datasets数据集
sklearn的数据集库datasets提供很多不同的数据集,主要包含以下几大类:
- 玩具数据集
- 真实世界中的数据集
- 样本生成器
- 样本图片
- svmlight或libsvm格式的数据
- 从http://openml.org下载的数据
- 从外部加载的数据
用的比较多的就是1和3,这里进行主要介绍,其他的会进行简单介绍,但是不建议使用。
1 玩具数据集
scikit-learn 内置有一些小型标准数据集,不需要从某个外部网站下载任何文件,用datasets.load_xx()加载。
1.1 (一) 波士顿房价
统计了波士顿506处房屋的13种不同特征( 包含城镇犯罪率、一氧化氮浓度、住宅平均房间数、到中心区域的加权距离以及自住房平均房价等 )以及房屋的价格,适用于回归任务。
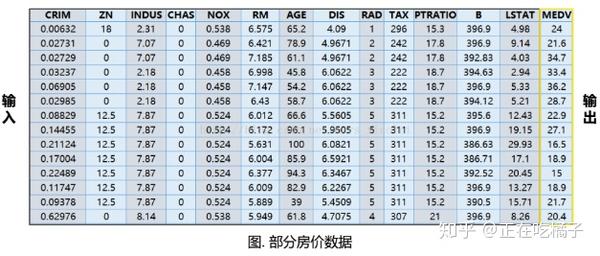
from sklearn import datasets # 导入库
boston = datasets.load_boston() # 导入波士顿房价数据
print(boston.keys()) # 查看键(属性) ['data','target','feature_names','DESCR', 'filename']
print(boston.data.shape,boston.target.shape) # 查看数据的形状 (506, 13) (506,)
print(boston.feature_names) # 查看有哪些特征 这里共13种
print(boston.DESCR) # described 描述这个数据集的信息
print(boston.filename) # 文件路径
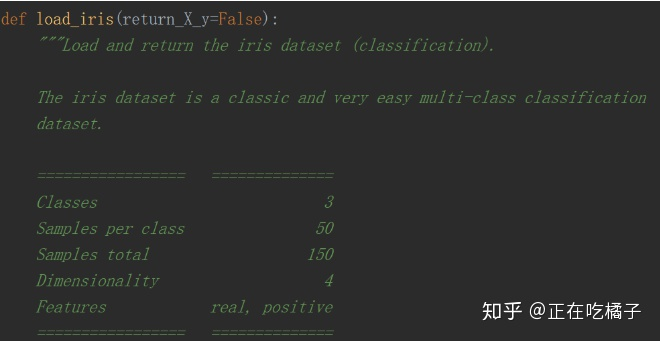
1.2 (二) 鸢尾花
这个数据集包含了150个鸢尾花样本,对应3种鸢尾花,各50个样本,以及它们各自对应的4种关于花外形的数据 ,适用于分类任务。
from sklearn import datasets # 导入库
iris = datasets.load_iris() # 导入鸢尾花数据
print(iris.data.shape,iris.target.shape) # (150, 4) (150,)
print(iris.feature_names) # [花萼长,花萼宽,花瓣长,花瓣宽]
还可以在sklearn\datasets_base.py文件中查看信息:3类,每类50个,共150个样本,维度(特征)为4,特征的数值是真实的,并且都是正数。
其他数据集大同小异,节省大家时间,下面只做简单介绍。
1.3 (三) 糖尿病
主要包括442个实例,每个实例10个属性值,分别是:Age(年龄)、性别(Sex)、Body mass index(体质指数)、Average Blood Pressure(平均血压)、S1~S6一年后疾病级数指标,Target为一年后患疾病的定量指标, 适用于回归任务。
from sklearn import datasets # 导入库
diabetes = datasets.load_diabetes() # 导入糖尿病数据
1.4 (四) 手写数字
共有1797个样本,每个样本有64的元素,对应到一个8x8像素点组成的矩阵,每一个值是其灰度值, target值是0-9,适用于分类任务。
from sklearn import datasets # 导入库
digits = datasets.load_digits() # 导入手写数字数据
1.5 (五) 体能训练
兰纳胡德提供的体能训练数据,data和target都是20x3,data的特征包括Chins, Situps and Jumps.(引体向上 仰卧起坐 跳跃),target的三维分别是Weight, Waist and Pulse.(体重 腰围 脉搏),适用于回归问题,用的少。
1.6 (六) 红酒
共178个样本,代表了红酒的三个档次(分别有59,71,48个样本),以及与之对应的13维的属性数据,适用于分类任务。
from sklearn import datasets # 导入库
wine = datasets.load_wine() # 导入红酒数据
1.7 (七) 威斯康辛州乳腺癌
包含了威斯康辛州记录的569个病人的乳腺癌恶性/良性(1/0)类别型数据,以及与之对应的30个维度的生理指标数据,适用于二分类问题。
from sklearn import datasets # 导入库
cancer = datasets.load_breast_cancer() # 导入乳腺癌数据
2 真实世界中的数据集
scikit-learn 提供加载较大数据集的工具,并在必要时可以在线下载这些数据集,用datasets.fetch_xx()加载。
调用描述
- fetch_olivetti_faces()
Olivetti 脸部图片数据集fetch_20newsgroups()用于文本分类、文本挖据和信息检索研究的国际标准数据集之一。数据集收集了大约20,000左右的新闻组文档,均匀分为20个不同主题的新闻组集合。返回一个可以被文本特征提取器
- fetch_20newsgroups_vectorized()
这是上面这个文本数据的向量化后的数据,返回一个已提取特征的文本序列,即不需要使用特征提取器
- fetch_lfw_people()
打好标签的人脸数据集
- fetch_lfw_pairs()
该任务称为人脸验证:给定一对两张图片,二分类器必须预测这两个图片是否来自同一个人
- fetch_covtype()
森林植被类型,总计581012个样本,每个样本由54个维度表示(12个属性,其中2个分别是onehot4维和onehot40维),以及target表示植被类型1-7,所有属性值均为number,详情可调用
fetch_covtype()['DESCR']了解每个属性的具体含义
- fetch_rcv1()
路透社新闻语料数据集
- fetch_kddcup99()
KDD竞赛在1999年举行时采用的数据集,KDD99数据集仍然是网络入侵检测领域的事实Benckmark,为基于计算智能的网络入侵检测研究奠定基础,包含41项特征
- fetch_california_housing()
