中文标题:基于属性驱动的图注意网络对股票预测的动量溢出效应建模
英文标题:Modeling the Momentum Spillover Effect for Stock Prediction via Attribute-Driven Graph Attention Networks
发布平台:AAAI
Proceedings of the AAAI Conference on Artificial Intelligence
发布日期:2021-05-18
引用量(非实时):56
DOI:10.1609/aaai.v35i1.16077
作者:Rui Cheng, Qing Li
文章类型:journalArticle
品读时间:2024-01-16 16:24
1 文章萃取
1.1 核心观点
过往的动量溢出效应分析往往忽视了效应的时间敏感性(随着时间的推移,效应是动态变化的)和属性敏感性(比如低估值的公司更不容易受到股价下降的动量溢出效应的影响)。针对这两点问题,本文提出了改进模型。该模型会根据先融合文本特征和市场信号,并通过 RNN 得到股票的顺序嵌入表示。之后 AD-GAT 会进行隐式关系推理,并将推理图应用于融合了门控机制的 GCN 网络,得到股票的关系嵌入表示。最后通过串联顺序嵌入和关系嵌入来实现最终的股价预测
本文模型即考虑了市场信号的时序依赖性,也考虑了股票间的结构信息;最终回测结果表明,相比于其他基线,具备时间敏感性和属性敏感性的 AD-GAT 模型 DA 和 AUC 分别提高了至少 6.4% 和 10.7%,具备显著优越性
1.2 综合评价
- 综合考虑了新闻文本,市场信号,以及隐式推理得到的股票间关系
- 实验与评价方式单薄,缺少回报率的实盘回测和模型稳定性的评估
- 算法细节清晰,代码开源;整体思路具备较高的可行性和改进空间
1.3 主观评分:⭐⭐⭐⭐⭐
2 精读笔记
2.1 算法细节
动量溢出效应(Momentum Spillover Effect),又称为动量效应
- 指股票或其他资产的过去表现会对其未来表现产生影响
- 具体来说,如果一只股票在过去的一段时间内表现良好,那么它在未来的一段时间内可能会继续表现良好。反之,如果一只股票在过去的一段时间内表现糟糕,那么它在未来的一段时间内可能会继续表现糟糕
- 动量溢出效应在上市公司中的表现可能会更为明显,因为受到更多投资者的关注
- 有些研究发现,动量效应可能会在一段时间后消失,或者在某些市场条件下消失
本文模型的整体框架:
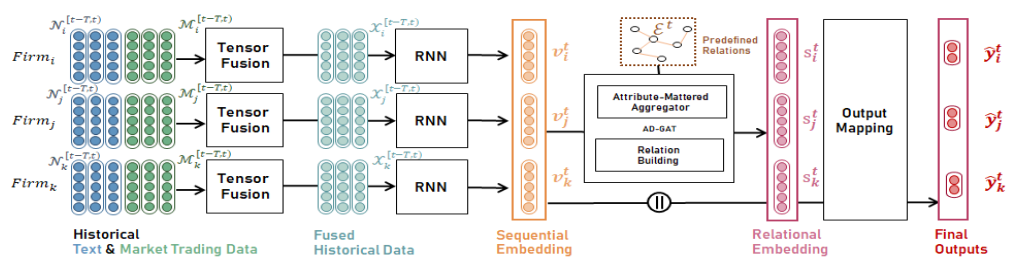
- 给定公司 $i$,先将技术指标 $m_i$ 和文本媒体特征 $m_i$ 合并到一个融合向量 $x_i$ 中:
$$ \mathbf{x}_i=tanh(\mathbf{m}_i\mathcal{T}_i^{[1:K]}\mathbf{n}_i+\mathcal{W}_i[\mathbf{m}_i||\mathbf{n}_i]+\mathbf{b}_i) $$
其中 $\mathcal{T}$ 是 $K$ 维可训练的三阶张量参数,用于捕获两个输入特征的相互关系;双线性张量积项中的第 $k$ 个条目计算方式为: $\mathbf{m}i\mathcal{T}_i^{k}\mathbf{n}=\sum{l\in L}\sum_{l^{\prime}\in L^{\prime}}T_{l,l^{\prime}}^{k}\mathbf{m}{i,l}\mathbf{n}{i,l^{\prime}}$。$\mathcal{W}$ 和 $b$ 也是可训练参数;$||$ 表示向量的串联
- 给定时间 $t$,过去 $T$ 天的每日融合向量被输入 RNN 模块以生成上市公司的顺序嵌入表示 $\mathbf{v}_i^t$:
$$ \mathbf{v}_i^t=RNN_i(\mathcal{X}_i^{[t-T:t)}),\ \ \ \mathcal{X}_{i}^{[t-T:t)}=[\mathbf{x}_{i}^{t-T},\ldots,\mathbf{x}_{i}^{t-1}] $$
