1 Hessian-Free 优化概述
A brief overview of “Hessian-Free” optimization
1.1 最大的误差减小量
The maximum error reduction
对于一个误差曲线来说,可以找到一个方向,实现最大的误差减小量
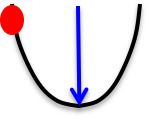
- 假设误差曲线是碗状凸函数,而上图为曲线的一个纵切面,并且曲率为常数,其中横轴表示权重,纵轴表示误差值
- 从红点出发能够获得该曲线切面的最大的误差减小量,即蓝色箭头
- 误差的最大减小量取决于梯度与曲率的比值,不同的方向梯度与曲率都可能不一样
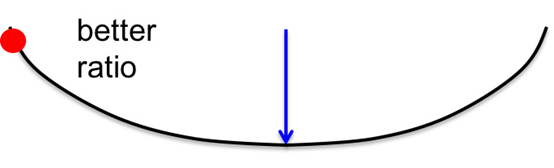
- 上图为误差曲线从另一个方向做的切面
- 此切面的梯度偏小,但曲率相比来说更小,因此二者比值反而更大
- 此切面的最大误差减少量更多,因此是更优的梯度下降方向
1.2 牛顿迭代法
Newton’s method
- 对于二次型误差曲线来说,梯度指向了最陡峭的方向,但这个方向并不意味着是最优的(误差下降最多的)
- 当误差曲线为圆形的时候,梯度指向了最优的方向,所以可以考虑通过线性变换,将误差曲线转化为圆形,而这就是牛顿迭代法的思路
牛顿迭代法 $$\Delta w =-\epsilon H(w)^{-1}\frac{dE}{dw}$$
- 其中$\epsilon$表示移动步长(学习速率)
- $E$表示误差,$w$表示可训练参数
- $H(w)^{-1}$ 表示海森矩阵(曲率矩阵)的逆
关于牛顿迭代法的更多细节可参阅1 牛顿迭代法
这里还是不太理解牛顿迭代法是如何将误差曲线转化为圆形的 应该需要额外的最优化相关基础 #待补充
1.3 如何避免对大矩阵求逆
How to avoid inverting a huge matrix
当可训练参数的维度达到百万级时,曲率矩阵所包含的元素个数将是万亿级别的
因此一个合理的思路是使用曲率矩阵的近似计算,这类方法也被成为Hessian-Free 算法
共轭梯度法是一种常见的Hessian-Free 算法,通过迭代式搜索共轭方向来寻找最优解
2 基于乘积连接的文本序列建模
Modeling character strings with multiplicative connections
本小节将应用RNN构建字符预测模型
2.1 字符级文本建模的优势
Modeling text: Advantages of working with characters
- 字符是互联网文本的基本构成单位
- 当算法足够强大时,字符能够提供足够的信息
- 字符(英文常用字符数是86)的数量远少于词语(英文常用词语数是10w+)
- 词语级的文本处理是个天坑(切词、语素、时态、缩写、歧义、黏着语等)
使用字典树来表示所有字符串,字典树的部分图示如下:
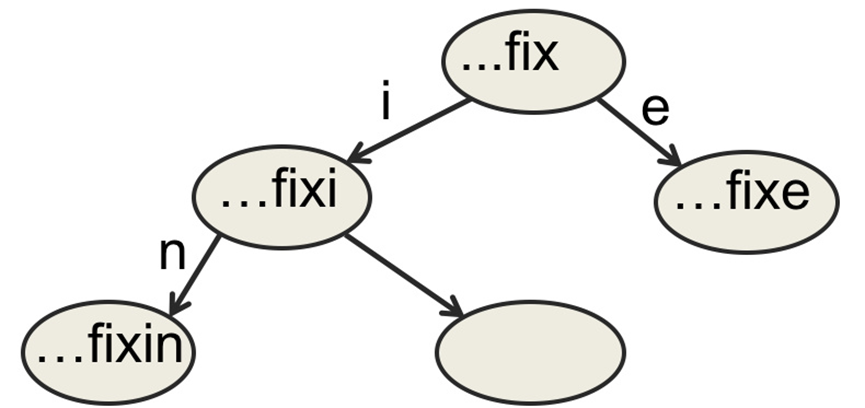
- 随着字符串的最大长度$N$的增加,树节点会呈现指数式增长
- 假设仅考虑86种字符,字典树的空间复杂度为$O(86^N)$
在字典树中,不同字符串间的信息是固定的。而在RNN中的隐状态中,这种不同字符间的结构信息是可以共享的。比如ing这个后缀往往接在动词后面,而不仅限于接在fix这个词后面
假设RNN的任务是根据输入字符串判断下一个字符。那么给定输入
fixi后,RNN会根据输入和隐藏状态给出合理的输出,所以当隐藏状态储备知识包含”这个输入很像是一个动词“,”一般动词后经常跟ing“这两点时,模型就很容易得出后两个字符是ng这一推断
2.2 乘积连接
Multiplicative connections
直接使用全连接层汇总信息时,参数量过高,也容易出现过拟合的问题
因此本小节提出了基于因子(factor)的乘积连接:
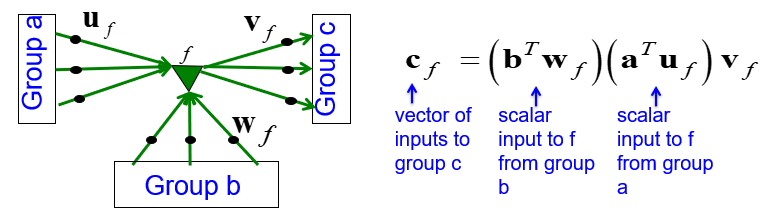
- 上图中,绿色三角形表示因子,每个因子是输入(a/b)的加权求和
- 不同因子相乘后,再通过一个权值向量$v_f$得到最终的输出
- 为方便理解乘积连接的含义,对上图(右侧)公式进行变换: $$c_f=(b^Tw_f)(u_fv_f^T)a$$
- 其中$b^Tw_f$为标量系数,$u_fv_f^T$为秩为1的变换矩阵,二者共同构成了从$a$到$c$的变换矩阵
此处可以理解$a$为当前字符输入,$b$为历史隐藏信息,$c$为要预测的下一个字符
3 使用HF训练字符预测模型
Learning to predict the next character using HF
3.1 训练与预测
训练过程说明:
- 使用了的500万条来自维基百科的语料,每条语料长度为100个字符
- 对于每个字符串,从第11个字符开始预测(不然历史信息太少,预测精度低)
- 使用HF optimizer 优化模型,使用GPU训练一个月才能得到一个不错的模型
- 最终RNN是表现最好的单模型(多模型的组合效果会更好)
- RNN的工作方式与其他模型不同,能更好的利用到中长期的历史信息
模型预测流程:
- 首先需要重置已经经过预训练的RNN模型的隐藏状态(清空历史信息)
- 给定一段字符串(前10个字符)用于模型的隐藏状态更新
- 进行下一个字符的预测,输出86种字符类型的概率分布
- 根据分布抽样得到一个字符,并作为下次的输入字符
- 重复以上过程,完成字符级的文本生成过程
复习到这里又联想起了最近混得风生水起的ChatGPT,突然有种恍惚感
3.2 模型表现
生成文本示例:
"He was elected President during the Revolutionary War and forgave Opus Paul at Rome. The regime of his crew of England, is now Arab women's icons in and the demons that use something between the characters‘ sisters in lower coil trains were always operated on the line of the ephemerable street, respectively, the graphic or other facility for deformation of a given proportion of large segments at RTUS). The B every chord was a "strongly cold internal palette pour even the white blade.”"
