中文标题:世界模型
英文标题:World Models
发布平台:NeurIPS
发布日期:2018-03-28
引用量(非实时):1031
DOI:10.5281/ZENODO.1207631
作者:David Ha, Jürgen Schmidhuber
关键字: #世界模型 #MDN-RNN
文章类型:journalArticle
品读时间:2024-02-26 10:38
1 文章萃取
1.1 核心观点
- 本文提出的世界模型能够以无监督的形式快速训练,以学习环境的时间和空间表示;本文特意弱化控制器的拟合能力,以更好地评估世界模型的潜力;通过潜在空间的采样和预测,本文构建了幻想环境(“梦境”)并用于智能体的训练,最终的训练成果在现实环境中也取得了较好的表明;
1.2 综合评价
- 本文证明了智能体在潜空间执行任务(反思/学习)的可行性
- 通过带有温度参数的 MDN,实现了幻觉的采样和不确定性设置
- 本文考虑的方法较为简单,但是一种很有潜力的模型发展方向
1.3 主观评分:⭐⭐⭐⭐⭐
2 精读笔记
2.1 背景知识
心智模型(Jay Wright Forrester,1971):
- “_The image of the world around us, which we carry in our head, is just a model. Nobody in his head imagines all the world, government or country. He has only selected concepts, and relationships between them, and uses those to represent the real system._”
- “我们对周围世界的印象来自我们自己在内心想象中的一个模型。没有人会想象整个世界、政府或国家。他只选择了概念以及它们之间的关系,并用它们来代表真实的世界体系。”
为了处理来自世界的海量信息,人类大脑需要学习这些信息在时间和空间中的抽象表示
人类大脑内部的预测模型:

- 我们在任何特定时刻的感知都受到大脑内部模型对未来的预测的控制(比如错视图片)
- 当我们面临危险时,我们能够本能地根据这种内部模型的预测快速采取行动(条件反射)
