中文标题:从图像中进行自监督学习,采用联合嵌入预测架构
英文标题:Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture
发布平台:IEEE
发布日期:2023-06-01
引用量(非实时):76
DOI:10.1109/CVPR52729.2023.01499
作者:Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, Nicolas Ballas
文章类型:conferencePaper
品读时间:2024-02-29 14:41
1 文章萃取
1.1 核心观点
本文介绍了基于图像的联合嵌入预测架构(I-JEPA),这是一种从图像进行自我监督学习的非生成方法。 I-JEPA 无需使用手工制作的数据增强即可学习强大的语义表示,其核心逻辑很简单:从单个上下文块预测同一图像中各个目标块的表示。
引导 I-JEPA 生成语义表示的核心设计选择是屏蔽策略,具体来说:I-JEPA 的输入图像块需要足够的信息(空间分布);I-JEPA 会以足够大的尺度采样目标块(占据图像的 15%–20%);I-JEPA 会同时预测图像中的几个目标块
实验表明,I-JEPA 在 ImageNet-1K 线性探测、半监督 1% ImageNet-1K 和语义传输任务上优于像素重建方法;I-JEPA 适用于广泛的图像下游任务,训练所需的计算量少
1.2 综合评价
- I-JEPA 以联合嵌入架构学习实现了一种通用表示,而不依赖于先验知识/手工数据增强
- I-JEPA 通过潜在空间的 x, y 联合嵌入学习,以更低的资源消耗实现了更强的模型表现
- I-JEPA 具备较好的通用性,其核心逻辑可轻易地推广至音频、视频等领域,潜力较大
1.3 主观评分:⭐⭐⭐⭐⭐
2 精读笔记
2.1 背景知识
计算机视觉中的两种常见图像自监督学习方法:
- 基于不变性的方法:同一图像的不同视图生成相似的嵌入,视图一般通过数据增强来实现,例如随机缩放、裁剪和颜色抖动等(对比学习的思路,不同领域的数据增强方式存在差异)
- 生成方法:删除或损坏输入的部分并学习预测损坏的内容,即像素或 token 级别的随机掩码预测;该方式依赖的先验知识少,并容易推广到其他领域,但通常得到的语义级别较低
自我监督学习的常见架构:
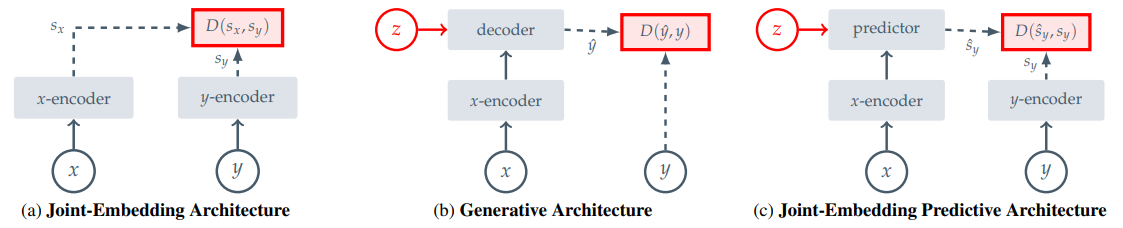
- (a) 联合嵌入架构,是一种基于不变性的预训练;为一致的输入 x 学习输出相似 y 的嵌入
- (b) 生成架构,学习以潜在变量 z 为条件的解码器,为一致的输入 x 学习重建信号 y
- (c) 联合嵌入预测架构,学习以潜在变量 z 为条件的预测器,为一致的输入 x 预测信号 y 的嵌入
2.2 算法细节
I-JEPA 基于图像的联合嵌入预测架构:
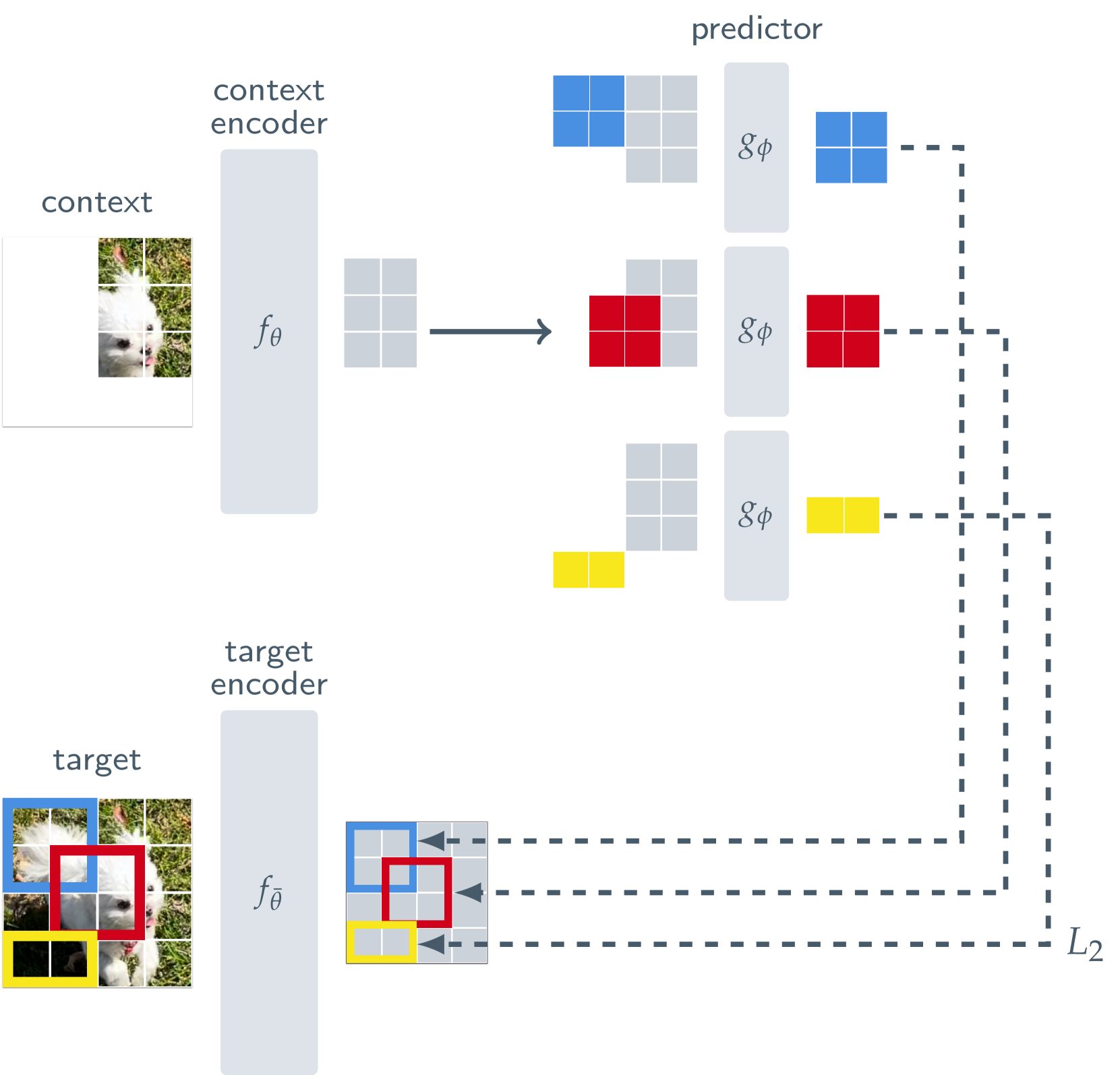
- 任务目标:使用单个上下文图像块来预测源自同一图像的各种目标图像块的表示
- 编码器和预测器均使用 Visual Transformer(ViT), 编码器处理并编码输入/输出的图像块,预测器以位置标记为条件(即上图的色块,对应目标块的位置),输出目标块的编码
- ViT 由一堆 transformer 层组成,每个 transformer 层都包含一个自注意力+全连接的 MLP
- I-JEPA 和普通遮蔽自编码器的关键区别在于:I-JEPA 是非生成式的,不存在解码器,其预测过程是在编码后的潜在表征空间中实现的(追求更合理的编码)
I-JEPA 示例:(原始图像 - 输入图像 - 输出图像)

- 给定图像,I-JEPA 随机采样四个目标块,采样比例在 0.15~0.2,长宽比在 0.75~1.5
- 上下文块的采样比例在 0.85~1.0(确保信息的丰富度),同时遮蔽上下文块中与目标块重叠的部分(增加预测难度,提高稀疏性和处理的效率)
- 损失函数:预测块的嵌入表示与目标块的嵌入表示之间的 L2 距离
2.3 实验分析
图像分类任务(I-JEPA 与最好的数据增强方法持平):
| Method | Arch. | Epochs | Top-1 | |
|---|---|---|---|---|
| 不包含数据增强的方法 | ||||
| data2vec | ViT-L/16 | 1600 | 53.5 | |
| ViT-B/16 | 1600 | 68.0 | ||
| MAE | MAE ViT-L/16 | 1600 | 76.0 | |
| ViT-H/14 | 1600 | 77.2 | ||
| ViT-B/16 | 600 | 72.9 | ||
| I-JEPA | ViT-L/16 | 600 | 77.5 | |
| ViT-H/14 | 300 | 79.3 | ||
| ViT-H/16_448 | 300 | 81.1 | ||
| 包含数据增强的方法 | ||||
| SimCLR v2 | RN152 (2×) | 800 | 79.1 | |
| DINO | ViT-B/8 | 300 | 80.1 | |
| iBOT | ViT-L/16 | 250 | 81.0 |
- B 表示 base 模型;L 表示 large 模型;H 表示 huge 模型
半监督评估(I-JEPA 具备显著优势):
| Method | Arch. | Epochs | Top-1 |
|---|---|---|---|
| 不包含数据增强的方法 | |||
| data2vec | ViT-L/16 | 1600 | 73.3 |
| MAE | ViT-L/16 | 1600 | 67.1 |
| ViT-H/14 | 1600 | 71.5 | |
| I-JEPA | ViT-L/16 | 600 | 69.4 |
| ViT-H/14 | 300 | 73.3 | |
| ViT-H/16448 | 300 | 77.3 | |
| 包含数据增强的方法 | |||
| iBOT | ViT-B/16 | 250 | 69.7 |
| DINO | ViT-B/8 | 300 | 70.0 |
| SimCLR v2 | RN151 (2×) | 800 | 70.2 |
| BYOL | RN200 (2×) | 800 | 71.2 |
| MSN | ViT-B/4 | 300 | 75.7 |
- 仅使用 1% 的可用标签对 ImageNet-1K 进行微调
下游图像分类任务(迁移学习):
| Method | Arch. | CIFAR100 | Places205 | iNat18 |