加利福尼亚的房价数据,总计20640个样本,每个样本8个属性表示,以及房价作为target,所有属性值均为number,详情可调用
fetch_california_housing()['DESCR']了解每个属性的具体含义
- fetch_species_distributions()
物种分布数据集
3 样本生成器
3.1 (一) 簇
from sklearn import datasets
centers = [[2,2],[8,2],[2,8],[8,8]]
x, y = datasets.make_blobs(n_samples=1000, n_features=2, centers=4,cluster_std=1)
- n_samples: 样本数
- n_features: 特征数(维度)
- centers: 中心数,也可以是中心的坐标
- cluster_std: 簇的方差
3.2 (二) 同心圆
x, y = datasets.make_circles(n_samples=5000, noise=0.04, factor=0.7)
- noise: 噪声
- factor: 内圆与外圆的距离 为1的时候最小
3.3 (三) 月牙
x, y = datasets.make_moons(n_samples=3000, noise=0.05)
3.4 (四) 分类
x, y =datasets.make_classification(n_classes=4, n_samples=1000, n_features=2, n_informative=2 , n_redundant=0, n_clusters_per_class=1,n_repeated=0, random_state=22)
- n_classes:类的数目
- n_informative:有效的特征数
- n_redundant:冗余特征数 有效特征数的线性组合
- n_repeated:有效特征数和冗余特征数的有效组合
- n_informative + n_redundant + n_repeated < = n_features
- n_clusters_per_class:每一类的簇数
- n_classes * n_clusters_per_class <= 2**n_informative
4 样本图片
scikit 在通过图片的作者共同授权下嵌入了几个样本 JPEG 图片。这些图像为了方便用户对 test algorithms (测试算法)和 pipeline on 2D data (二维数据管道)进行测试,用datasets.load_sample_image()加载。
from sklearn import datasets
import matplotlib.pyplot as plt
img = datasets.load_sample_image('flower.jpg')
print(img.shape) # (427, 640, 3)
print(img.dtype) # uint8
plt.imshow(img)
plt.show()

5 svmlight或libsvm格式的数据
可以加载svmlight / libsvm格式的数据集。
from sklearn.datasets import load_svmlight_file,load_svmlight_files
# 加载单个文件
X_train, y_train = load_svmlight_file("/path/to/train_dataset.txt")
# 加载多个文件
X_train, y_train, X_test, y_test = load_svmlight_files(("/path/to/train_dataset.txt", "/path/to/test_dataset.txt"))
6 从http://openml.org下载的数据
openml.org 是一个用于机器学习数据和实验的公共存储库,它允许每个人上传开放的数据集,可以通过sklearn.datasets.fetch_openml()函数来从openml.org下载数据集。
例如,下载gene expressions in mice brains(老鼠大脑中的基因表达)数据集:
from sklearn.datasets import fetch_openml
mice = fetch_openml(name='miceprotein', version=4)
print(mice.DESCR) # 查看详情
7 从外部加载的数据
建议除了玩具数据集和生成数据集以外,都在网上下载后用pandas导入。
kaggle:https://www.kaggle.com
天池:https://tianchi.aliyun.com/dataset
搜狗实验室:http://www.sogou.com/labs/resource/list_pingce.php
DC竞赛:https://www.pkbigdata.com/common/cmptIndex.html
DF竞赛:https://www.datafountain.cn/datasets
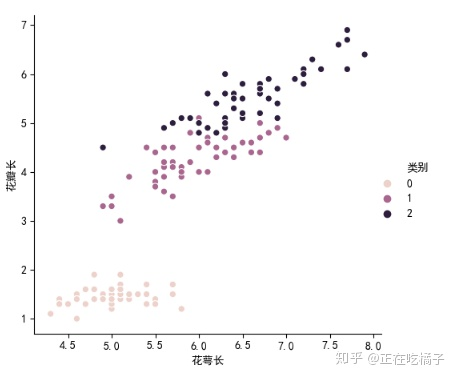
例如,导入iris文件:
import pandas as pd
import seaborn as sns # 基于matplotlib和pandas的画图库
import matplotlib.pyplot as plt
data = pd.read_csv('G:\iris.csv', encoding='gbk') # 我把数据集列名改成了中文 所以用gbk解码
sns.relplot(x='花萼长', y='花瓣长', hue='类别',data=data) # seaborn库这里不做过多介绍
plt.rcParams['font.sans-serif'] = ['SimHei'] # 步骤一(替换sans-serif字体)
# plt.rcParams['axes.unicode_minus'] = False # 步骤二(解决坐标轴负数的负号显示问题)
plt.show()
8 总结
sklearn的数据集datasets库中,一般使用玩具数据集和样本生成器比较多,其他数据建议外部导入。
参考链接:https://zhuanlan.zhihu.com/p/108393576