中文标题:基于Lattice LSTM的中文命名实体识别
英文标题:Chinese NER Using Lattice LSTM
发布平台:ACL
Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics
发布日期:2018-01-01
引用量(非实时):596
DOI:10.18653/v1/P18-1144
作者:Yue Zhang, Jie Yang
文章类型:conferencePaper
品读时间:2022-01-14 16:16
1 文章萃取
1.1 核心观点
本文在LSTM的基础上研究了一种名为Lattice的结构,能够在基于字向量进行建模的同时,借助Lattice结构进行词级别信息的补充,避免了模型受到分词错误的影响,最终模型在不同数据集上都取得了较好的NER识别效果,优于仅基于词向量或字向量的情况。
1.2 综合评价
- 充分结合了词信息的字模型,最终效果出色
- 构建门进行词的选择,具备了一定消歧和筛选能力
- 词信息之间没有前后关联性,只做了词与字之间的关联性
- 验证实验全面严谨,最终代码开源,值得一看
1.3 主观评分:⭐⭐⭐⭐⭐
2 精读笔记
2.1 背景介绍与相关工作
研究表明,基于字的模型有时并不会比基于词的模型差
Lattice结构的RNN可以看作树结构的RNN向GANs(有向无环图)的拓展
对于基础的LSTM模型来说,常见的改进方式如下:
- 双向结构:从两个方向建立LSTM,并拼接最终隐藏层输出
- 输入信息丰富:拼接词向量、字向量、上下文向量、段向量
- 中间层丰富:保留LSTM隐藏层第一次和最后一次输出;新结构,如CNN层
2.2 模型细节
本论文采用英文NER比较成熟优秀的方案LSTM+CRF作为主要的模型结构
2.2.1 模型输入
Lattice-LSTM是基于字的LSTM的模型的拓展,额外集成了基于词的单元和用于控制词信息的门
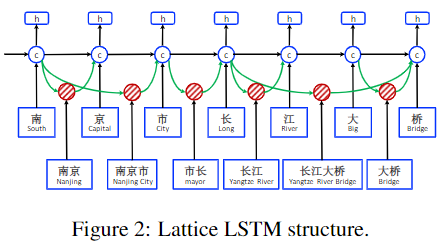
模型的输入包括原始文本$T$和字典$D$
- 输入文本$T$是由一系列的字符($c_1,...,c_m$)组成的
- 字典$D$则是$T$中所有符合已有词典的的字符子序列(小词典)
- 用$w_{b,c}^d$表示小词典中的每一个词,其中$b$表示词起始索引,$e$表示词终止索引,以上图中的"南京市长江大桥"为例,$w_{1,2}^d$表示”南京“,$w_{7,8}^d$表示“大桥”
2.2.2 字部分模型结构
模型中基于字的基础网络结构如下所示:
$$\left[ \begin{matrix} i_j^c \\ o_j^c \\ f_j^c \\ \widetilde{c}_j^c \\ \end{matrix} \right] =\left[ \begin{matrix} \sigma \\ \sigma \\ \sigma \\ \ tanh\ \\ \end{matrix} \right] (W^{cT} \left[ \begin{matrix} x_j^c \\ h_{j-1}^c \\ \end{matrix} \right] +b^c)$$
- 假设输入的字符是$c_j$ ,其经过Embedding转化为$x_j^c=e^c(c_j)$
- $h_{j-1}^c$表示上一层的隐藏层输出,$W^{cT}$和$b^c$分别表示系数和截距项
- $i_j^c,o_j^c,f_j^c$分别表示输入门、输出门和遗忘门的结果(经过sigmoid函数映射得到),而$\widetilde{c}_j^c$表示可能需要记忆存储的状态值(经过tanh函数映射得到)
最终字模型的记忆向量为 $$c_j^c=f_j^c\odot c^c_{j-1}+i_j^c\odot \widetilde{c}_j^c$$- 其中$\odot$表示Hadamard乘积,即矩阵对应位置元素相乘
- $c_{j-1}^c$表示上一次的记忆向量
最终字模型的隐藏层输出为 $$h_j^c=o_j^c\odot tanh(c_j^c)$$
2.2.3 词部分模型结构
模型增加的基于词的部分网络结构如下所示:
$$\left[ \begin{matrix} i_{b,e}^w \\ f_{b,e}^w \\ \widetilde{c}_{b,e}^w \\ \end{matrix} \right] =\left[ \begin{matrix} \sigma \\ \sigma \\ \ tanh\ \\ \end{matrix} \right] (W^{wT} \left[ \begin{matrix} x_{b,e}^w \\ h_{b}^c \\ \end{matrix} \right] +b^w)$$
- 假设输入的词为$w_{b,e}^d$,其经过Embedding转化为$x_{b,e}^w=e^w(w_{b,e}^d)$
- $h_b^c$表示索引为$b$的对应字符,在字模型中的隐藏层输出
- 需要注意的是,词模型没有输出门,需要更合理的方式与字模型融合
最终词模型的记忆向量为 $$c_{b,e}^w=f_{b,e}^w\odot c^c_b+i_{b,e}^w\odot \widetilde{c}_{b,e}^w$$
2.2.4 Lattice模型-为字模型添加词信息
因为Lattice模型是基于字模型搭建的,所以添加词信息需要将词与字进行对齐,还是以”南京市长江大桥“为例,对于$j=7$的时候,对应的字为"桥",对应的词的可能性有”大桥“或”长江大桥“(词的确定依赖于提前整理的词典)。
字词对齐的结果将是一字vs一词或多词的形式
下一步就是针对字的每一种可能组词,分别构建一个门,采用sigmoid函数作为激活函数,自适应的计算出每个字的所有可能组词的贡献度: $$i_{b,e}^c=\sigma(W^{lT} \left[ \begin{matrix} x_e^c \\ c_{b,e}^w \\ \end{matrix} \right] +b^l )$$
- 连接门的输入包括字向量$x^c_e$和词模型的记忆向量
- 最终的输出值描述了词信息对于字模型的重要程度
最终的Lattice模型的记忆向量需要在字模型的记忆向量基础上稍作修改: $$c_j^c=\Sigma_{b\in {b'|w^d_{b',j} \in D}}\alpha_{b,j}^c\odot c^w_{b,j}+\alpha_j^c\odot \widetilde{c}_j^c$$
Lattice的记忆向量其实是字记忆向量与词记忆向量的加权平均
其中$\alpha_{b,j}^c$和$\alpha_j^c$分别对应$i_{b,j}^c$和$i_j^c$规划化处理后的结果,具体处理公式如下: $$\alpha_{b,j}^c=\frac{exp(i_{b,j}^c)}{exp(i_j^c)+\Sigma_{b\in {b'|w^d_{b',j}\in D}}exp(i_{b'}^c)}$$ $$\alpha_{b,j}^c=\frac{exp(i_j^c)}{exp(i_j^c)+\Sigma_{b\in {b'|w^d_{b',j}\in D}}exp(i_{b'}^c)}$$
最终的Lattice模型的隐藏层输出字模型的隐藏层输出无差异: $$h_j^c=o_j^c\odot tanh(c_j^c)$$ 最后的模型输出还需要添加CRF层,并借助Veterbi算法找到最优的标注序列。
2.3 模型实验结果
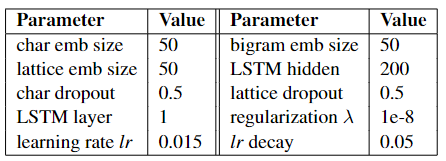
相关超参设定:
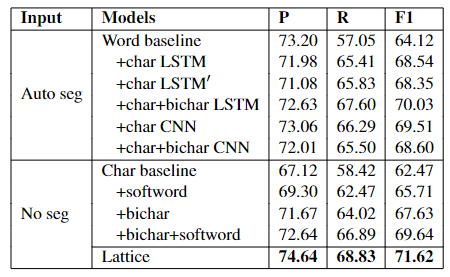
模型效果对比:
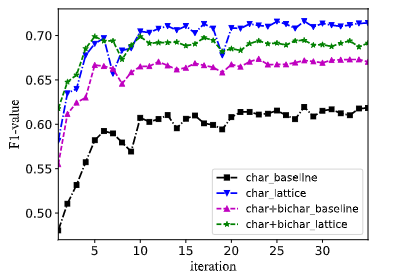
模型精度 VS 迭代次数:
模型精度 VS 字符长度:
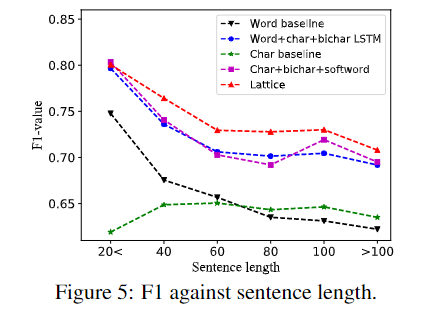
除此之外,Lattice模型在OntoNotes 4、MSRA、Weibo NER、简历数据(作者自己抓取的)具有非常优秀的表现,几乎都取得了最优或次优的成绩。
词典的质量会在一定程度上影响到Lattice模型的精度,但同时Lattice模型也具备自行寻找更准确的词语的能力,而且这种自由选择词语的能力也使得模型具备一定的消除歧义的能力,因此最终模型的稳定性和泛化能力都比较出色。