- 以"棒球手击球"为例,选手的肌肉根据内部模型的预测,在正确的时间和位置反射性地挥动球棒
- 棒球手可以根据对未来的预测快速采取行动,而无需有意识地推出未来可能的场景来形成计划
前置知识:1_study/DeepLearning/生成式神经网络#变分自编码器 VAE、RNN、1_study/DeepLearning/生成式神经网络#混合密集网络 MDN
2.2 模型细节
循环世界模型(Recurrent World Models)的结构:
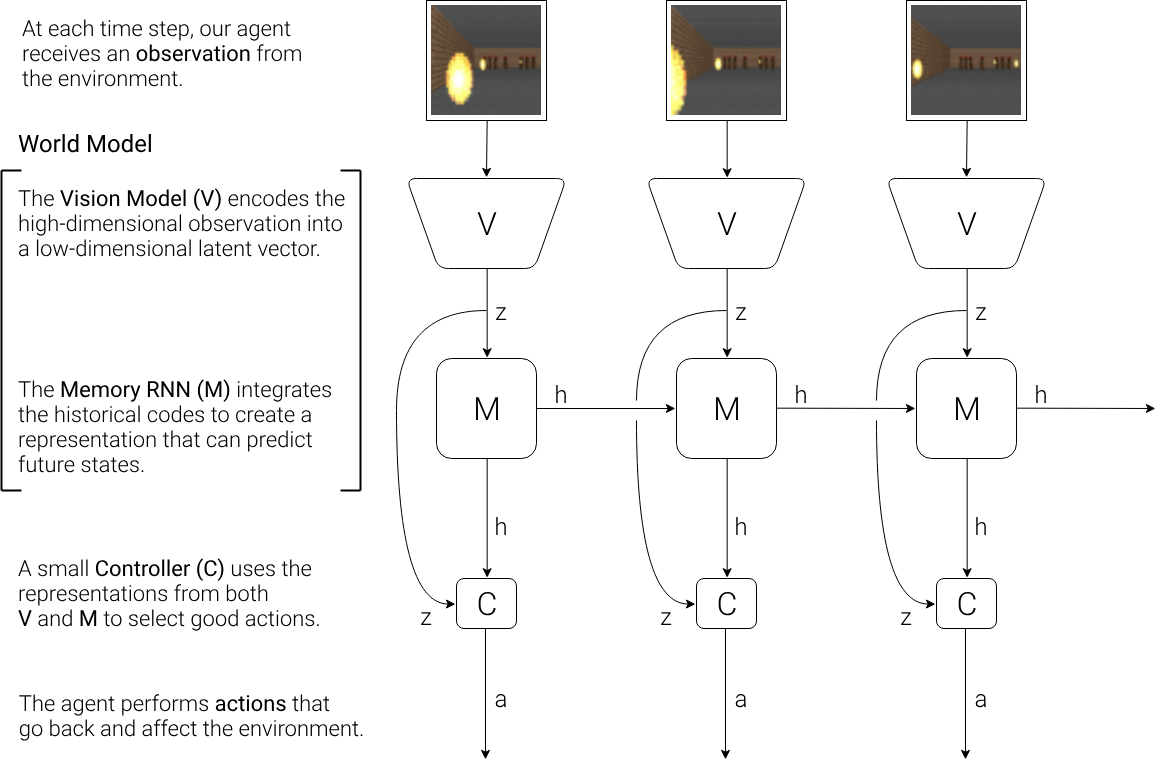
- V 模型使用 VAE (编码器+隐变量+解码器)在每个时间步,将高维的观测信息转化为低维的潜在向量(隐变量 $z$)并传递至 M 模型;VAE 的解码器部分还支持低维信息的还原
- M 模型根据历史信息对未来的编码信息 $z$ 进行预测,由于许多复杂环境本质上是随机的,因此 M 模型会使用 MDN 模型输出预测值的概率分布情况
- 控制器 C 由一个简单的单层线性模型(此处是本文作者故意弱化 C 以验证 V 和 M 的复杂性),其作用是根据 V 模型和 M 模型的确定动作 $a$ 并追求累积奖励最大
细节补充 1:M 模型的结构
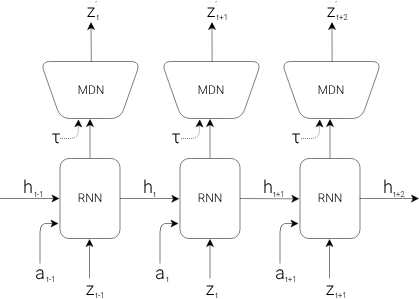
- RNN 输入包括 t 时刻的隐变量 $z_{t}$ 和动作 $a_t$,上一轮的隐藏状态 $h_{t}$
- RNN 通过串联 MDN 网络,直接预测输出未来隐变量 $z_{t+1}$ 的概率分布
- 其中 $\tau$ 是温度参数,用来控制模型输出的不确定性
细节补充 2:模型与环境的交互
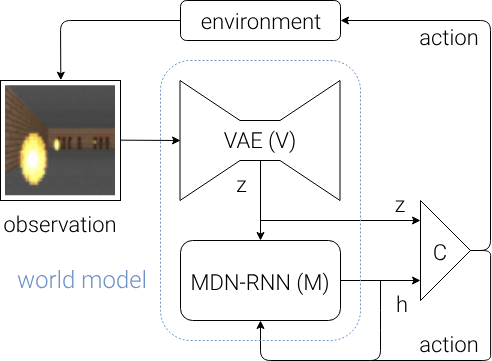
- 总结:原始观察结果经过 V 转化为隐变量 $z$ 并分别作用于 M 和 C;M 基于历史信息和上一轮动作 a 估计未来的隐变量,并将其隐藏状态 h 传递给 C;C 给出下一轮的动作 a 并对环境产生影响
- 通过定义一个行为良好、可微分的损失函数,V 和 M 都比较容易训练;因此本文加大了 V 和 M 模型的参数量,并通过 GPU 对 V 和 M 进行高效训练
- 本文主要使用 OpenAI 的 GYM 包来实现环境的搭建和奖励的计算;控制器 C 的参数训练主要依赖于协方差矩阵适应进化策略算法 (CMA-ES算法,一种用于非凸黑盒问题的进化算法)
2.3 赛车实验
给定随机生成的跑道环境,预测世界模型可以提取有用的空间和时间表示,并输出给一个简单的控制器 C 用于赛车的驾驶,驾驶目的是尽可能避免赛车冲出跑道

赛车实验的动作设计:左转向、右转向、加速/制动
赛车实验步骤:
- 训练数据的搜集:通过 10,000 次随机环境部署创建数据集,构建一个随机行动的智能体多次探索环境;在探索过程中记录不同的随机行动 a 以及对环境的观察结果(包括动作的影响)
- 模型 V 的训练:使用这个数据集来训练 V 来学习观察到的每个帧的潜在空间。给定输入信息,VAE 先将其编码为隐变量 z 再将其解码,VAE 追求输入信息与解码结果之间的差异最小化
- 模型 M 的训练:给定隐变量 z,模型 M 的目的是尽可能准确地预测未来的隐变量分布
- 控制器 C 的训练:基于 CMA-ES 进化算法根据环境反馈的奖励信息进行参数优化
模型 V 和模型 M 只进行输入信息的编码和预测,只有控制器 C 才会访问环境中的奖励信息
三个模型的参数量:V(4,348,547),M(422,368),C(867)
不同模型的最终得分对比:
| Method | Average Score over 100 Random Tracks |
|---|---|
| DQN | 343 ± 18 |
| A3C (continuous) | 591 ± 45 |
| A3C (discrete) | 652 ± 10 |
| ceobillionaire’s algorithm (unpublished) | 838 ± 11 |
| V model only, z input | 632 ± 251 |
| V model only, z input with a hidden layer | 788 ± 141 |
| Full World Model, z and h | 906 ± 21 |
仅考虑模型 V+控制器C:

- 赛车能在够在赛道上行驶,但容易出现摇晃和错过急转弯的情况
- 智能体 100 次随机试验得分是 632 ± 251,和传统 RL 方法性能相似
- 控制器 C 添加隐藏层能略微改善性能,但不足以解决问题:788 ± 141
完整的世界模型(V+M+C):

