1 培训实战-信用评分卡
1.1 背景知识
国内现状:目前以商业银行和消费金融公司为主,主要通过个人基本信息、银行数据(授权)、交易数据、社交数据等,来进行信用评级
评分卡分类:
| 名称 | 所处阶段 | 所含数据 |
|---|---|---|
| 申请评分卡 | 评价申请阶段客户信用风险 | 只有基本信息,无客户交易信息 |
| 申请评分卡 | 通过客户的行为评估客户风险 | 包含基本信息和客户行为信息 |
| 催收评分卡 | 对已逾期或违约的客户进行评分 | 额外的催收后客户反应等数据 |
评分卡的观察期与表现期:
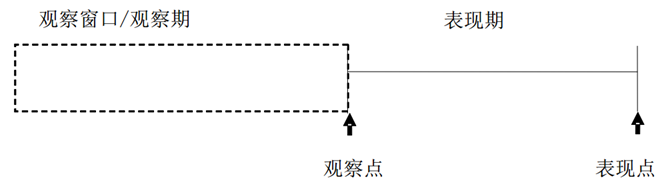
- 观察期:客户信息的表现窗口
- 观察点:在某个时点客户信息被作为当前月提取
- 表现期:客户根据截止到表现点的表现被分类成“好”、“坏”。表现期需要有足够的长度,不能够太短,从而保证样本群体分类的稳定性,使客户的逾期行为充分表现出来。但也不能够过于长。
客户类型定义:主要参考逾期状态(如逾期期数)和逾期金额等
1.2 建模过程
排除项设计:模型开发样本应具有群体代表性,而且必须有准确的预测信息和表现信息,从而使模型在开发时更加准确,并且可在未来进行应用。
- 异常行为:按条例拒绝、特殊账户、销户
- 特殊账户:出国、卡丢失/失窃、死亡、未成年、员工账户、VIP
- 其他:欺诈(根据反欺诈评分)、表现期无表现
数据准备
- 缺失值分析和处理(剔除、聚类填补、均值填补)
- 异常值分析和处理(箱线图检测、聚类检测)
单因子分析
多因子分析
- 对风险因子进行相关性分析(Pearson检验、Spearman检验)
- 相关性>0.5的风险因子,需要保留其中一个,以免造成多重共线性
建模与评价
- 数据集划分(训练集、验证集、测试集)
- 分类预测模型(逻辑回归、决策树、随机森林、xgboost)
- 模型的验证(样本内验证、样本外验证、时间外验证)
- 模型划分(间隔的合理性、稳定性和集中度;Uncovered exposure and its materiality)
- 模型表现(评分卡的识别能力(AR, KS, etc)、稳定性(PSI)、集中度;Risk driver appropriateness)
1.3 最终产出
相关数据和产出

