中文标题:GraphCare: 通过个性化知识图谱增强医疗保健预测
英文标题:GraphCare: Enhancing Healthcare Predictions with Personalized Knowledge Graphs
发布平台:ICLR
发布日期:2024-01-17
引用量(非实时):
DOI:
作者:Pengcheng Jiang, Cao Xiao, Adam Cross, Jimeng Sun
关键字: #GraphCare
文章类型:preprint
品读时间:2024-02-18 10:37
1 文章萃取
1.1 核心观点
GraphCare 是一个开放世界的框架,利用外部 KG 来改进基于 EHR 的预测。具体来说,GraphCare 从大型语言模型(LLMs/GPT 4)和外部生物医学知识图谱中提取知识,以生成特定于患者的知识图谱,然后将其用于训练基于双注意力增强(BAT)图神经网络(GNN)的医疗保健预测
实验分析表明,GraphCare 在四个重要的医疗预测任务中优于基线模型:死亡率、再入院、住院时间和药物推荐,将 MIMIC-III 上的 AUROC 平均提高分别为 10.4%、3.8%、2.0% 和 1.5%
1.2 综合评价
- 从两个不同就诊间和单次就诊内两个层次考虑注意力的计算,显著改善了模型性能
- 构建了多种形式的图,即包含了医疗概念的局部,也有面向患者的个性化知识图谱
- 借助 LLMs 进行了知识图的抽取,效果优于传统图的抽样(值得思考传统图的变革)
- 可以从更丰富的角度纳入更多的医疗实体,建立更全面的数据视角来辅助模型学习
1.3 主观评分:⭐⭐⭐⭐⭐
2 精读笔记
2.1 算法细节
整体框架设计:
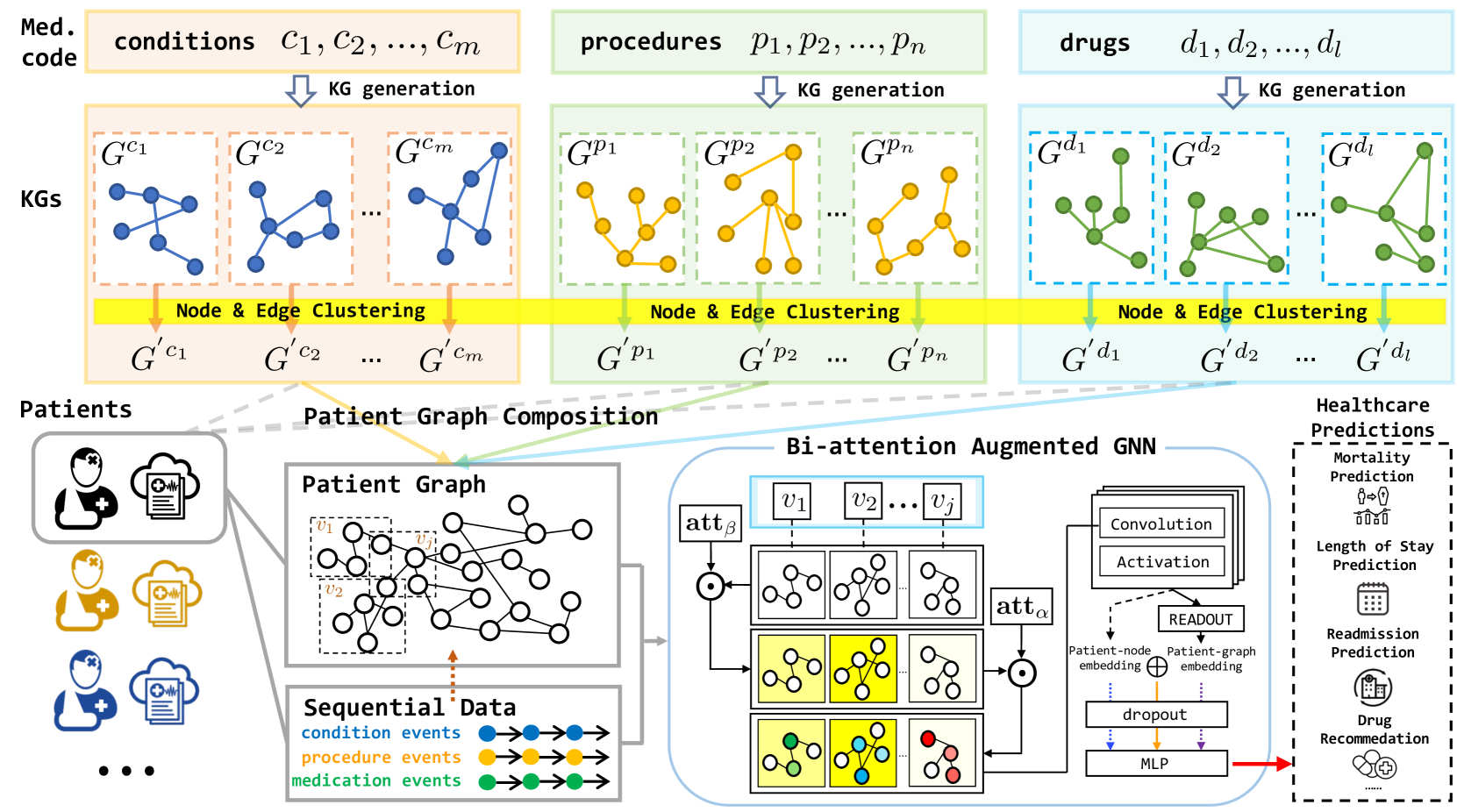
- 通过 LLMs 从文本中抽取三元组或从现有知识图(KG)中进行采样的方式,针对数据集中的每个医疗概念(诊断 conditions、治疗措施 procedure、药物 drug)生成一个特定的 KG
- 使用聚合方法,将所有医疗概念子图的进行节点或边的聚类,得到全局的知识图
- 根据每个患者的诊治流程,为每位患者构建个性化的 KG(三元组序列)
- 基于个性化知识图谱应用双注意力增强 (BAT) 的图神经网络 (GNN) 实现医疗预测
2.1.1 知识图的生成
患者的诊治流程与相关医疗概念:
 针对特定概念的知识图生成主要有两种方式:
