1 图像识别的困难之处
Why object recognition is difficult
- 图像割裂:很难决定部件与物体的归属关系,物体和物体也存在重叠问题
- 光照:像素的亮度即会受到物体影响,也会受到光照影响
- 变形:物体可能有多个形态,比如阿拉伯数字2的多种写法。
- 分类的主观性:物体常常根据用途分类,同一个用途的物体常常有多种形态,比如各种椅子。
- 视角:旋转、左右、正反等等
- 样本误差:医疗数据中年龄一行错输入为体重?
2 保持视角固定
Ways to achieve viewpoint invariance
人类是如此擅长推断不同视角下的物体,以至于难以理解这对机器来说有多难。
让模型视角固定的几种方法
- 使用不随视角变换的特征(比如线的平行)
- 标注出物体的方向(费力不讨好啊)
- CNN中的池化pool(具体详见下一节)
3 卷积神经网络识别手写数字
Convolutional neural networks for hand-written digit recognition
3.1 权重共享
物体特征在图片中的位置是不固定的,所以同一个特征detector可以在不同位置反复使用,换个说法就是在不同位置的同一类detector,权重是共享的。权重共享将大幅度降低模型的训练成本。
- 确保初始化的时候相同
- 确保权重更新的时候相同-用共享权重的梯度之和来同时更新共享权重
- 不同位置的特征detector权重共享,使得模型具备了在不同视角下都能识别到特征的能力