- 对未来信息的预测能更好地改善智能体的稳定性和拐弯能力
- 模型 M 替代人类内部的预测机制,实现类似赛车手的快速反应
- 模型接收原始像素图像流并学习时空表示,实现 906 ± 21 的最佳得分
模型幻想的可视化:

- 基于 MDN-RNN 的输出采样生成虚假环境,并使用 VAE 的解码器进行渲染
- 将训练好的 C 放回到 M 生成的“梦境”中,可以发现策略 C 依然是部分有效的
在真实环境中学习的策略似乎在“梦境”中发挥了一定作用。这就引出了一个问题:“我们能否训练我们的智能体在自己的幻想中学习,并将该策略转移回实际环境?”
2.4 VizDoom 实验
毁灭战士(VizDoom)
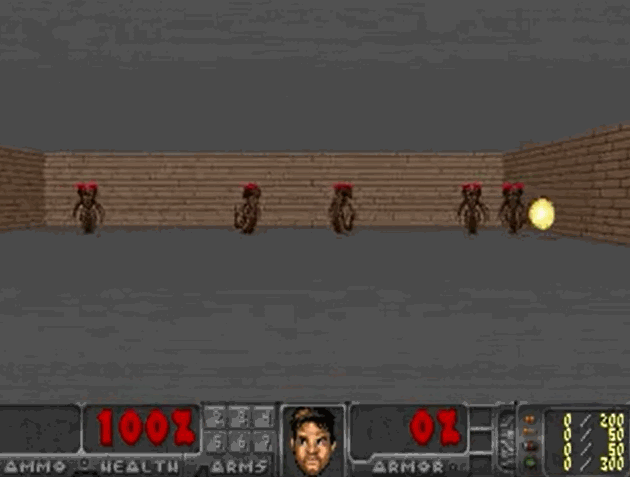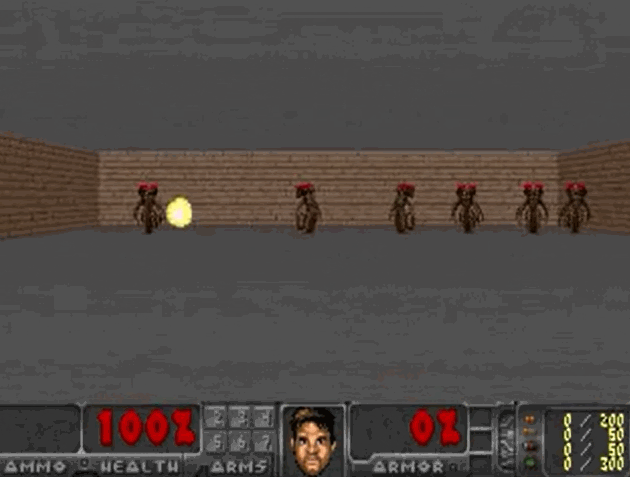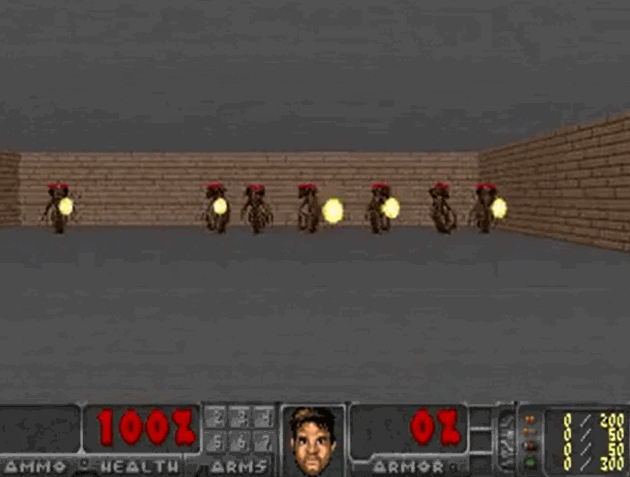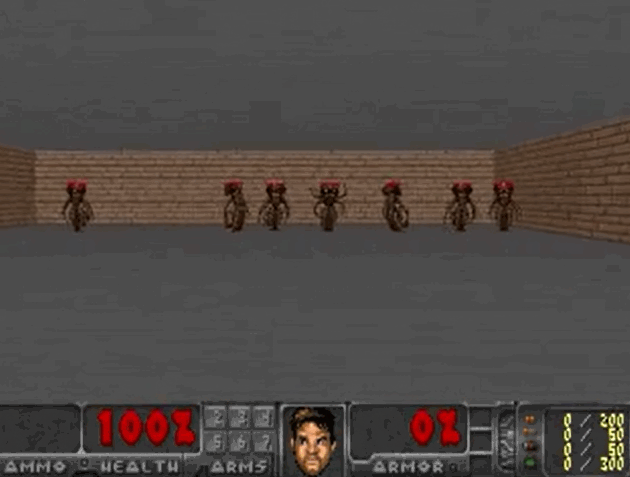
- 一个简单的射击类游戏,是强化学习的一个经典场景
- 怪物会在房间的另一侧发射火球,智能体则需要扮演特工躲避
- 实验目标是 100 次测试的平均存活时间大于 750 个时间帧(~20s)
VizDoom 实验的主要目的:智能体能否在“梦境”中学习,并将策略应用到实际场景中
VizDoom 实验步骤:
- 基础设置和赛车实验基本一致,V 模型的训练也无太大差异
- M 模型除了预测未来的潜变量 z,还需要预测智能体是否在下一帧死亡
- 控制器 C 的目标是最大化智能体在“梦境”中的预期生存时间
实现“梦境”训练的关键点在于,先使用 M 模型预测 $t$ 时刻的潜变量 $z_{t}$,控制器 C 再根据潜变量 $z_{t}$ 信息生成 $t$ 时刻的动作,然后指导 M 模型预测 $t+1$ 时刻的潜变量 $z_{t+1}$
即智能体完全在潜空间中进行训练(V 模型单独训练,并且只参与最初的信息编码)
三个模型的参数量:V(4,446,915),M(1,678,785),C(1,088)
梦中训练成果:
- 控制器学会在“梦境”中导航并逃离 M 模型生成的怪物发射的致命火球
- 调整温度参数可以控制“梦境”的不确定性,也导致“梦境”的学习难度更大
- M 模型学会了特工不同动作对环境的影响,学会了墙面能阻止特工的继续位移,能跟踪并预测怪物发射的火球(对怪物本身容易忽略),还可以检测特工是否已被火球击杀
将“梦境”中训练的智能体,应用到实际环境中:
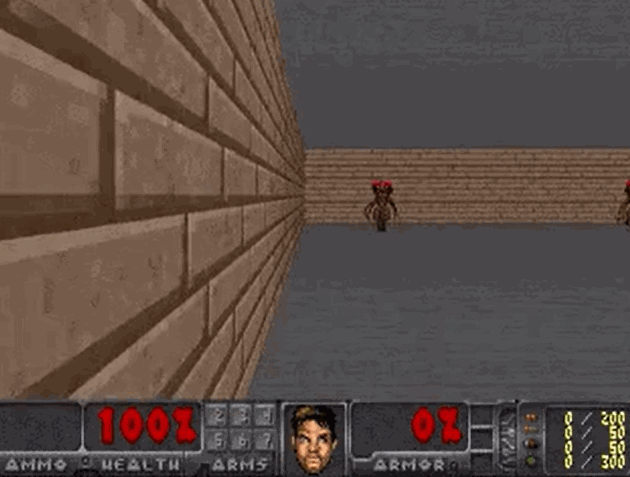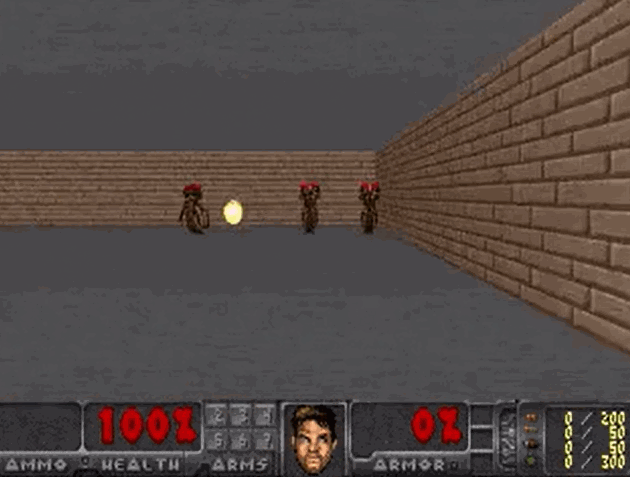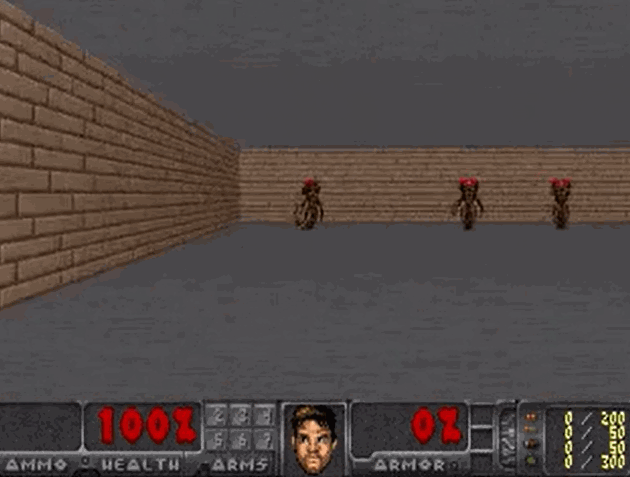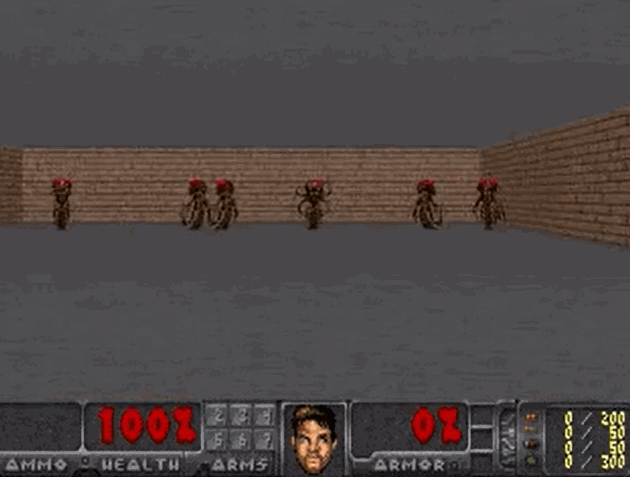
- 智能体在真实环境中的 100 次试验平均存活时间为 1100 步长(远超预期的 750 步长)
- 由于“梦境”的难度更大(噩梦),所以智能体在实际环境中的表现地更加游刃有余
不同温度参数下的得分对比:
| Temperature | Score in Virtual Environment | Score in Actual Environment |
|---|---|---|
| 0.10 | 2086 ± 140 | 193 ± 58 |
| 0.50 | 2060 ± 277 | 196 ± 50 |
| 1.00 | 1145 ± 690 | 868 ± 511 |
| 1.15 | 918 ± 546 | 1092 ± 556 |
| 1.30 | 732 ± 269 | 753 ± 139 |
| Random Policy Baseline | N/A | 210 ± 108 |
| Gym Leaderboard [34] | N/A | 820 ± 58 |
- 调整温度参数 $\tau$ 可以控制 M 模型中的随机性,从而控制真实性和可利用性之间的权衡(当设置较低的温度参数 $\tau=0.1$ 时,“梦境”中的怪物无法发射火球,导致整体训练的异常)
- 增加温度参数会导致控制器 C 更难找到对抗性策略,但也会降低实际环境中的得分波动性
其他实验结果:
- 由于控制器 C 可以直接访问模型 M 的隐藏状态,所以智能体能直接探索操作游戏引擎的隐藏状态(本质上是授权游戏的所有状态和内存权限),从而更有效地实现最大化预期累积奖励
- 由于隐变量的采样,模型 M 偶尔会生成远离分布的隐变量,从而误导控制器 C,产生一些在“梦境”下有效但在真实环境下无效的对抗性策略(比如“梦境”中的火球没那么稳定,所以智能体可以通过快速左右抖动来躲避子弹~)
- 在更复杂中的环境下训练合理的世界模型,需要丰富的观察结果和智能体积极的探索;在世界模型已经吸收并掌握大量基本运动技能后,小模型可以依赖世界模型的基础能力,专注于学习更高级的技能
2.5 讨论与后记
海马体重放:当动物休息或睡眠时大脑重放最近的经历,实现记忆的巩固
“less like dreaming and more like thought”——Foster
在潜空间进行思考与学习的好处:
- 减少应对实际场景海量数据所需要的计算资源
- 利用分布式深度学习框架加速世界模型的模拟
已有框架的局限性:
- VAE 的单独训练可能导致任务无关信息的编码
- 当前世界模型的容量有限,需要更高效的模型架构
世界模型与视频生成的差异(个人总结):
- Sora 类视频生成模型,重视图像质量和细节的捕捉,通过图像的合理性约束和时间层面的连续性约束,间接实现了对世界物理规律的捕捉(由外到内)
- 世界模型则在信息尽量完备的前提下,可以在潜空间下的进行训练与学习(类似自我反思机制),注重世界的规律和未来的演变预测;能实现反事实推理,回答 what if 问题(脑补的重要性);
- LLMs 和 Sora 通过模仿来逐渐理解世界,起点低,但输入的数据丰富且模型的抽象能力强,可以逐渐掌握了偏向本质的高阶特征;传统世界模型以潜空间为切入点,起点高,但学习困难(对信息的完备性要求好,训练难度大,依赖环境和奖励反馈)
- 两种方法是殊途同归的,都在追求一种强 AI 式的涌现(目前来看前者的方法很简单粗暴,但实际效果更好,而后者更接近人类的思维方式,但仍在探索更合理的训练机制)
其他世界模型的相关学习资料:
- LeCun 团队对世界模型的理解:知乎-世界模型,迈向自主机器智能时代
- LeCun 团队提出的世界模型框架 JEPA:A path towards autonomous machine intelligence
- LeCun 团队基于 JEPA 框架提出了面向图像和视频的自监督学习模型:I-JEPA 和 V-JEPA
- 语言模型表征空间和时间这一篇论文,展现了普通 LLMs 模型对时空的表征能力
- Deepmind 的 Genie 模型 依靠游戏视频无监督训练,实现了可交互的基础世界模型