针对特定概念的知识图生成主要有两种方式:
- 借助 GPT 4 直接生成并收集知识三元组,相应的 Prompt 示例如下:

- 从英文医疗知识图谱 UMLS 中进行随机采样,选择对应实体的 k 跳子图

聚合医疗概念子图,初始化不同节点和边的全局嵌入表示:
- 借助凝聚聚类算法根据词嵌入(from GPT 3)的余弦相似性聚合节点和边
- 最终每个节点/边的初始嵌入表示是每个聚合后簇内所有相似节点/边的嵌入均值
- 知识图的三元组示例:
[结核病,治疗方式,抗生素],[结核病,影响,肺]
根据全局化后的概念子图构建患者的个性化知识图:
- 假如患者 $i$ 在诊治过程中,产生了 $J$ 条包含医疗概念实体的就诊记录
- 拼接每个实体对应的概念子图后,患者 $i$ 的访问子图可以表示为
$$G_{pat(i)}={G_{i,1},G_{i,2},...,G_{i,J}}={(V_{i,1},E_{i,1}),...,(V_{i,J},E_{i,J})}$$
其中 V 和 E 分别表示不同医疗概念子图的节点和边
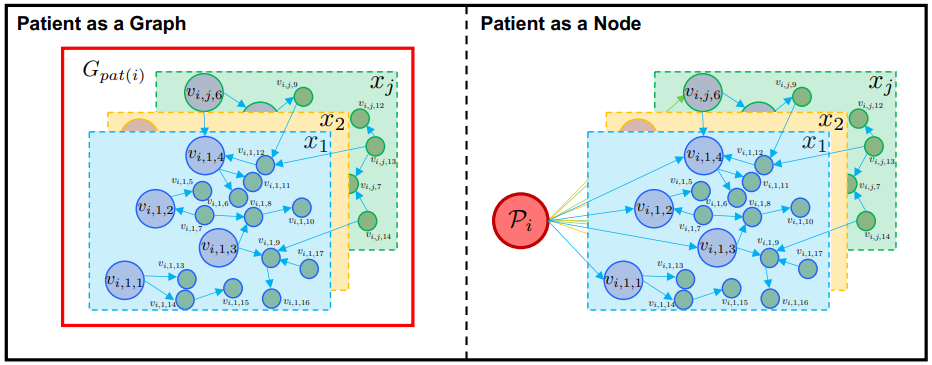
2.1.2 双注意力增强的图神经网络
首先将词嵌入表示转化为隐藏嵌入,减少节点和边嵌入的大小,以提高模型的效率并处理稀疏问题。其中第 $i$ 个患者在第 $j$ 次就诊记录中的第 $k$ 个实体的节点和边嵌入转化公式如下: $$ \mathbf{h}_{i,j,k}=\mathbf{W}_{v}\mathbf{h}_{(i,j,k)}^{\mathcal{V}}+\mathbf{b}_{v}\quad ;\quad \mathbf{h}_{(i,j,k)\leftrightarrow(i,j^{'},k^{'})}=\mathbf{W}_{r}\mathbf{h}_{(i,j,k)\leftrightarrow(i,j^{'},k^{'})}^{\mathcal{R}}+\mathbf{b}_{r} $$
- 其中 $W$ 和 $b$ 均为可学习的网络参数;
- $(i,j,k)\leftrightarrow(i,j^{'},k^{'})$ 表示节点 $(i,j,k)$ 到节点 $(i,j^{'},k^{'})$ 之间的边
- $\mathbf{h}^{\mathcal{V}}_{(i,j,k)}$ 表示节点的原始嵌入;$\mathbf{h}_{(i,j,k)}$ 表示节点的隐藏嵌入
- $\mathbf{h}_{(i,j,k)\leftrightarrow(i,j^{'},k^{'})}^{\mathcal{R}}$ 表示边的原始嵌入;$\mathbf{h}_{(i,j,k)\leftrightarrow(i,j^{'},k^{'})}$ 表示边的隐藏嵌入
然后根据边和关系的隐藏嵌入,模型从 2 种层次分别计算注意力,注意力 $\alpha$ 针对同一次就诊记录中的不同实体(诊断/治疗/用药)进行重要性评估(node-level);注意力 $\beta$ 针对不同的就诊记录进行重要性评估(subgraph-level)。二者的计算公式如下: $$ \begin{aligned}\alpha_{i,j,1},...,\alpha_{i,j,M}&=\text{Softmax}(\mathbf{W}_{\alpha}\mathbf{g}_{i,j}+\mathbf{b}_{\alpha}), \\\beta_{i,1},...,\beta_{i,N}&=\lambda^\top\text{Tanh}(\mathbf{w}_{\beta}^\top\mathbf{G}_i+\mathbf{b}_{\beta}),\quad\text{where}\quad\lambda=[\lambda_1,...,\lambda_N]\end{aligned} $$
- $\alpha_{i,j,k}$ 描述了患者 $i$ 的第 $j$ 次就诊记录的第 $k$ 个节点的重要性,$M$ 是全局的节点数
- $g_{i,j}$ 是患者 $i$ 的第 $j$ 次就诊记录对应子图的多热(multi-hot)向量表示
- $\beta_{i,j}$ 描述了患者 $i$ 的第 $j$ 次就诊记录的权重重要性,$N$ 是患者的最大就诊次数
- $\lambda$ 是时间衰减系数; $G_i$ 是患者 $i$ 的访问子图(所有就诊记录)的多热向量表示
双注意力增强 (BAT) 层通过聚合所有访问子图中的相邻节点来更新节点嵌入: $$ \mathbf{h}_{i,j,k}^{(l+1)}=\sigma\left(\mathbf{W}^{(l)}\sum_{j^{\prime}\in J,k^{\prime}\in\mathcal{N}(k)\cup{k}}\left(\underbrace{\alpha_{i,j^{\prime},k^{\prime}}^{(l)}\beta_{i,j^{\prime}}^{(l)}\mathbf{h}_{i,j^{\prime}}^{(l)},k^{\prime}}_{\text{Node