中文标题:结合字典对电子病历进行NER
英文标题:Named Entity Recognition Over Electronic Health Records Through a Combined Dictionary-based Approach
发布平台:Procedia Computer Science
发布日期:2016-01-01
引用量(非实时):89
DOI:10.1016/j.procs.2016.09.123
作者:Alexandra Pomares Quimbaya, Alejandro Sierra Múnera, Rafael Andrés González Rivera, Julián Camilo Daza Rodríguez, Oscar Mauricio Muñoz Velandia, Angel Alberto Garcia Peña, Cyril Labbé
文章类型:journalArticle
品读时间:2022-01-13 13:47
1 文章萃取
1.1 核心观点
采用了三种基于规则的简单方法针对电子病历进行命名实体提取,包括直接匹配、模糊匹配、词干匹配,并且探讨了三种方式的结合效果和不同阈值下的匹配效果
1.2 综合评价
- 基于规则的匹配,朴素简单,缺少新意
- 对比采用的数据集和调参过程可以作为参考
1.3 主观评分:⭐⭐⭐
2 精读笔记
2.1 三种NER方法
$G$为字典,$G'$为$G$转化所得的词干(stemmed)字典 $DocX$为待抽取文本,$DocX'$为$DocX$通过词干转换所得的文本
方法1:直接根据词典进行精准匹配
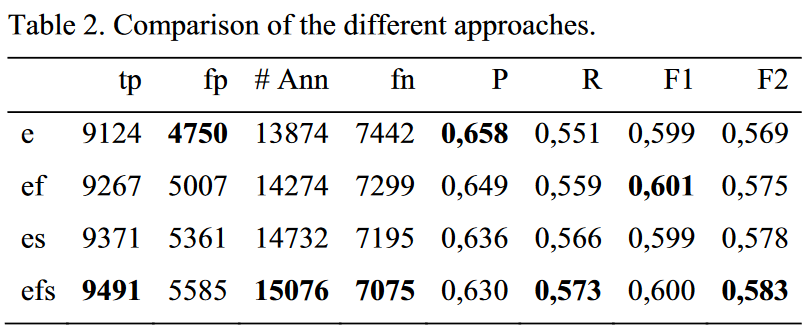
方法2:根据词典进行基于距离的模糊匹配(在本文中,距离的计算是计算字母的差异数,阈值设定为0.25,即对于长度为9单词来说,最多可以容忍2个字母的误差)
方法3:把字典和待抽取文本中的单词抽取为词干,然后进行匹配
2.2 实验结论
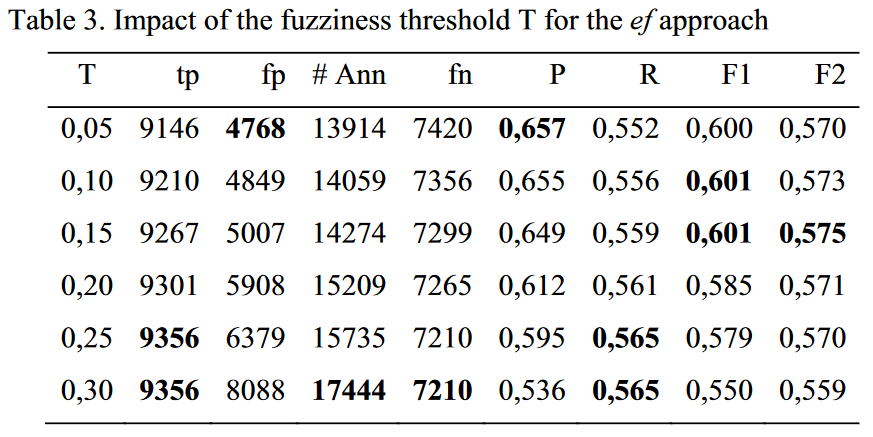
$e,f,s$分别表示精准匹配、模糊匹配、词干匹配
不同阈值$T$对应的模型精度如下: