中文标题:语言模型的物理学 3.1:知识存储和提取
英文标题:Physics of Language Models: Part 3.1, Knowledge Storage and Extraction
发布平台:无
预印本
发布日期:2023-01-01
引用量(非实时):3
DOI:10.48550/ARXIV.2309.14316
作者:Zeyuan Allen Zhu, Yuanzhi Li
文章类型:journalArticle
品读时间:2023-12-14 22:22
1 文章萃取
1.1 核心观点
本文主要围绕以下核心问题进行探索和验证:语言模型如何在训练时记忆知识,并在以后提取知识来回答问题或在推理时进行逻辑推理?
本文使用一组可控的半合成人物传记数据,对模型是否实现了知识的存储这一问题进行了深入研究。本文通过实验揭示了模型的知识提取能力与训练数据的多样性之间存在强相关性,并通过线性探测确认了预训练语言模型会直接将知识存储在相关知识实体中
1.2 综合评价
- 很有意思的行文方式,带着问题探索答案;能感知到作者的思索过程
- 本笔记在原始论文结构进行略微调整,以更好地提炼内容/精简文本
- 很多人都在盲目追求大模型或Transformer的修改,我们需要更多的人去主动理解模型,触摸模型的底层逻辑,理解模型才是改进模型的最好开始
1.3 主观评分:⭐⭐⭐⭐⭐
2 精读笔记
2.1 半合成可控数据
当前的大语言模型都是使用互联网文本进行的训练,因此针对“亚伯拉罕·林肯出生在哪个城市?”之类的问题,我们无法判断模型是基于内部知识和逻辑推理得到的答案,还是单纯因为该问题在训练集中出现过而直接输出答案
为此,本文通过半合成的方式构建了可控的人物传记数据
数据集1:BIO dataset(简称 bioS)
- 基于 50 个固定模板随机生成 100000 人的档案/传记,文本中包含 6 个基本属性(姓名,出生城市,出生日期,所学专业,就职公司,公司城市)
- 示例:“Anya Briar Forger 出生于 1996 年 10 月 2 日。她在新泽西州普林斯顿度过了早年。她得到了麻省理工学院教师的指导和指导。她完成了学业,主修传播学。她受雇于Meta Platforms,并在 加利福尼亚州门洛帕克 担任专业职务。”
数据集2:BIO dataset(简称 bioQ)
- 基于 LLaMa-30B 模型随机生成 100000 人的档案/传记,文本中包含 6 个基本属性(姓名,出生城市,出生日期,所学专业,就职公司,公司城市)
- 示例:”Anya Briar Forger 是一位著名的社交媒体策略师和社区经理。她目前在 Meta Platforms 担任营销经理。她从麻省理工学院毕业,获得了传播学学位。她于1996年10月2日出生于新泽西州普林斯顿,并在同一座城市长大。后来她搬到加利福尼亚州门洛帕克,成为 Facebook 团队的一员。她是一位狂热的读者,热爱旅行。“
数据集3:QA dataset(问答数据集)
- 问答数据集很适合用于大模型知识抽取能力的评估;该数据集主要包含针对 bioS 数据集中每个人合成档案的随机某个特定属性的提问
- 示例:”Anya Briar Forger 的出生日期是哪一天?答案:1996 年 10 月 2 日“
2.2 模型训练
模型基本架构:GPT2-small(12 层、12 个头和 768 个维度)
原始 GPT2 中使用的绝对位置编码,考虑到其局限性本文改成了相对位置编码
本文主要采用混合训练方式,并使用传统的预训练方式对比:
- 混合训练(BIO 数据集 + 50% QA数据集),测试集(50% QA数据集)
- 传统的预训练(BIO 数据集) + 微调(50% QA数据集),测试集(50% QA数据集)
微调方法:针对下游任务使用 LoRA 微调——即冻结所有预训练的模型参数并向权重矩阵的子集添加低秩更新以进行微调,这样可以不干扰预训练模型本身的参数
混合训练的初步结果如下:
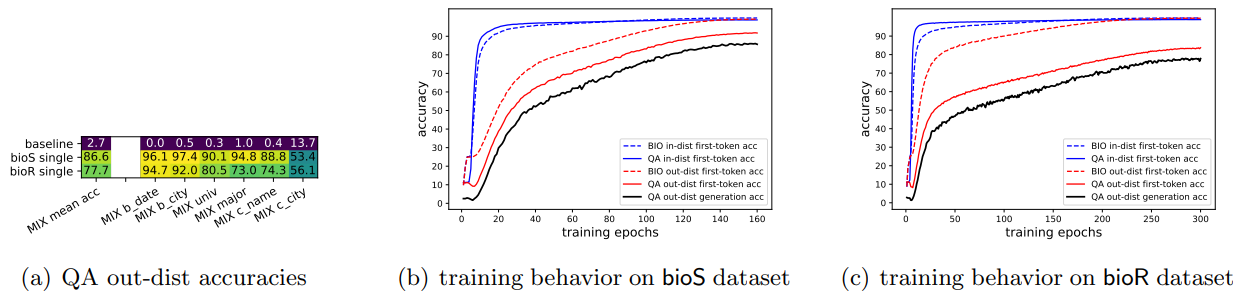
- 图(a)中,
b_date,b_city,c_name,c_city分别代表出生日期、出生城市、公司名称、公司城市;mean_acc代表六个属性的平均准确度;baseline是使用属性的众数作为预测值 - 图(a)显示,混合训练的模型表现出很强的分布外泛化能力(准确率在 77.7%~86.6%),表明该模型可以从 BIO 数据中提取和利用知识,并用于额外的测试集
- 图(b)和图(c)展示了模型训练过程中在训练集和测试集上的精度变动;可以发现模型的学习顺序:模型先使用训练集 QA 进行编码 -> 然后模型开始关注训练集 BIO,实现两种训练数据的知识对齐 -> 最终模型在测试集上性能表现实现稳步提升
作为对比,传统的预训练 + 微调结果如下:
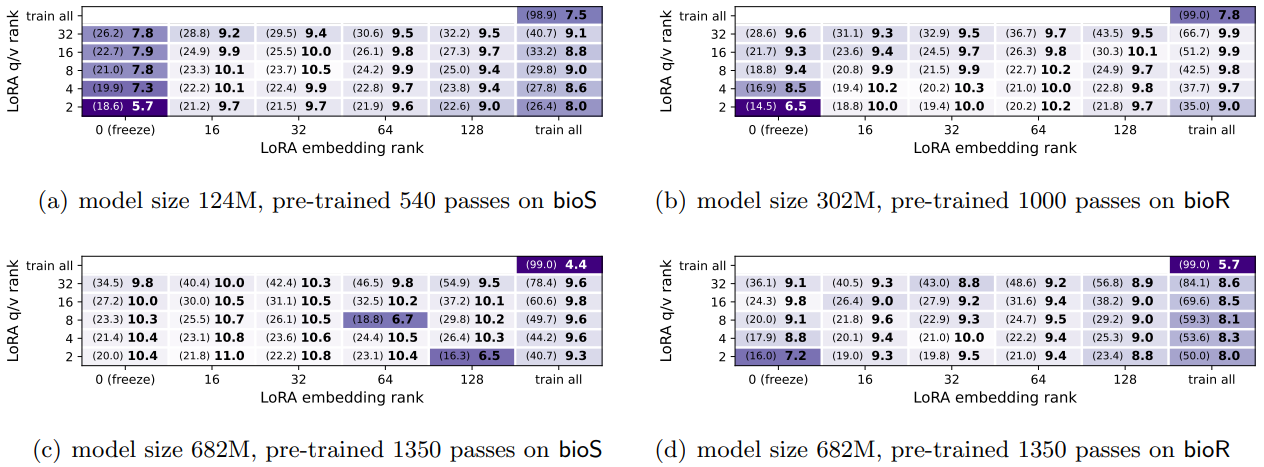
- 上图中,粗体数值为测试集准确率,括号内为训练集准确率
- 不同的模型参数量或 LoRA 超参数,该方式训练的模型泛化能力都比较差
- 该训练方式中,QA 训练集未参与预训练过程,LoRA 微调也未出现性能显著提升
- 这说明仅使用 BIO 数据预训练的模型,其内部没有存储知识/训练过程未提取知识
注意此时的结果与现实中 GPT3.5 的结果是相悖的,本文推测其中的分歧主要是由于互联网数据的多样性,因此下一小节将针对已有的半合成数据进行知识增强
2.3 知识增强
本次实验使用三种方式进行知识/数据增强
multiM:使用不同的模板为个人生成 M 条档案/传记fullname:将传记中的他/她/他们替换为该人的全名permuteN:对N个句子进行随机排列、打乱(仅限 bioS 数据集)
废话不多说,直接看不同知识增强的效果:

- 左半部分为预训练 + 微调的训练结果;右半部分为混合训练的训练结果
- 本图展示的是基于 bioS 数据集训练的结果;模型泛化能力得到明显改善

- 本图展示的是基于 bioR 数据集训练的结果;模型泛化能力也得到明显改善
初步结论:
- 三种知识增强方法都可以显著提高模型在预训练期间抽取/存储知识的能力
- 随着数据多重性或随机重排次数的增加,模型的准确性也会持续增加
- 将模型暴露于相同知识的不同表达方式会鼓励它关注信息的底层逻辑结构
为了更深入的理解知识增强的作用;考虑仅针对少部分人群进行知识增强:
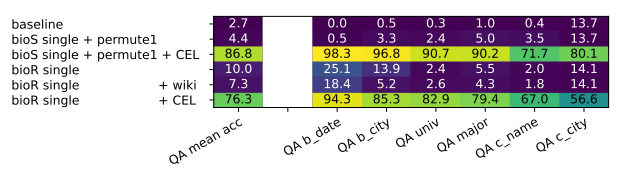
- 其中
CEL表示仅针对少部分人进行知识增强(mutil5 + permute) - 引入部分人群的知识增强,可以将测试集的 QA 准确率从 4.4% 提高到 86.8%
- 此类情况在基于 bioR 数据训练的模型中也存在,准确率从 10.0% 提高到 76.3%
- 其中额外使用
wiki进行知识增强并不会改善测试集准确率(说明只有类似形式的人群文本数据才能真正有助于模型对相关实体知识的提取)
需要注意的是,相比于其他预测任务,工作城市的预测精度会显著偏低;这是由于数据的合成规则导致的——即工作城市仅和工作公司有关,因此人物与工作城市之间只有一个间接关系(多一层逻辑)
2.4 知识探索
本小节使用线性探针进行模型内部知识的探索
本小节提出了两种探索方式:
- 基于位置的探测(P-probing),在模型的最终隐藏层上训练一个额外的线性分类器来预测目标的六个属性(例如大学、专业等)
- 基于查询的探测(Q-probing),仅使用包含人名的句子作为输入项(而不再是完整的传记),然后也在最终隐藏层上训练一个额外的线性分类器来预测目标的六个属性
2.4.1 基于位置的探测
P-探测示意图:

- 根据预测目标,选择最多6个特殊位置进行截断,截断之前的文本作为输入项
- 给定属性排序,所有数据中最多可以有 6×6=36个任务
P-探测的最终精度:
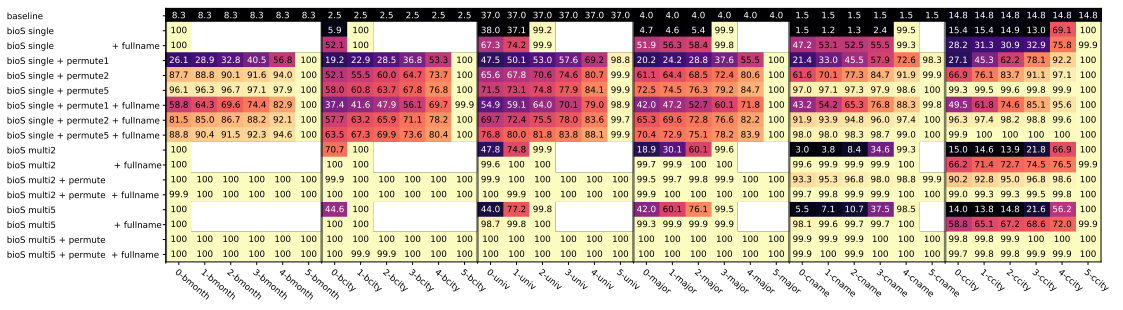
- 横轴为不同的预测任务(
3-bmonth表示在第$3$处截断开始的预测出生月份),纵轴为不同数据训练的模型 - 在
bioS + single模式下训练的模型,会随着截断的延后而逐渐增大精度(2%~99%),说明当最后一个截断前的文本输入后,模型能记住(编码到) BIO 数据,但模型不能实现存储知识的抽取和有效利用 - 在
bioS multi5+permute模式下训练的模型表现最好(一直100%),说明此时的模型不仅可以记住 BIO 数据,而且只需看到人名(第$0$处截断点之前的文本作为输入)即可知道人物的完整属性,编码的知识容易抽取并有效利用,也有助于 QA 微调过程中的知识提取 - 比较
single和multi5,可以发现添加数据的多重性(不进行排列)可以促进属性的存储/编码,这使得 QA 微调精度从 9.7% 增加到 41%;同样,比较single+ permute1与single+permute5,可以观察到将句子的重排(未增加句子的多样化)也会导致更早的知识存储,QA 微调准确率从 4.4% 上升到 70%
P-探测的深入分析(不同预测任务的对比):
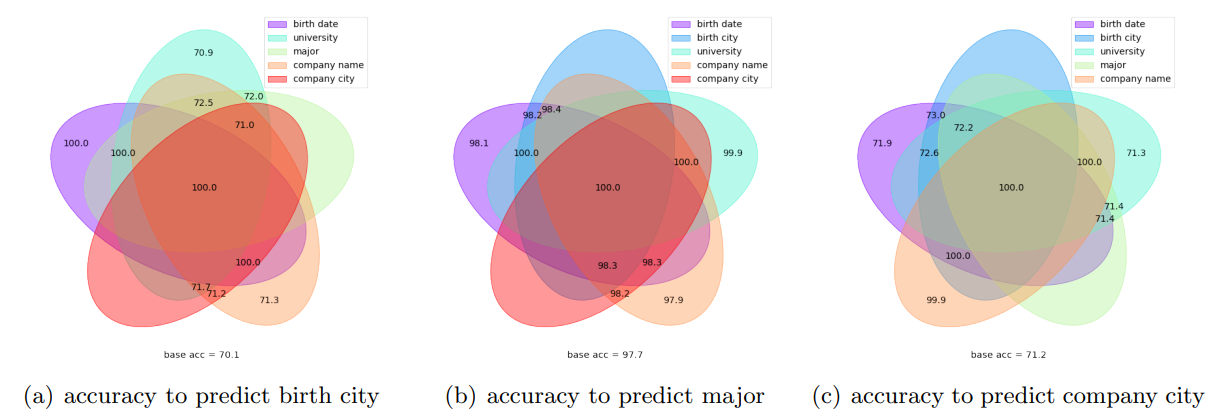
- 维恩图根据剩余五个属性中的每一个是否已被看到,显示了特定属性的预测准确性
- 图(a)显示,“出生城市”的预测精度随着“出生日期”的预测精度提高而提高
- 图(b)显示,“出生城市”的预测精度随着“出生日期”的预测精度提高而提高
- 图(c)显示,“出生城市”的预测精度随着“出生日期”的预测精度提高而提高
2.4.2 基于查询的探测
Q-探测的最终精度:
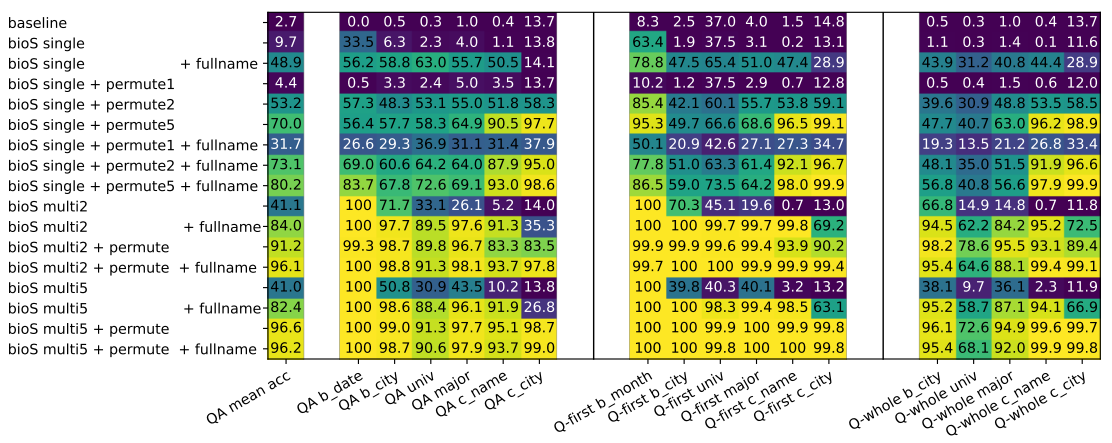
- 上图中
Q-first表示对第一个出现的属性进行预测;Q-whole表示对全部属性进行预测 - 由于Q-探测仅输入包含人名的句子,因此整体测试精度均有所下降;但知识增强版模型仍表现优秀
- 之前 QA 微调精度与目前 Q 探测精度密切相关,表明属性与人名的直接关联程度是有效知识提取的关键因素。如果模型在预训练期间未能正确存储知识,QA 微调可能无法纠正此问题
- 将知识增强应用于预训练数据后,Q 探测精度显着提高。这表明该模型在与人名直接相邻的隐藏状态中几乎线性地编码知识。因此,线性探针可以有效地从这些隐藏状态中提取人的属性,而模型也可以通过 QA 微调来回答与这些属性相关的问题
重要结论:语言模型确实在人名编码过程中构造了从人名到属性的直接映射
2.5 其他实验和补充
本文最后又使用了 BERT 架构的模型进行了类似的实验:
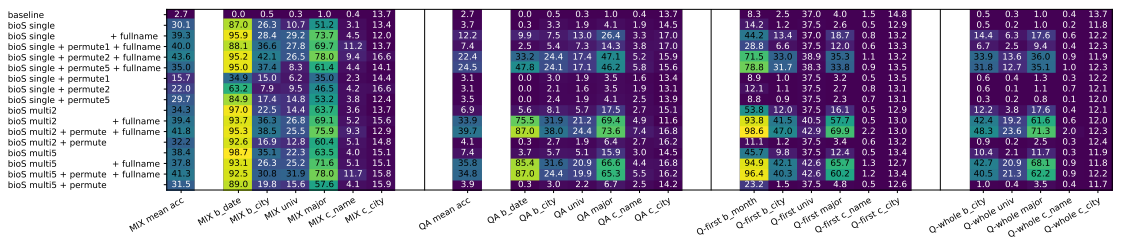
- 结果无论是混合训练(左),预训练+微调(中左)还是Q-探测(中右,右),结果都不太行
- QA 微调和Q 探测精度显示出很强的相关性。这表明 BERT 类模型提取知识的能力也取决于这些信息是否几乎线性地存储在与人名直接相邻文本对应的最终隐藏状态中
- 与BIO 预训练+ QA 微调相比,混合训练产生的测试集 QA 精度稍微高一些
- BERT 类模型在预测出生日期方面效果更好,这可能与其训练时的自掩码过程有关
- 除非知识是相对独立的(如年/月/日),否则 BERT 类模型在预训练后很难提取知识
在预训练期间重写必要但不经常出现的数据很重要,要确保其有效存储用于后续任务
如果预训练数据没有及时进行知识增强,则微调阶段的模型纠正可能为时已晚了
其他系列文章: 语言模型的物理学 1:含深层逻辑的语法树 语言模型的物理学 3.2:知识操控