3.2 池化 pooling
对相邻的多个detector的输出取平均或最大值
pooling优点:
- 减少下一层的输入维度,节省计算成本
- 腾出空间容纳更多类型的特征detector
如果想达到激活值上的不变性,正确的做法是池化(pooling),简单说就是把。这样的好处是到就少了,省出很多计算力去学习更多特征。
pooling缺点:
- 多层pool之后,特征的位置信息会丢失
- 比如识别人脸,你只要有鼻子有眼就行,模型不考虑你鼻子是不是在眼睛上面,而人与人相貌的区别很大程度上就取决于五官的距离
3.3 LeNet
Yann LeCun和他的伙伴发明的一种神经网络,对手写数字识别具有极高的精准度
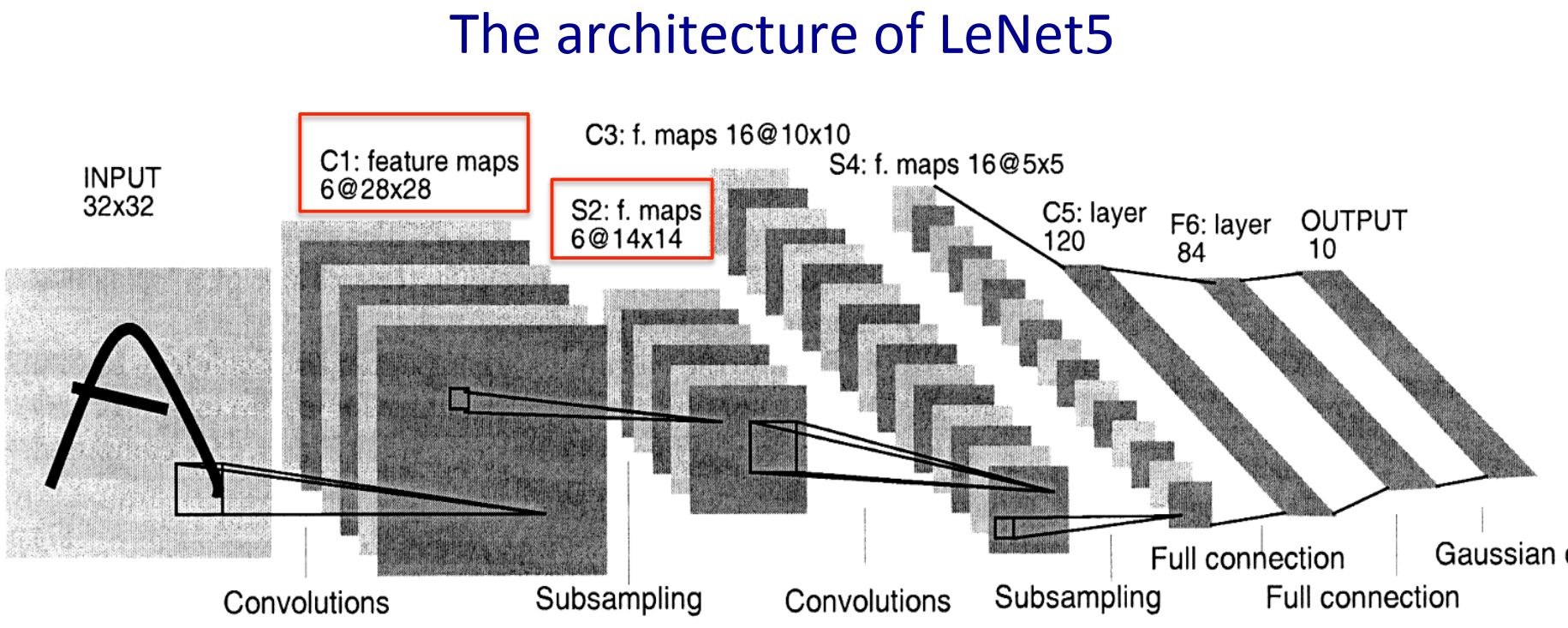
模型特点:
- 隐藏层很多
- 有很多权重共享和池化
- 当时的模型预测精度已经接近人类水平了
- 最终模型错了大概82个,而正常人一般错20-30个
- 此类模型最大的优势便是通过设计网络结构、权值约束、激活函数取代了特征detector的人工设计
模型改进:
- 2010年,Ciresan通过图像变换丰富了训练集样本
- 并基于GPU采用了更大、更深的网络进行神经网络的训练
- 最终将模型出错数降低到了35个,这种方法在未来将成为一种新趋势(这句话真是一语中的!)
3.4 McNemar检验
McNema检验是一种列联表的同质性检验
- 原假设:分类器在测试集上具有相似的错误比例。
