本文聚焦于整理汇总chatGPT引发AI热潮后,各研究机构开源的模型
收录条件:代码与模型最好都开源,部署要求低(消费级显卡)
20231012更新:发现了一个内容类似的开源项目
Awesome-Chinese-LLM:整理开源的中文大语言模型,以规模较小、可私有化部署、训练成本较低的模型为主,包括底座模型,垂直领域微调及应用,数据集与教程等
1 底层通用大模型
1.1 LLaMA 42.3K⭐
Meta发布的大语言模型:
- 在公共开源预训练数据上训练,并且模型也已经开源
- 包括四个不同版本(参数量)模型:7B、13B、33B、65B
- 13B模型的效果超于GPT3;65B模型处于顶尖水平
- 推理效率高,占用显存小;最低只需要8G显存
- 第三方测试结果显示,对中文支持不友好
22年7月份Meta推出了性能更强劲的LLaMA2
22年9月份TinyLlama项目开始训练1.1B的Llama模型 2.7K⭐
更多LLaMA的衍生模型:
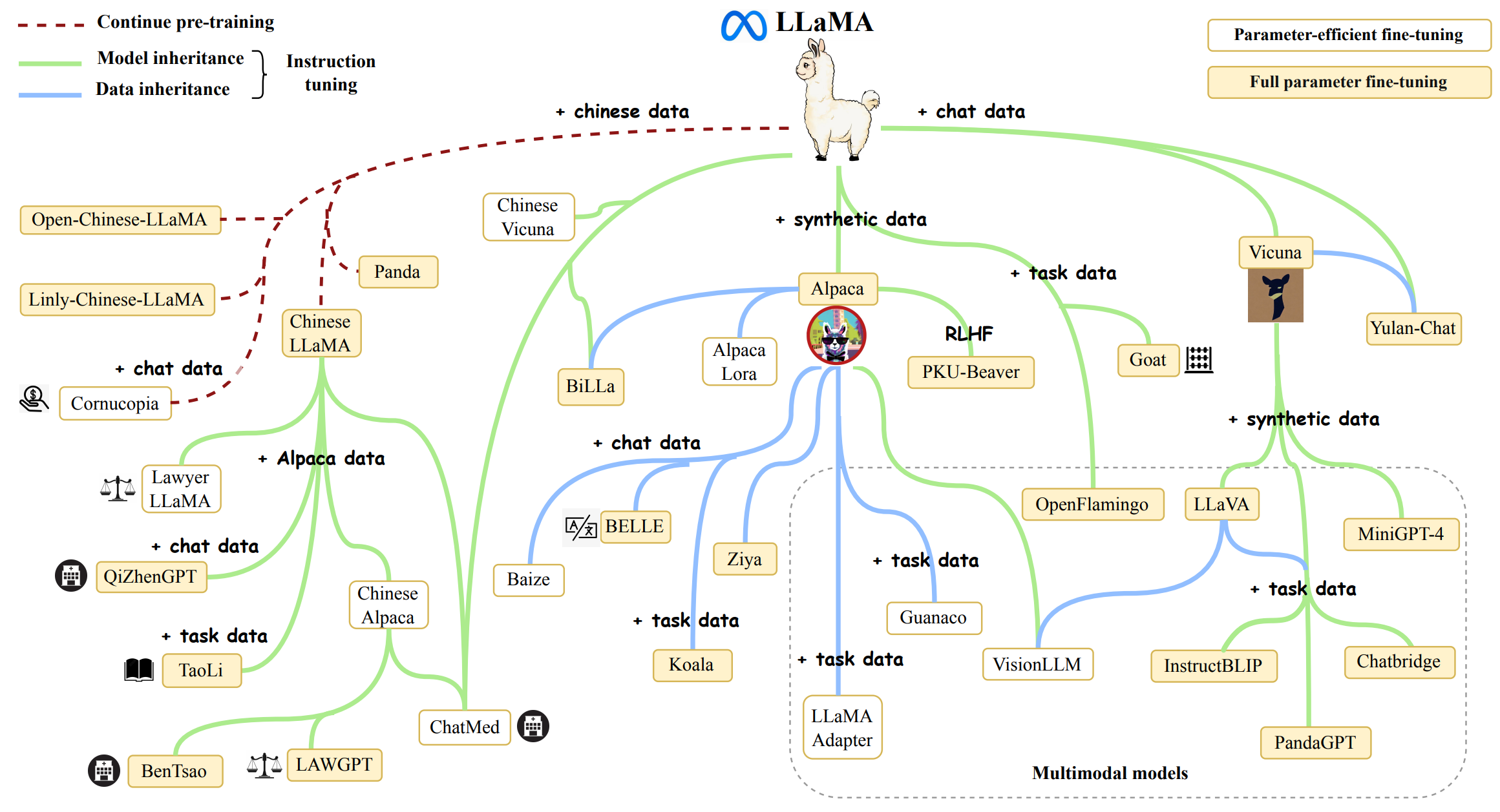 图源
图源
1.2 ChatGLM 34.4K⭐
清华开源的、支持中英双语的对话语言模型:
- 技术与ChatGPT相似,Transform辅以监督微调、反馈自助、人类反馈强化学习等技术
- 训练使用约1TB的中英双语数据,针对中文问答和对话进行了优化
- 结合模型量化技术,对部署要求低(最低只需6GB显存)
- 目前开源的ChatGLM-6B包含62亿参数,效果受到规模约束
1.3 Alpaca中文版 14.7K⭐
- 针对原版LLaMA模型扩充了中文词表,提升了中文编解码效率
- 开源了使用中文文本数据预训练的中文LLaMA以及经过指令精调的中文Alpaca
- 开源了预训练脚本、指令精调脚本,用户可根据需要进一步训练模型
- 快速使用笔记本电脑(个人PC)的CPU/GPU本地量化和部署体验大模型
- 支持transformers, llama.cpp, text-generation-webui, LlamaChat, LangChain, privateGPT等生态
- 目前已开源的模型版本:7B(基础版、Plus版、Pro版)、13B(基础版、Plus版、Pro版)、33B(基础版、Plus版、Pro版)
Alpaca-2:基于中文LLaMA-2的指令精调版本 4.1K⭐ LongAlpaca:基于LongLoRA的32k上下文版Alpaca 1.6K⭐
1.4 ChatRWKV 8.8K⭐
国人对标ChatGPT的开源项目:
- 目前已迭代4个版本,正在(230320)进行第5版的开发
- 基于RWKV架构,融合了rnn和Transform的特点与优势
- 目前已开源1.5/3/7B中文小说模型,推荐显存3~14G
ChatRWKV在线体验
ChatRWKV中文教程
CchatRWKV项目地址
ChatRWKV训练代码地址
1.5 BELLE 6.8K⭐
BELLE(Bloom-Enhanced Large Language model Engine)
- 开源的中文对话模型,参数量为70亿
- 在羊驼(Alpaca)的基础上进行了中文优化
- 目前数据、代码与模型都已开源,性能表现看起来还不错
1.6 通义千问 4K⭐
通义千问-7B(Qwen-7B) 是阿里云研发的通义千问大模型系列的70亿参数规模的模型,其架构类似于 LLaMA 系列模型。它使用来自公开数据的超过 2.2 万亿个令牌和 2048 个上下文长度进行了预训练,涵盖一般和专业领域,重点关注英语和中文
1.7 书生·浦语 InternLM 3.4K⭐
InternLM 是一个开源的轻量级训练框架,旨在支持大模型训练而无需大量的依赖。通过单一的代码库,它支持在拥有数千个 GPU 的大型集群上进行预训练,并在单个 GPU 上进行微调,同时实现了卓越的性能优化。在1024个 GPU 上训练时,InternLM 可以实现近90%的加速效率。
基于InternLM训练框架,我们已经发布了两个开源的预训练模型:InternLM-7B 和 InternLM-20B
1.8 百川Baichuan 2.6K⭐
Baichuan-13B 是由百川智能继 Baichuan-7B 之后开发的包含 130 亿参数的开源可商用的大规模语言模型,在权威的中文和英文 benchmark 上均取得同尺寸最好的效果
1.9 MiniCPM 1.9 K⭐
MiniCPM 是面壁智能与清华大学自然语言处理实验室共同开源的系列端侧大模型,主体语言模型 MiniCPM-2B 仅有 24亿(2.4B)的非词嵌入参数量。
- 经过 SFT 后,MiniCPM 在公开综合性评测集上,MiniCPM 与 Mistral-7B相近(中文、数学、代码能力更优),整体性能超越 Llama2-13B、MPT-30B、Falcon-40B 等模型。
- 经过 DPO 后,MiniCPM 在当前最接近用户体感的评测集 MTBench上,MiniCPM-2B 也超越了 Llama2-70B-Chat、Vicuna-33B、Mistral-7B-Instruct-v0.1、Zephyr-7B-alpha 等众多代表性开源大模型。
- 以 MiniCPM-2B 为基础构建端侧多模态大模型 MiniCPM-V,整体性能在同规模模型中实现最佳,超越基于 Phi-2 构建的现有多模态大模型,在部分评测集上达到与 9.6B Qwen-VL-Chat 相当甚至更好的性能。
- 经过 Int4 量化后,MiniCPM 可在手机上进行部署推理,流式输出速度略高于人类说话速度。MiniCPM-V 也直接跑通了多模态大模型在手机上的部署。
- 一张1080/2080可高效参数微调,一张3090/4090可全参数微调,一台机器可持续训练 MiniCPM,二次开发成本较低。
2 垂直领域大模型
编程:
- Code Llama:22年8月份Meta推出的Llama2代码能力增强版本 9.7K⭐
- SQLCoder:15B参数模型(接近GPT3.5),将自然语言问题转换为 SQL 查询 1.3K⭐
- CodeShell:7B开源多语言代码大模型底座,有配套的IDE插件 68⭐
医疗:
- DoctorGPT:基于Llama2 70B模型的医疗微调,可通过美国医生执照考试 3.4k⭐
- DISC-MedLLM:基于Baichuan-13B的医疗健康对话场景的开源大模型 225⭐
3 大模型衍生工具
本地部署/搜索增强 LLMs:
- Ollama: 本地启动并运行大型语言模型 53.9k⭐
- LlamaIndex:基于本地笔记和 ChatGPT 的 embedding 构建个人知识库 21.6k⭐
- localGPT:使用 GPT 模型与本地文档对话(100%私密) 17.4k⭐
- llamafile:允许使用单个文件分发和运行 LLMs 12.8k⭐
- DocsGPT:与文档对话,简化搜索过程(有配套本地优化模型) 12.3k⭐
- AnythingLLM:高效、可定制、开源的企业级文档聊天机器人 10.7k ⭐
性能改善与优化:
- PowerInfer:使用消费级 GPU 提供快速大型语言模型推理 6.6 k ⭐
- Streaming LLM:将 LLM 泛化到无限序列长度的输入,而无需任何微调 5.1k ⭐
- ChatGPT AutoExpert:用于数据分析(编程)的ChatGPT指令优化 3.9k⭐
- Text Embeddings Inference:用于文本嵌入模型的超快推理解决方案 1k ⭐
笔记与科研:
- ChatPaper:全流程加速科研,总结+翻译+润色+审稿 16.1k⭐
- GPT Researcher:使用 GPT 对任何给定主题进行在线综合研究 4.6k⭐
医疗工具包:
- MONAI:基于PyTorch的医疗影像深度学习工具包 4.7k⭐
更多趣味 AI 工具或应用:趣味 AI 类工具网站
4 大模型训练工具
baby-llama2-chinese 1.5 k⭐:
- 24G 单卡从头预训练得到一个具备简单中文问答能力的 chat-llama2
LLaMA Factory:对 LLaMA 类模型进行快速微调训练和评估 7.1 k ⭐
补充
视频针对目前(2023-12-08)的十大主流模型进行评测
- 中文能力综合评测的测试维度包括基础能力、多语种泛化能力、多轮对话、知识准确性、文本生成、信息提取、JSON格式生成、函数调用,以及代码解释器能力
- 最终评分最高的是 GPT4(97),其次是文心4(77),Claude(73),通义千问(71),GPT3.5(69)
- 最终评分最低的是 文心3.5(39),其次是讯飞星火(42),腾讯混元(43),BIng(48),Bard(57)