- 所有上市公司的顺序嵌入以及预定义的关系由属性聚合器 (AM,Attribute-Mattered) 和关系构建 (RB,Relation Building ) 模块进一步处理,以针对收到溢出效应的上市公司代表生成关系嵌入 $s_i^t$
- 最后,顺序嵌入和关系嵌入的串联被输入输出映射(OM)模块以预测股票走势
$$ \hat{\mathbf{y}}_i^t=O_i(\mathbf{v}_i^t||\mathbf{s}_i^t)=softmax(\mathcal{W}_i^{\prime}[\mathbf{v}_i^t||\mathbf{s}_i^t]+\mathbf{b}_i^{\prime}), $$
算法细节 1:关系构建模块(Relation Building Module)
- RB 模块的主要作用是基于公司 $i$ 公司 $j$ 的顺序嵌入表示,得到二者的关联强度 $E_{i,j}$
$$ \begin{equation} \left\{ \begin{gathered} R_{i,j}^t=LeakyReLU(\mathbf{a}_{\mathbf{r}}^{\top}\mathcal{W}_r[\mathbf{v}_i^t||\mathbf{v}_j^t]) \ \\ E_{i,j}^t=softmax_j(R_{i,j}^t)=\frac{exp(R_{i,j}^t)}{\sum_{k\in N,k\neq i}exp(R_{i,k}^t)} \end{gathered} \right. \end{equation} $$
- RB 模块先根据注意力机制从时序顺序嵌入表示中推断不同企业间的关系,这样得到的关联强度是时间敏感的;同时为了确保可比性,使用 softmax 函数对最终的关系强度进行归一化处理
算法细节 2:属性聚合器 (Attribute-Mattered Aggregator)
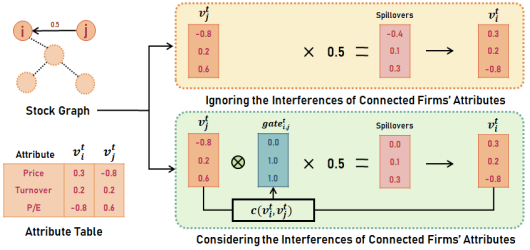
- 已知公司 $i$ 和公司 $j$ 间的关系强度为 $E_{ij}$,AM 模块将根据图关系得到属性敏感的关系嵌入表示
$$ \begin{equation} \left\{ \begin{gathered} \mathbf{s}_i^t=\sigma(\sum_{j,j\neq i}^N\underbrace{E_{i,j}\mathcal{W}_s\mathbf{v}_j^t\otimes c(\mathbf{v}_i^t,\mathbf{v}_j^t)}_{\text{spillovers from }j\mathrm{~to~}i}) \ \\ c(\mathbf{v}_i^t,\mathbf{v}_j^t)=tanh(\mathcal{W}_c[\mathbf{v}_i^t||\mathbf{v}_j^t]+\mathbf{b}_c) \end{gathered} \right. \end{equation}
$$
- AM 模块在 GCN 的基础上进行改进,融入了以 $v_i^t$ 和 $v_j^t$ 为输入的门控机制,这样公司间的关系嵌入表示将会受到公司本身的属性影响(比如低估值的公司,更不容易受到价格下降的动量溢出效应的影响)
实验分析
数据说明:
- 2011年2月8日至2013年11月18日期间标准普尔500指数
- 前 560 天用于训练,之后 70 天用于验证,最后 70 天用于测试
- 每日交易数据取自沃顿研究数据服务(WRDS)
- 文本为路透社和彭博社同期发表的财经新闻文章
评价指标:DA 准确率 (趋势预测正确的次数占比)、AUROC
多模型的评价对比:

- 相比于其他基线模型,本文模型的 DA 和 AUC 分别提高了至少 6.4% 和 10.7%
隐式关系推理 VS 五种预设的显式关系:

- 相比于五种预定义关系,推断隐式关系实现了最佳性能,DA 和 AUC 分别提高了至少 2.7% 和 6.2%
张量融合的有效性:

- 其中 C 表示只考虑串联信息;S 表示只考虑相互的关系信息