|---|---|---|---|---|
| 不包含数据增强的方法 | ||||
| data2vec | ViT-L/16 | 59.6 | 36.9 | 10.9 |
| MAE | ViT-H/14 | 77.3 | 55.0 | 32.9 |
| I-JEPA | ViT-H/14 | 87.5 | 58.4 | 47.6 |
| 包含数据增强的方法 | ||||
| DINO | ViT-B/8 | 84.9 | 57.9 | 55.9 |
| iBOT | ViT-L/16 | 88.3 | 60.4 | 57.3 |
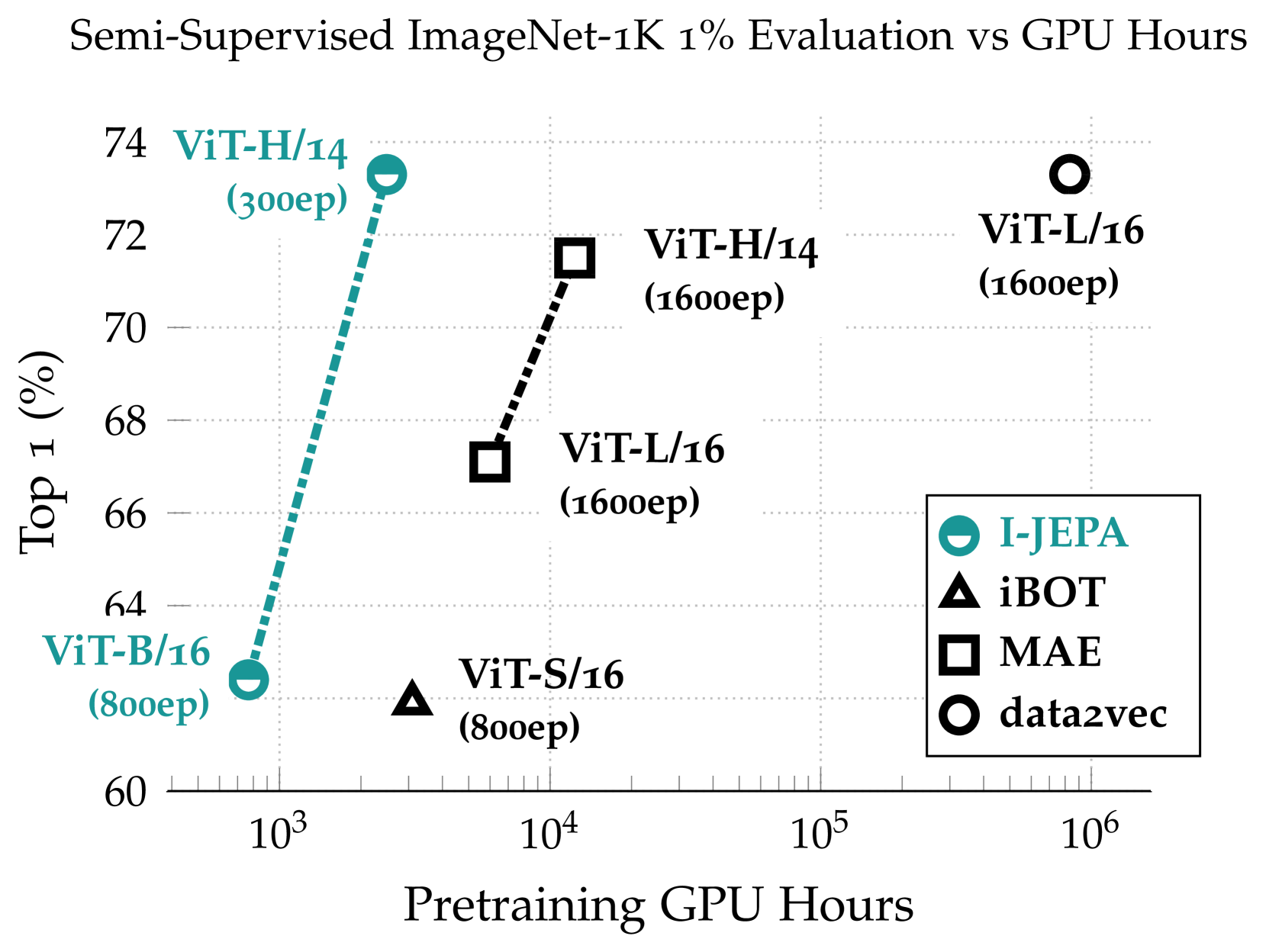
资源消耗(更少的 GPU 资源,更佳的效果):
其他结论:
- I-JEPA 方法在预训练期间有效地捕获低级图像特征
- I-JEPA 预训练受益于更大、更多样化的数据集
- I-JEPA 预测器正确捕获位置不确定性并生成具有正确姿势的高级对象部分
- I-JEPA 所需的计算量更少,并且无需依赖手工数据增强即可实现强大的性能
- 当损失应用于像素空间而不是表示空间时,I-JEPA 表示的语义级别会显着降低(66.9 -> 40.7),这凸显了目标编码器在预训练期间的重要性
- 多块屏蔽策略对于 I-JEPA 学习语义表示至关重要(像素块大小和数量的缩减会使得模型的 Top1 准确率从 54.2%下降至 11.4%)
3 后记
基于视频的自监督模型 V-JEPA:
- 基于同样的潜在空间预测和多块(时空)遮蔽机制,由 LeCun 团队后续提出
- V-JEPA 模型展现了更强的深层特征提取、少样本学习和运动理解能力
- V-JEPA 模型在 Kinetics-400 上精度为 82.1%,在 Something-Something-v2 上精度为 71.2%,与之前的最佳视频模型分别提高了+4 和+10 ;在无微调的情况下在 ImageNet 分类精度达到了 77.9%,超过了之前最好的视频模型 +6 个点
- 但由于创新点较少(基本照搬 I-JEPA 的思路),评估主要集中在线性探测方面,忽略了视频任务需要注意的运动相关性特点,因此该论文被拒了