- 存在几处比较明显的错误,比如错误人名
Opus Paul at Rome,错误的单词拼写ephemerable,错误的标点符号RTUS) - 除此之外,文本整体还算合理,标点符号也运用得当
其他测试表现总结:
- 随着训练次数的增加,模型的输出文本合理性和流畅度逐渐增强
- 模型掌握了大量高频单词,包括专用名称、日期和数字等
- 基本掌握了引号和括号的用法,对语法/句法有一定了解但没能掌握知识的表现形式/规则(生成文本中仍然存在问题,最多算是有一点语感)
- 了解一些语义相关性,比如认为卷心菜和蔬菜之间存在关系
- 相比于前馈神经网络,RNN训练次数更少,模型表现更出色
4 回声状态网络
Echo state networks,ESN
4.1 回声状态网络定义
回声状态网络可以看作一种特殊的前馈神经网络:
- 神经网络的前几层随机初始化并固定,而模型训练只更新最后一层参数
- 网络前几层实现了对输入向量的变换(相当于固化输入层到隐藏层)
- 神经网络的隐藏层维度更高时,模型效果更好(优于普通前馈神经网络)
- 模型表现一方面依赖于最后一层参数对隐藏层的解释输出,另一方面依赖于前几层网络权值更合理的随机初始化
RNN也可以看作输入层与隐藏层之间共享的前馈神经网络,同时隐藏层(隐藏状态)是随机初始化
回声状态网络随机初始化的细节:
- 令随机矩阵的谱半径为1(即特征向量的最大长度为1),这样输入信息能够在隐藏层之间更持久的传递(像回声一样反复,而不至于放大震荡或消散)
- 注意使用稀疏连接(即大部分的参数随机初始值设为0),效果类似于松耦合的振荡器(loosely coupled oscillators)。确保输入信息不容易扩散,而是更为集中地传播到下一个时间戳
- 合理选择输入层到隐藏层之间的参数值,在驱动松耦合的振荡器(loosely coupled oscillators)时,不清除已有的历史信息
- 网络的训练速度很快,因此很多随机值和超惨都可以快速反复调试
4.2 回声状态网络示例
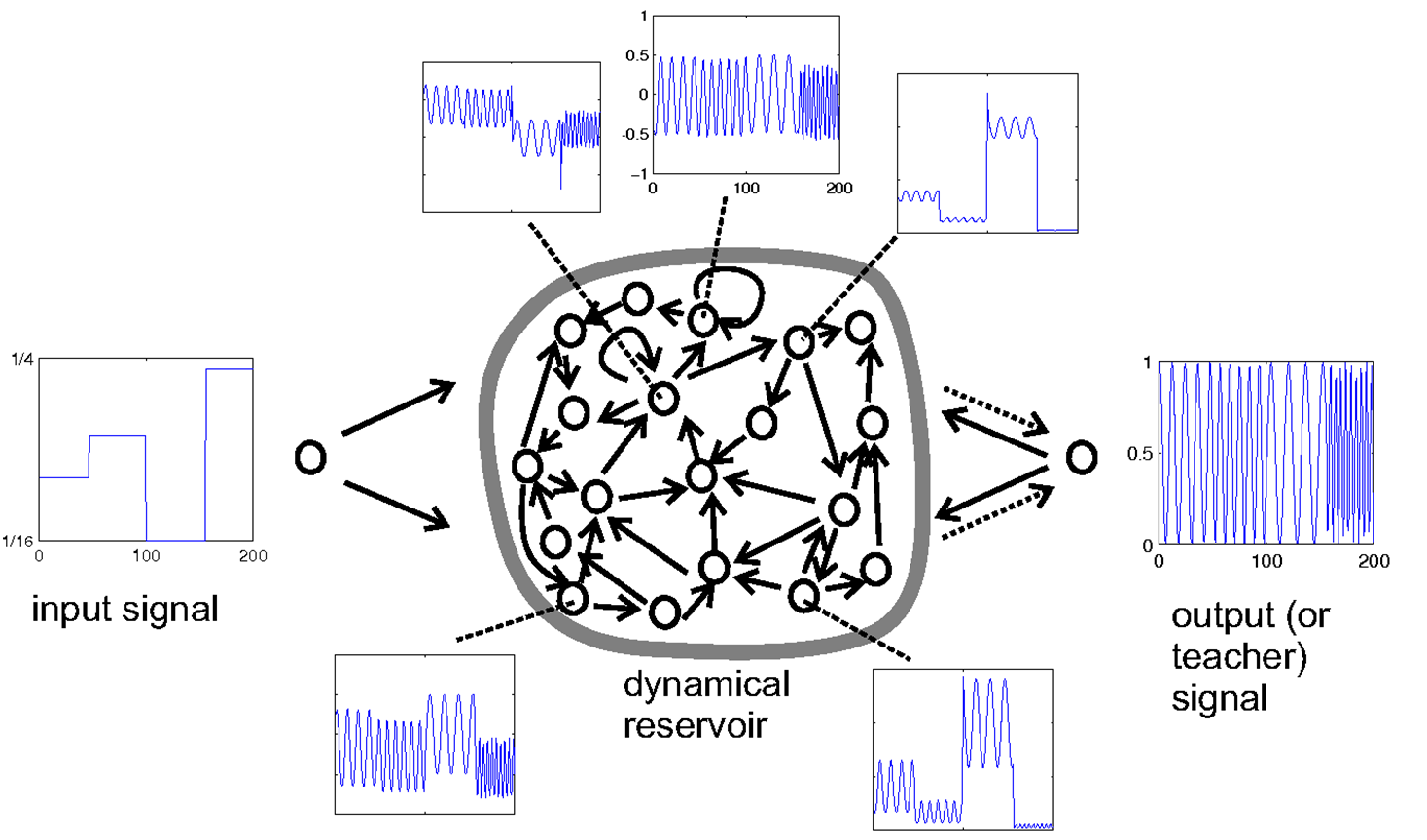
- 输入序列是一个脉冲波,输出则是正弦波;二者频率相同
- 网络中间是各种随机初始化的隐藏层(dynamical reservoir)
此处建模相当于一个从脉冲波(student)到正弦波(teacher)的还原过程
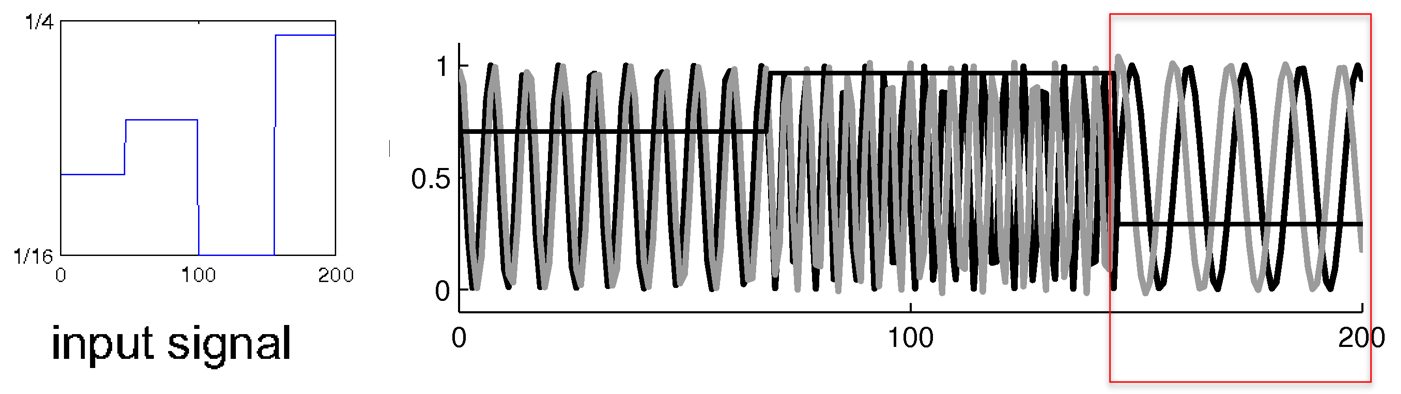
- 模型一开始实现了正确的预测,即正弦波频率和相位都是匹配的
- 但后半截还是存在一定的相位预测错误(即红色框住的区域),可能原因是对相位的范围缺乏概念
4.3 回声状态网络分析
回声状态网络的优点: • 训练速度快,因为只拟合线性模型 • 展示了权值初始化技巧的重要性 • 适合一维序列建模,但不擅长高维建模(比如语音识别)
回声状态网络的缺点: • RNN需要额外学习隐藏层间的参数,而ESN为了达到相等的性能表现则需要更多的隐藏单元(将输入进行稀疏高维表示) • 如果使用ESN的初始权值对RNN进行初始化,RNN的训练更高效(但需要注意,相关实验分析在训练中使用了动量法)