中文标题:语言模型的物理学 3.2:知识操控
英文标题:Physics of Language Models: Part 3.2, Knowledge Manipulation
发布平台:预印本
发布日期:2023-09-25
引用量(非实时):3
DOI:10.48550/arXiv. 2309.14402
作者:Zeyuan Allen-Zhu, Yuanzhi Li
文章类型:preprint
品读时间:2024-01-06 18:33
1 文章萃取
1.1 核心观点
本文探讨了语言模型在推理过程中操纵其存储知识的能力,并主要关注以下四种操作类型:检索(“人 A 的属性 X 是什么”)、分类(“A 的属性 X 是偶数还是奇数?”)、比较(“属性 X 中 A 是否大于 B”) ?”)和逆向搜索(“哪个人的属性 X 等于 T?”)
主要发现:大语言模型在知识检索方面表现出色,但在处理简单的分类或比较任务时却遇到困难,除非在训练和推理过程中都使用思想链 (CoT)。无论提示如何,它们在逆向知识搜索中也表现不佳
1.2 综合评价
- 本文通过控制合成数据分析 LLMs 在不同任务下的表现,有助于对 LLMs 的理解
- 本文验证了思想链 (CoT)的有效性,同时确定 LLM 在逆向知识搜索方面的局限性
- 本文给出的主要观点缺乏新颖性,内容相对单薄,可作为对之前系列内容的补充
1.3 主观评分:⭐⭐⭐⭐
2 精读笔记
知识操纵是逻辑推理的一种形式。为了回答诸如“A 的属性 X 好吗?”之类的问题,之前未接触过此问题的语言模型可能会从其他训练数据中提取数据,例如“A 的属性 X 等于 T”和“T 是好”
为了规避互联网数据的不可预测性,本文沿用 语言模型的物理学 3.1:知识存储和提取中合成的人物传记类数据,探究预训练模型是否可以在指令微调后实现知识操纵。
- 普通知识检索任务示例:
Anya Briar Forger 的出生年份是哪一年? 1996年 - 双重知识检索任务示例:`Anya Briar Forger 就读哪所大学的什么专业?通讯;MIT
知识检索任务: ![[5_paper/自然语言处理/附件/Pasted image 20240117135440.png]]
- 上图中,横轴代表不同数据增强效果后的模型;纵轴则分为三类任务,第一列为普通知识检索任务,第二列为双重知识检索任务,第三列为普通问答任务`
- 双重知识检索任务的微调精度取决于模型在两个单独任务的问答能力(最后两个模型在普通问答任务中均表现出色,在双重知识检索任务表现也普遍较好)
- 当两个知识片段之间表现出空间依赖性,则它们的检索顺序可能会影响准确性(
bioS multi5+fullnam模型未进行句子顺序的打乱,因此在QA ccity+cname任务中的表现明显低于该模型在QA cname+ccity任务中的表现) - 即使模型近乎完美地提取属性(例如出生日期),但在部分检索(例如出生年份)可能仍然很差。即,模型可以正确回答了“Anya 人的出生日期是多少”,但该模型可能无法回答“Anya 人的出生年份是多少”之类的问题
- 知识分类任务举例:1)Anya Briar Forger 出生在偶数月份吗?答案:是的 2)Anya Briar Forger 的出生月份 mod 6 是多少?答案:4
- 知识比较任务举例:1)Anya Briar Forger 比 Sabrina 晚一年出生一个月吗? 是/否 2)Anya Briar Forger 的出生月份减去 Sabrina 的出生月份是多少?
知识分类和比较任务:
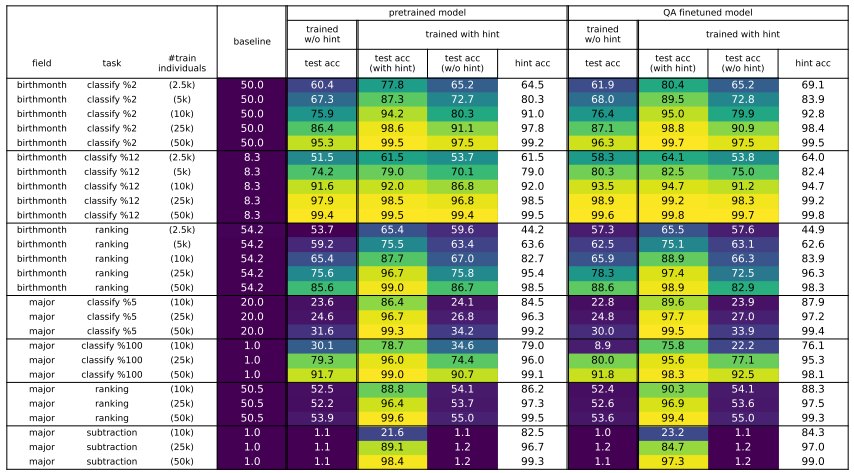
- 上图中,横轴代表不同类型的知识分类/比较任务(主要围绕出生月份 birthmonth 和专业得分 major 展开);纵轴则分为三类模型,除了 baseline 还会包括预训练模型和 QA 微调模型,每类模型还会根据是否进行思想链(CoT)提示微调进行细分
- Test acc(with hint)和 test acc(w/o hint)表示模型在有或没有提示的情况下的准确性,而 hint acc 则对应模型的提示生成准确性(提示生成由 LoRA 微调后的模型生成,每个测试样本有 50%的概率添加提示)
- 对于下游知识操作任务,BIO 预训练模型和 QA 微调模型之间的差异很小
- 测试时添加思想链(CoT)提示,对模型表现有较大的改善作用(没有提示的情况下,模型在处理简单任务时也表现较差);训练时添加提示并不会显著改善模型
- 知识逆检索任务举例:请告诉我 1996 年 10 月 2 日出生的人的名字?请告诉我在麻省理工学院学习通信并在 Meta Platforms 工作的人员的名字?
知识逆检索任务:
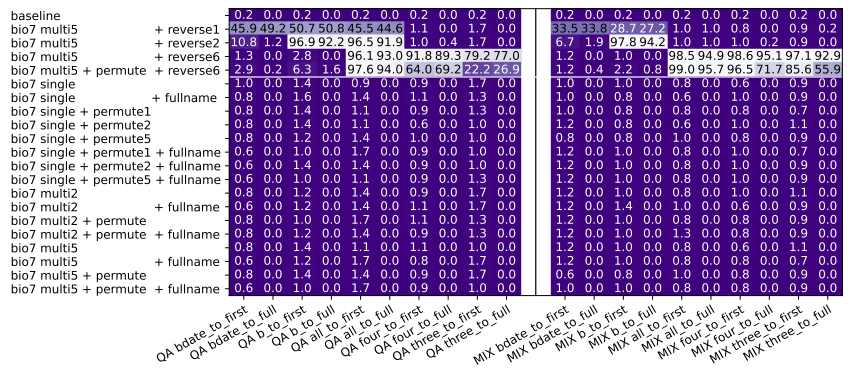
reverse2表示将带人名的句子移至第三句;reverse6表示将带人名的句子移至末尾- 在使用 BIO+QA 混合训练的情况下,模型的知识逆检索精度依然接近于 0,即使是简单的知识逆检索任务(
all_to_first) - 在打乱知识顺序后发现,当属性出现在人名之前时,QA 测试的准确率会提高(具体可参见
reverse5或reverse6对应模型的部分表现)
生成模型的一个基本局限性:除非知识以相反的顺序进行预训练,否则它无法执行逆向知识搜索;不过像 BERT 这样的双向模型可以在一定程度上缓解这一限制
其他结论:
- GPT3.5/GPT-4 等大规模语言模型在逆向知识搜索方面也表现出糟糕的性能(GPT4 能够以 65.9% 的准确率预测简·奥斯汀的《傲慢与偏见》中的下一个句子,但在预测前一个句子时,它的准确率仅为 0.8%)
其他系列文章: 语言模型的物理学 1:含深层逻辑的语法树 语言模型的物理学 3.1:知识存储和提取