人为打分和模型打分等(4)控制器 Controller,协调整个推理过程,并决定如何推进不同组件间的交互
- 控制器包含两个重要的元素:(1)操作图 GoO,,一种针对任务进行图分解的静态结构,规定了 LLMs 的思考顺序、依赖和转换(2)推理状态图 GRS,一种维护和记录推理路径与状态的动态结构
思维图 GoT 示例 - 数字排序问题

- 步骤 1,问题拆分:将 64 个数字划分为 4 组,每组包含 16 个数字,然后进行排序
- 步骤 2,方案整合:将排序后的子组进行合并(归并排序),得到完整的已排序数组
- 步骤 3,思路泛化:参考当前的解决方案,生成更多可供 LLMS 参考的合理示例
- 步骤 4,完善增强:整合之前的思路与提示,对最终的结果进行完善和错误修正
思维图 GoT 小结:
- 与 ToT 相比,GoT 在排序任务中的表现提高了 62%,同时将成本降低了 31%
- GoT 在集合交叉/词频统计/文档合并等任务上表现也显著优于 CoT、ToT 等方法
- GoT 的思维分解和控制流程过于灵活,可能导致最终输出结果的不可控
原子思维 AoT
原子思维 AOT (Atom of Thoughts,2025-02)
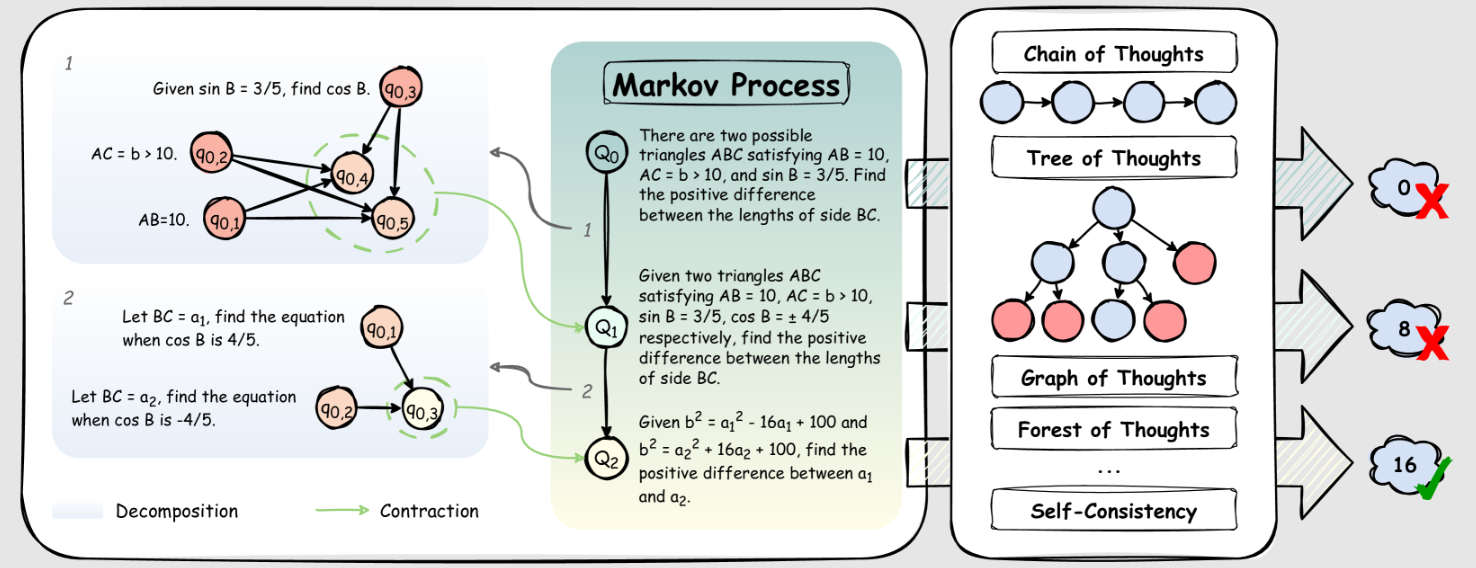
- AOT 的核心思想是将复杂的推理过程分解为一系列原子问题(atomic questions),并通过马尔可夫式的状态转换来实现高效的推理,同时改善了模型推理表现
- 具体来说,AOT 通过一个两阶段的状态转换机制来实现推理过程:(1)分解 Decomposition,将当前问题分解为分解为细粒度的子问题,同时基于依赖关系构建有向无环图 DAG(2)收缩(Contraction),将DAG中的子问题收缩成一个新的独立问题,即原子问题;该过程在整个马尔可夫链中保持答案等价性
- 迭代与终止:(1)在 AOT 的推理过程中,每次收缩过程得到的原子问题可以作为下次分解过程的输入(2)LLMs 会根据问题执行结果、DAG 结构和子问题独立执行结果,自动进行终止判断(3)终止时,AOT 将当前合并问题与所有先前迭代中积累的依赖子问题进行综合考虑,得到最终的完整方案
原子思维 AOT 小结:
- AoT 显著减少了 LLMs 在处理历史信息上存在的资源浪费,让模型更专注于有效的推理
- AoT 所推导出的原子问题,可以直接集成到现有的任意推理框架(ToT/GoT 等)中,降本增效
- AOT 在六个基准测试上均表现出有效性,其中在 HotpotQA 上,当应用于 gpt-4o-mini 时,AoT 达到了 80.6%的 F1 分数,比 o3-mini 高 3.4%,比 DeepSeek-R1 高 10.6%
其他 CoT 进阶
思维森林(Forest-of-Thought,FoT,2024-12),
- 通过整合多个推理树(“森林”)实现集体决策,弥补个体的不足
- 结合稀疏激活、动态自我校正和共识引导策略,提升推理效率与准确性
递归思维链(Chain of Recursive Thoughts,CoRT,2025-04)
- AI 通过反复与自己争论来更深入地思考
自动提示工程师(Automatic Prompt Engineer,APE,2022-11)
- 将指令生成视为自然语言程序合成问题,并将其形式化为一个黑盒优化问题
- 利用LLMs的一般性能力来生成和搜索指令候选解,寻找特定任务上的最优指令