词嵌入表示方法:应用 NLP 技术,将单词/Token 转化为向量的数值表示形式
随着 LLMs 的进步和发展,该技术也逐渐应用到图像、音频等非文本领域
传统嵌入表示
One-hot(独热)编码
One-hot(独热)编码过程:
- 用 $N$ 维仅包含 0、1 值的向量去唯一地表示 $N$ 种词
- 每个词编码后的向量包含 $N-1$ 个 0 和 1 个1
算法分析:
- One-hot 编码简单实用,是很多进阶编码方法的基础
- One-hot 编码结果过于稀疏,最好用特殊的存储方式降低内存消耗
- One-hot 编码结果无法评估不同词之间的相似度
TF-IDF
词频 TF(Term Frequency),词语 $t$ 在文档 $d$ 中出现的频率
$$ \text{TF}(t, d) = \frac{\text{词t在文档d中的出现次数}}{\text{文档d的总词数}} $$
逆文档频率 IDF(Inverse Document Frequency),词语 $t$ 在所有文档 $D$ 中的罕见程度
$$ \text{IDF}(t, D) = \log\left(\frac{\text{文档集合D的总文档数}}{\text{包含词t的文档数} + 1}\right) $$
“罕见程度”描述了一种信息量,一个文档中的“罕见词”往往包含着文档的更多信息
词语 $t$ 的 TF-IDF 值是二者的乘积,能衡量一个词语对于某个文档的重要程度 $$ \text{TF-IDF}(t, d, D) = \text{TF}(t, d) \times \text{IDF}(t, D) $$
- TF-IDF 值简单易用,容易理解,同时考虑了词频和文档信息
- TF-IDF 值忽略了词序和语义,并可能过分强调了高频词的影响
- 大部分词语的 TF-IDF 是相似且集中的,缺乏表现力和独特性
- TF-IDF 编码结果无法评估不同词之间的相似度
最终结果的可视化示例:
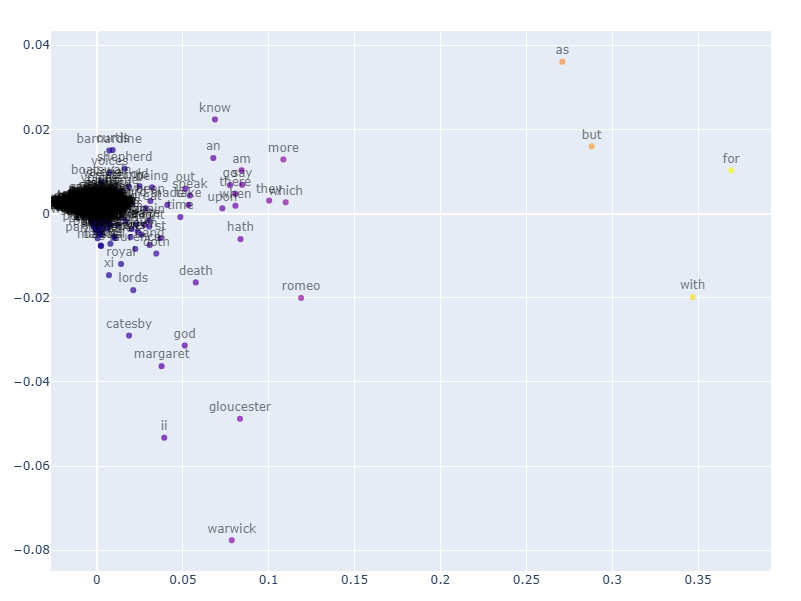
静态嵌入表示
静态嵌入表示(static embeddings), 该技术先构建一个固定的词表,并针对每个词生成一个唯一的嵌入表示;该嵌入表示是预训练且静态的,即不同上下文中的同一个词具有相同的向量表示
静态嵌入表示的常见方法包括 word2vec、Glove 和 fastText 等
word2vec
通过定义辅助目标,借助神经网络模型为基础构建词向量的过程
两类经典的 word2vec 技术
- CBOW 的目标:给定周围上下文词生成中心词
- skip-gram 的目标:给定中心词的情况下生成周围上下文词
最终获取的词向量,可看作表示单词意义的向量,也可以看作是词的特征向量
Word2vec 算法细节(以 CBOW 为例):
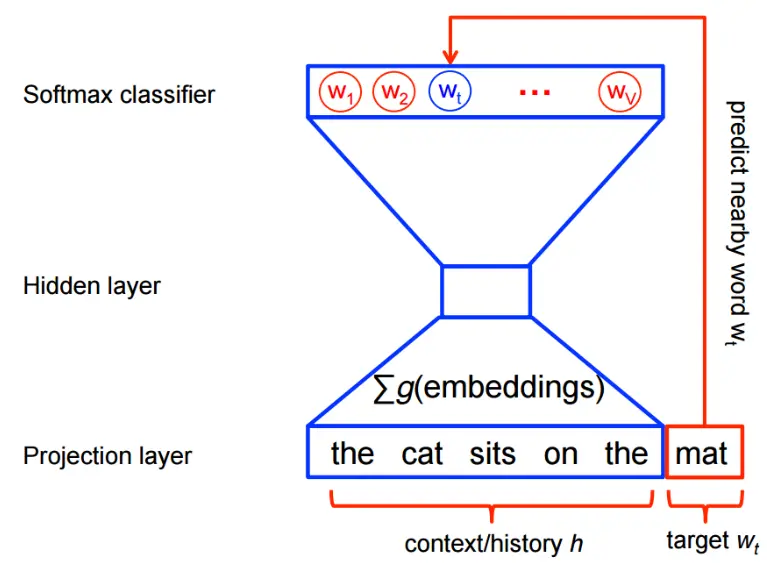
- 输入层:选定一个上下文窗口,将窗口内上下文的单词进行 one-hot 编码
- 隐藏层:对 one-hot 编码结果进行线性映射和激活,实现信息的聚合;隐藏层的维度一般远小于输入层的维度(降维);网络训练完成后,隐藏层的输出即词的静态嵌入表示(真正目标)
- 预测层:使用 softmax 预测每个可能单词的概率,并选取概率值最高的单词作为网络输出
skip-gram 算法步骤和 CBOW 是基本一致的,只是辅助目标不同,因此在输入和输出上有调整;输入调整为单个词的 one-hot 编码;输出调整为对上下文的多个词进行概率预测
当词表较大时,softmax 运算成本较高,需要通过近似训练的方式降低计算复杂度
word2vec 的算法优化:负采样与分层(Hierarchical)softmax
方法 1:负采样
- 通过错误匹配中心词与上下文形成负样本
- 将多分类(预测词/上下文)的问题转为二分类(是否正确匹配)
- 梯度计算成本从依赖于词表大小转为依赖采样数 $K$
方法 2:分层(Hierarchical)softmax
- 使用二叉树构建 softmax 的计算过程
- 最底层的叶子节点可以看作是每一种词($N$ 个类别)
- 中间的每个节点可看作一个 sigmoid 的二分类
- softmax 的 $N$ 分类问题转为基于树的多个 sigmoid 二分类问题
- 计算成本从依赖于词表大小转为依赖词表大小的对数(树的深度)
最终结果的可视化示例:

Glove
Glove(Global Vectors for Word Representation)主要基于全局词频统计构建词向量
Glove的计算与理解过程:
(1)根据语料库(corpus)构建共现矩阵(Co-ocurrence Matrix)$X$
- 其中元素$X_{ij}$表示词元$i$上下文中出现词元$j$的次数
- 共现概率$P_{ij}=X_{ij}/\Sigma_kX_{ik}$表示词元$j$出现在词元$i$上下文中的概率
- 共现概率越高,两词元间的相关性就越高
(2)理解模型的拟合目标:使用词向量尽可能还原共现矩阵
- 假设单词$i$的理想词向量为$w_i$,对应偏置项为$b_i$
- 假设单词$j$的理想词向量为$w_j$,对应偏置项为$b_j$
- 模型追求$w_i^Tw_j+b_i+b_j$的结果尽可能接近$log(X_{ij})$
(3)构建模型的损失函数: $$J=\Sigma_{i,j=1}^Vf(X_{ij})(w_i^Tw_j+b_i+b_j-log(X_{ij}))^2$$
- 其中$f(X_{ij})$表示权重函数(在一定范围内,共现概率越高,权重越大)
- 损失函数的右侧为典型的平方损失RMSE,所以模型可看作针对共现次数的回归问题
- 通过减少词向量还原共现矩阵的误差,促使最终词向量尽可能地蕴含语义语法信息
Glove模型分析:
- 相比于 word2vec,Golve 模型一般训练速度比较快,适合并行计算
- Golve 需要基于全局预料构建共现矩阵,不适合在线学习或语料不完整的情况
其他补充:
fasText
fastText 模型在 skip-gram 模型的基础上提出了子词(subword)嵌入的方法:
fastText 模型计算过程
- 在每一个词的首位添加特殊字符
<>,以单词where为例:<where> - 每一个词都拆分出长度在3-6之间的所有子词(原始词也会保留),单词
where最终可以拆分为以下子词集合:<wh,whe,her,ere,re>(只考虑长度为3的情况) - 最终单词的词向量会是对应子词集合中所有子词向量的求和结果
- 其他部分(模型结构,损失函数等)与skip-gram模型相同
fastText 模型分析:
- 能捕捉到文本中的形态信息,对未收录词、罕见词的泛化能力好
- 词表更大,计算复杂度更高(实际速度还好),对中文效果一般
上下文嵌入表示
上下文嵌入表示(contextual embeddings)与静态嵌入表示不同,其嵌入表示能根据单词对应句子或上下文的不同进行动态生成(有助于模型理解词与词之间的关系)
上下文嵌入表示的方法一般都是基于 transformer 的模型,如 ELMo、GPT 或 BERT 等
ELMo
以上的静态嵌入表示模型都默认假设语义(词向量)与上下文无关,这种简化与实际情况相悖。因此 ELMo(2018)针对此问题进行了改进。
ELMo 模型计算过程
- 在传统词向量模型结构的后面添加双层双向 LSTM 网络,用于捕捉上下文信息
- 通过词向量结构输出捕捉单词信息后,传递给第一层双向 LSTM 网络
- 第一层双向 LSTM 捕捉句法信息后,传递至下一层双向 LSTM 用于捕捉语义信息
- 最终应用到下游任务时,会将单词信息、句法信息、语义信息进行加权融合
ELMo 模型分析:
- 能根据上下文调整最终的词向量输出,适应一词多义的复杂语境
- 基于 LSTM 的双向特征拼接效果比 Transformer 结构的一体化特征融合弱
在 ELMo 之前,也有其他上下文敏感的词向量,比如 TagLM(2017)和 CoVe(2017)
GPT
GPT 是一种纯解码器 Decoder-Only 的生成式预训练模型
BERT
BERT 是一种纯编码器 Encoder-Only的遮掩语言模型(masked language modeling)
以 ELMo 为例解释了词向量从上下文无关到上下文敏感的转变(上下文双向编码)
以GPT为例解释了词向量从特定任务到任务不可知的转变(Transformer解码器+微调)
BERT融合以上两种模型的优点,实现了基于Transformer解码器对上下文的双向编码,并且只需要通过简单微调便能适用于各种下游任务
BERT 模型细节:
- 使用特殊词元
<cls>表示类别,特殊词元<sep>用于表示多文本序列的连结 - BERT 的输入可以是单文本序列,也可以是一对文本序列,每个序列输入都包含以下三个部分:词元嵌入、序列嵌入(标识不同序列)、位置嵌入(可学习的参数)
- BERT 预训练任务 1:掩蔽语言模型(Masked Language Modeling)。随机选择 15%的词元进行概率遮蔽(80%概率遮蔽,10%概率随机替换,10%概率维持不变),训练目标是准确预测被遮蔽的词元
- BERT 预训练任务 2:下一句预测(Next Sentence Prediction)。将连续的一对文本序列作为正例,随机匹配的一对文本序列作为负例,构建二元分类任务,帮助模型理解序列间的关系
- 最终损失函数是掩蔽语言模型和下一句预测两个任务的交叉熵损失的线性组合

掩码(mask):使用特殊词元
<mask>替换掉原始词元
嵌入表示进阶
MRL,Matryoshka Representation Learning(原始论文,202205)
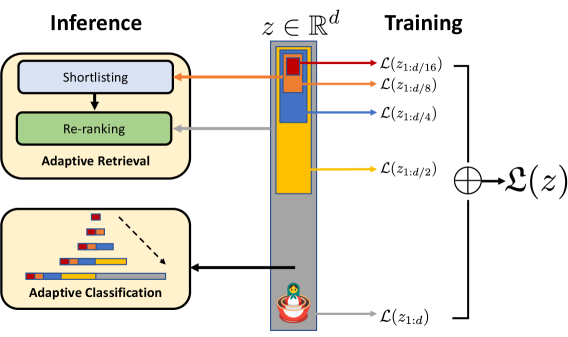
- 对多个嵌套式的低维向量进行显式优化,学习同一高维向量的不同嵌入表示
- MRL 基于有监督学习和额外的线性分类器来进行优化,不同维度的多嵌套低维向量分别进行预测结果,并组合为一个多分类问题,从而进行统一的参数优化
- MRL 可以通过这不同维度嵌入之间进行插值,来实现更灵活的维度转换;MRL 也支持不同模态的嵌入表示组合;MRL 可以通过权重共享的方式来减少内存开销并加速计算
其他:
参考:
Understanding the difference between Contextual Embeddings & Static Embeddings
LLM Embeddings Explained: A Visual and Intuitive Guide