aggregation lerm}}+\underbrace{\mathrm{w}_{\mathcal{R}(k,k^{\prime})}^{(l)}(i_{i,j,k^{\prime})\leftrightarrow(i,j^{\prime},k^{\prime})}}_{\text{Elge aggregation lerm}}\right)+\mathbf{b}^{(l)}\right) $$
节点聚合项捕获了注意力加权节点的贡献,而边聚合项表示连接节点的边的影响。该卷积层集成了节点和边缘特征,使模型能够学习患者 EHR 数据的丰富表示
假设经过 L 层 BAT 后的节点嵌入表示为 $\mathbf{h}_{i,j,k}^{(L)}$,而患者 $i$ 的最终嵌入表示有以下三种形式: $$ \begin{aligned} z_i^{graph}&=MLP(\mathbf{h}_i^{G_{pat}})=MLP(\text{MEAN}(\sum_{j=1}^{J}\sum_{k=1}^{K_j}\mathbf{h}_{i,j,k}^{(L)})) \\ z_i^{node}&=MLP(\mathbf{h}_i^{G_{p}})=MLP(\text{MEAN}(\sum_{j=1}^{J}\sum_{k=1}^{K_j}1^{\Delta}_{i,j,k}\mathbf{h}_{i,j,k}^{(L)})) \\ \mathbf{z}_i^{\mathrm{joint}}&=\mathrm{MLP}(\mathbf{h}_i^{G_{pat}}\oplus\mathbf{h}_i^{\mathcal{P}})\end{aligned}
$$
患者 $i$ 的最终嵌入表示,可以来自患者所有就诊记录的节点嵌入均值 $\mathbf{h}_i^{G_{pat}}$,也可以来自所有与患者直接相关的节点嵌入均值 $\mathbf{h}_i^{G_{p}}$,还可以是以上二者的综合
训练模型的四种预测任务:
- 死亡预测(MT):二分类任务
- 15 天内再入院预测(RA):二分类
- 住院时长预测(LOS):多分类(8 表示 1~2 周,9 表示 2 周以上)
- 药物推荐(Drug recommendation):多标签
最终损失函数为二元交叉熵损失+交叉熵损失(公式略)
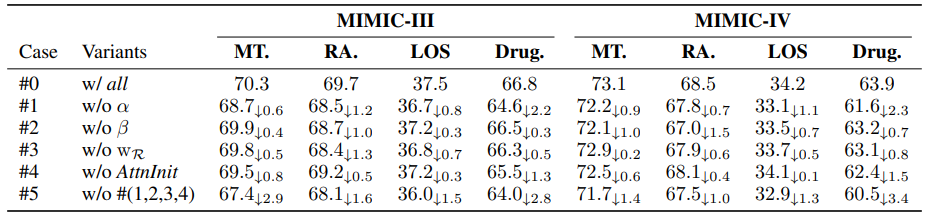
本文模型中还使用了权重初始化技巧,主要思想是根据不同节点嵌入与特定任务关键词(如"死亡")对应嵌入间的余弦相似度,来初始化该节点对应的权重。此处不再赘述细节。
后续实验表明:该方法有助于模型的快速收敛,并改善了最终模型在不同任务上的性能
2.2 实验分析
数据说明:
- 根据 GPT4+提示,生成了42,056个实体、9,404种关系、85,387个三元组
- 通过已有 KG 中抽样,生成了82,628个实体、80种关系、247,069个三元组
- EHR 数据主要考虑公开的 MIMIC-III 和 MIMIC-IV 数据集

评价指标:准确率、F1、Jaccard 相似度、AUPRC、AUROC、Kappa 一致性
不同任务不同模型的表现:
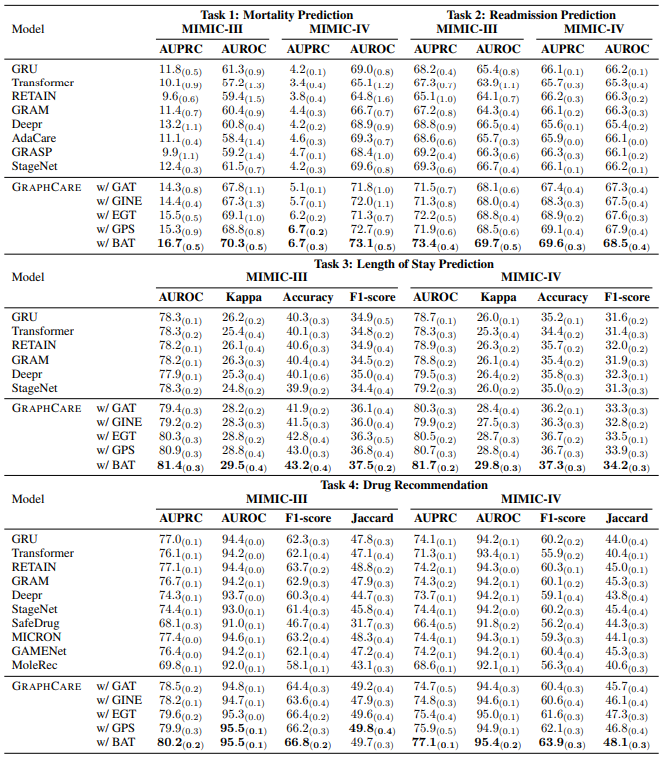
- 每个模型在 MIMIC-III 运行> 100 次和 MIMIC-IV 运行> 50 次以计算均值和标准差
- 基于 BAT 层的 GraphCare 模型在不同任务、不同数据上均表现出色,超过其他 baseline
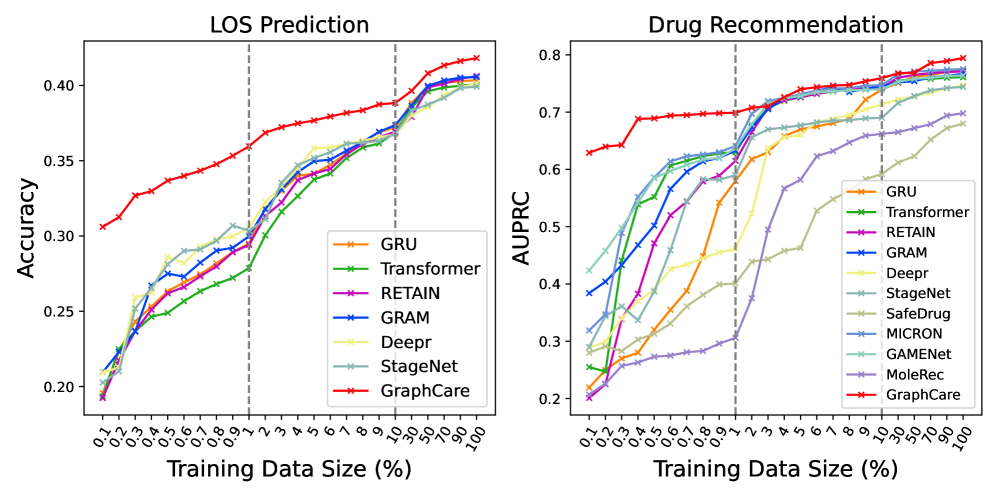
训练样本量分析:GraphCare 达到同样的性能所需样本量远少于其他模型
不同知识图谱的效用分析:GPT4 生成的 KG 作用比 UMLS 抽样子图的作用好
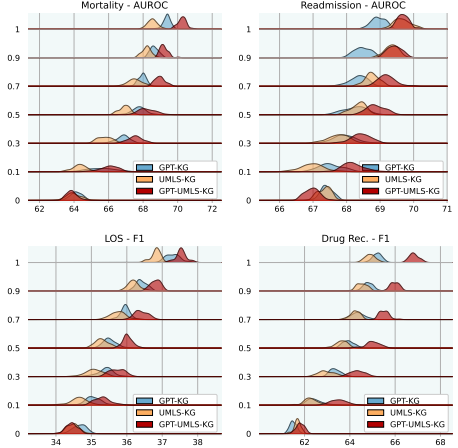
消融实验:BAT 层的不同模块和组件对不同任务的影响
模型的可解释性分析:被正确预测为死亡的患者的相关重要节点
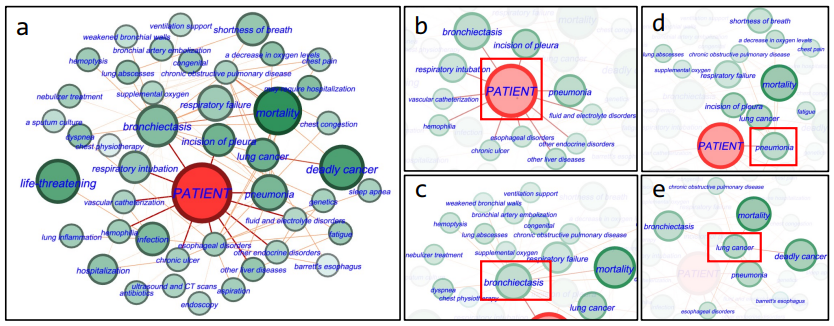
- 图 a 显示了对死亡预测有重要贡献的节点,比如 “deadly cancer”,“life-threatening"等
- 图 b 显示了患者直接相关的实体,如"bronchiectasis”(支气管扩张)和"pneumonia"(肺炎)
- c, d, e 图则展开这些重要节点的相关节点信息
不同患者表示方式的在不同任务上的效果差异:

相关资源
- 论文在线地址
- 开源代码地址
- 第三方笔记参考
- 本地文件地址:Jiang et al_2024_GraphCare.pdf
- 本地Zotero地址:Jiang et al_2024_GraphCare.pdf