不关注模型之间的错误差异,只是关注模型之间错误比例的相对偏差
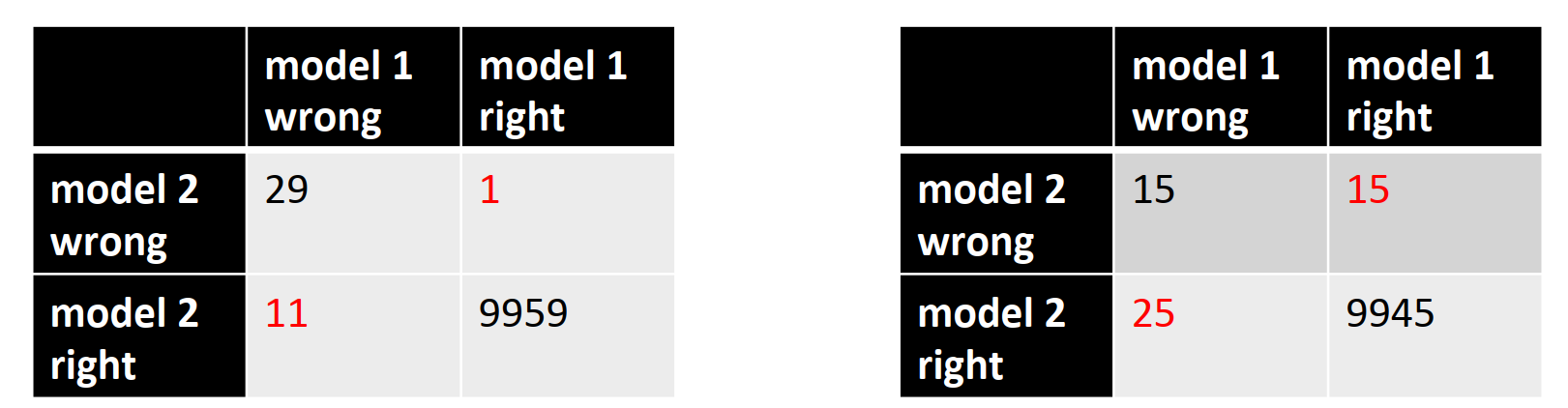
上图左侧,模型2对模型1错的次数显著大于模型2错模型1对的次数,所以模型2比模型1显著地好。而第二个案例则不是。
4 卷积神经网络用于目标检测
Convolutional neural networks for object recognition
4.1 ImageNet
在基于ImageNet的ILSVRC-2012比赛中,主要有两种任务:
- 分类:一种1000个分类,主要正确类别在预测的Top5里面就行
- 定位:返回检测框,至少与实际物体框存在50%的重叠
比赛最终排名:

优胜方案
- 方案来自University of Toronto (Alex Krizhevsky)
- 不考虑pooling,隐藏层数为7,前部分为卷积层,最后2层为全连接层
- 激活函数为relu,隐藏层通过正则化,增加模型稳健性
- 通过数据反转等方式进行数据增强,还有dropout
- 硬件配置为两块Nvidia GTX 580 ,通过GPU进行硬件加速矩阵运算、高带宽,整个训练过程只耗费了一个星期,测试也很快。
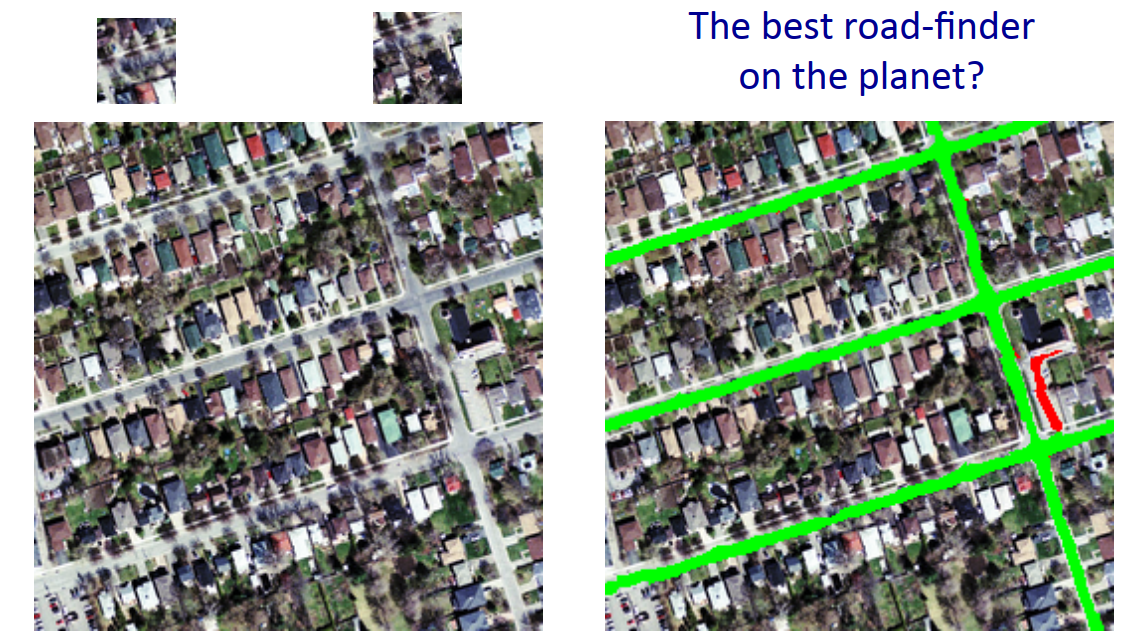
4.2 道路识别
另一个CNN的应用是在高分辨率的航拍图上识别道路,这个任务也很难,因为存在车辆、光影、摄像机视角等干扰因素。
CNN也能做得不错: