中文标题:语言模型的物理学 1:含深层逻辑的语法树
英文标题:Physics of Language Models: Part 1, Context-Free Grammar
发布平台:无
预印本
发布日期:2023-01-01
引用量(非实时):10
DOI:10.48550/ARXIV.2305.13673
作者:Zeyuan Allen-Zhu, Yuanzhi Li
文章类型:journalArticle
品读时间:2023-12-17 17:03
1 文章萃取
1.1 核心观点
本文通过设计实验来研究 GPT 等生成语言模型如何学习上下文无关语法(CFGs,context-free grammars)——含深层逻辑的语法树,捕获自然语言、程序和人类逻辑的许多方面。为此,本文构建了合成数据,并证明即使对于非常复杂的 CFG,预训练的 Transformer 也可以学习并生成极高准确性和显著多样性的句子
本文深入研究了 Transformer 如何学习 CFG 背后的物理规律,发现 Transformer 中的隐藏状态隐式且精确地编码 CFG 结构(例如将树节点信息精确地放在子树边界上),并学习形成类似于动态规划的“边到边”注意力。总的来说,本文的研究对 Transformer 如何学习 CFG 提供了全面和实证的理解,并揭示了 Transformer 用于捕获语言结构和规则的物理机制
1.2 综合评价
- 本文从 CFG 作为切入口,对生成式 Transformer 模型进行深入剖析
- 本文实验能很好地帮助理解生成式模型的逻辑抽取和信息存储能力
- 本文实验较多,受限于篇幅本笔记只记录了几个较为关键的结论
1.3 主观评分:⭐⭐⭐⭐
2 精读笔记
背景知识:上下文无关语法 CFG
实验说明:
- 12 层 12 头 768 维 GPT-2 网络,使用标准自回归任务对模型进行预训练
- 4个 GPT 网络变体,原始
GPT为绝对位置编码,GPT_rel为相对位置编码;GPT_rot为旋转位置编码;GPT_pos将注意力矩阵替换为仅标记相对位置的矩阵;GPT_uni根据不同时间窗口的历史矩阵作为注意力矩阵 - 构建了 7 个不同难度/深度的 CFG (𝖼𝖿𝗀𝟥𝖾𝟣, 𝖼𝖿𝗀𝟥𝖾𝟤, 𝖼𝖿𝗀𝟥𝖻, 𝖼𝖿𝗀𝟥𝗂, 𝖼𝖿𝗀𝟥𝗁, 𝖼𝖿𝗀𝟥𝗀, 𝖼𝖿𝗀𝟥𝖿 难度依次上升),并通过采样生成大型语料
一个 cfg3f 的实例:

- 其中带颜色加粗的数字表示 NT 边界,其属于每层子树的边界
不同模型在不同 CFG 难度数据中的生成精度表现:
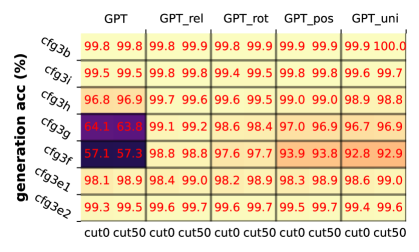
- 歧义性较小的 CFG( 𝖼𝖿𝗀𝟥𝖾𝟣 、 𝖼𝖿𝗀𝟥𝖾𝟤 )很容易学习
- 现代变压器变体(
𝙶𝙿𝚃_𝗋𝖾𝗅或𝙶𝙿𝚃_𝗉𝗈𝗌)能更好地学习困难 CFG - 注意力矩阵弱化模型(
GPT_pos,GPT_uni)在困难任务中的精度明显下降
cut0 表示从头开始生成, cut50 表示从第 50 个字符开始生成
生成字符串的多样性评估(多样性高表明模型对语法规则有更好的理解)
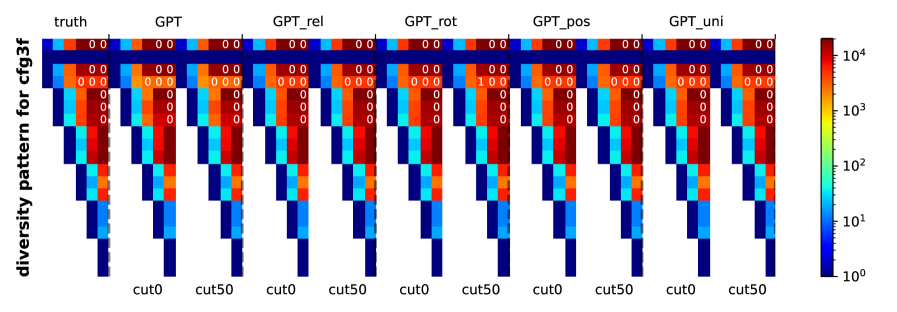
- 行对应不同的 NT (非终结)符号,列对应不同的 CFG 深度
- 颜色越深表示生成结果的多样性越高,白色数字表示碰撞次数
- 不同模型的生成结果均具有较高的多样性,对语法规则有较好的理解
模型的隐藏状态几乎完美地对隐藏的 NT 信息进行线性编码:
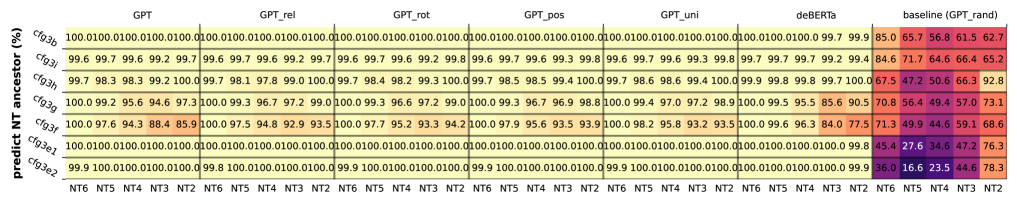
- 直接针对最后一层的隐藏状态添加线性函数,并进行 NT 祖先和 NT 边界的预测
- 线性探测结果显示,模型的隐藏状态包含相关的 NT 祖先和 NT 边界信息,并且这类信息只需要一个简单的线性变换就能提取出来
- 类 BERT 模型(deBerta)在接近 CFG 根时(NT 2/NT 3)学习 NT 信息的效果较差
直接使用 NT 边界处的隐藏状态预测 NT 祖先
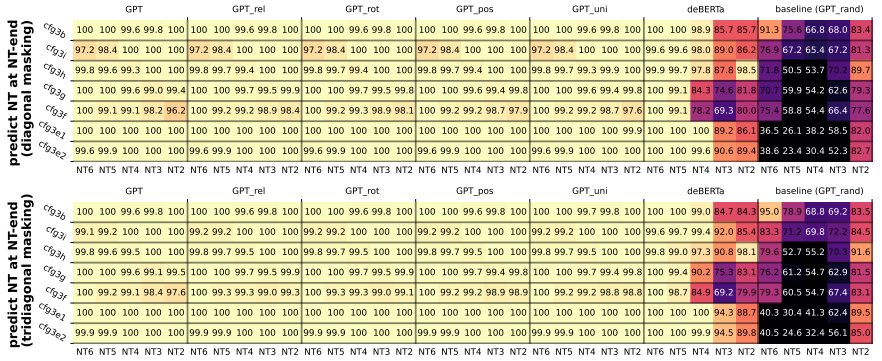
- 生成式预训练 Transformer 在 NT 边界处对 NT 祖先进行完整编码
- 类 BERT 模型(deBerta)NT 边界处没有对 NT 祖先进行完整编码
鲁棒性评估

NT-level扰动表示对非终结符号进行扰动;T-level扰动表示对终结符号进行扰动;NT-level deterministic表示扰动具备一定规律- 纵轴中 $\tau$ 表示数据的生成温度,
corrupted表示对生成前的输入文本也进行扰动 - 横轴表示数据的破坏比例;随着破坏比例的增加,模型表现下降明显
- 对于
corrupted数据,一定程度的数据破坏反而有助于改善模型的泛化能力
仅使用语法正确的数据预训练的 GPT 模型只能达到中等的鲁棒精度。添加少至 10% 的数据扰动,甚至允许所有训练样本都存在语法错误,鲁棒精度就会显着提高。这一发现表明,在预训练期间包含低质量数据可能是有益的
其他结论:
- 基于位置的注意力使模型能够学习 CFG 的规律性和周期性,并根据其位置生成令牌。基于边界的注意力使模型能够学习 CFG 的分层和递归结构,并根据 NT 符号和规则生成标记
其他系列文章:
语言模型的物理学 3.1:知识存储和提取
语言模型的物理学 3.2:知识操控
相关资源
- 论文在线地址
- 本地文件地址:
- 本地Zotero地址: