1 NER初探
1.1 NER理解
Named Entity Recognition,即命名实体识别
NER常见实体:
- 人名、地名、组织名、各个垂直领域专有名词(特殊的词)
- 日期、数学符号等(正则匹配基本能hold住)
广义的来说,中文分词、词性、词素、语法结构也属于实体,所以NER相关的算法在这几个方面具备一些通用性
1.2 NER标注
标注的目的是对不同情况下的字词做到合理的区分
常见标注方法:
- BIO标注模式: (B-begin,I-inside,O-outside)
- BIOES标注模式: (B-begin,I-inside,O-outside,E-end,S-single)
1.3 NER评估
常见的评估方法:FP、FN、TP、Precision、Recall、F-score
判断正确的两种方式
- Exact-Match:实体的边界和类型都被正确识别
- Relaxed-Match:实体类型正确识别,实体范围与正确的范围有重合
1.4 NER应用
增强文本的信息:优化下游任务,比如信息抽取、问答、翻译;
自动建立标签体系:优化搜索引擎算法、推荐系统算法;
快捷抽取关键信息:简历、客户投诉和用户反馈的自动汇总、快速评估;
2 NER方法
2.1 基于规则的方法
- 通过整理词典、编写语法规则(正则)等方式直接匹配实体
- 常用匹配包括:正向最大匹配、逆向最大匹配、双向匹配
特点:前置工作繁琐、运行速度快、准确度低、拓展性强
具体示例可参考论文结合字典对电子病历进行NER
2.2 基于无监督的方法
聚类算法也可以用于 NER:通过上下文的相似度抽取 简单示例:有请马化腾 发表演讲 vs 有请马云 发表演讲
基于信息熵、互信息(相关概念可参考信息论基础)的实体发现 简单示例:苹果|手机vs苹果|牙刷,前者的互信息远高于后者,前者是一个实体
特点:具备发现未收录词的能力,可能有外部知识库的依赖,效果一般
2.3 基于简单机器学习的方法
常用有监督算法: 隐马尔可夫模型 HMM,树算法族,最大熵模型,1_study/algorithm/分类回归算法/支持向量机 SVM,条件随机场 CRF
HMM算法实践可参考基于角色标注的中国人名自动识别研究
决策树原理可参考树算法族
CRF原理可参考条件随机场 CRF
特点:模型效果高度依赖于特征工程,便捷有效,适合追求高性能的场景
2.4 基于深度学习的方法
基于词嵌入(Embedding)技术得到的词向量,具备了简单语义理解的能力,常见的基础词嵌入包括:谷歌的word2vec,斯坦福的Glove,Facebook的fastText。根据具体的场景也可以是字向量、句向量、文章向量。
基于RNN的两个变种,LSTM以及GRU通过记忆机制和遗忘机制,非常贴近人类阅读的过程,与CRF模型的结合,使得Bi-LSTM这类模型一度成为NER领域的最佳方案。
CNN模型也是一个不错的尝试方向,卷积层和池化层能在更全面的角度把握特征,感受野的局限性也可以通过膨胀卷积得到更好的解决,不过最终效果一般赶不上RNN系列,但是性能上的优势是RNN系列所不能及的(RNN类算法不能并行计算,CNN类模型在保持相同的准确度下,能实现14~20倍的加速)
Transformer机制进一步发挥出了神经网络的内在潜能,由此所得的词向量,具备了更高的语义理解能力,相关的衍生算法也牵动起整个NLP领域的SOTA进步,当然一般还是个位数的改进,并且随之付出是更大的训练成本
特点:自动挖掘深层次特征,拟合能力强大,运算成本高
深度学习NER的三步走:
- 特征表示,处理,转换(针对输入字符进行Embeding或加入其他传统特征)
- 特征变换、编码(通过RNN类层或Transformer层等结构自动抽取高阶特征)
- 标签解码(将最终的编码序列解码为标签序列,完成序列标注)
标签解码(Tag decode)补充说明:
- 一般来说,模型的最终的结果会是实体相关的标注(比如BIO)
- 得到这种标注最简单的方式是看作多分类问题,直接通过Sofamax得到,但这种做法容易忽略掉标签之间的关联关系和序列信息,实际情况中表现也较差。
- 最常见的方式是在最后加一层CRF,这样能考虑标注序列的依存关系
- 还可以用类RNN层作为最终的解码器,这种方式输出的标注,也会额外考虑到上一时刻的输出标注以及隐藏层/记忆门的信息
2.5 NER方法对比
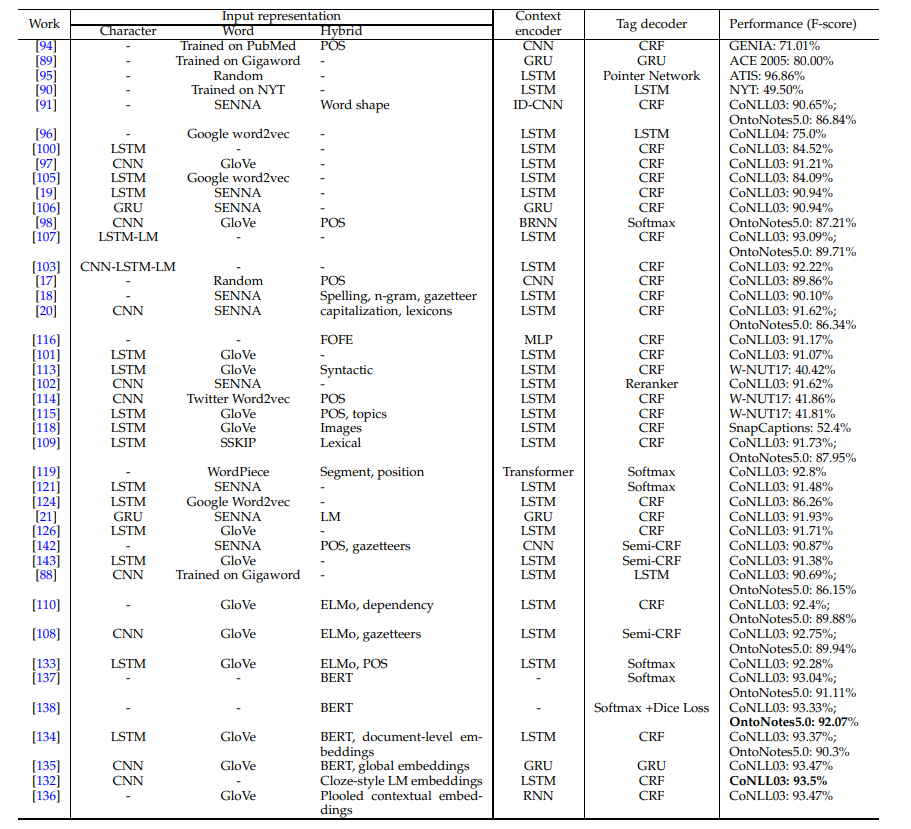
补充:Semi-CRF是应用于段级别的CRF,因为基于词的CRF过于注重词之间的依存关系,而容易忽略段之间的依存关系。
3 NER进阶
3.1 特征工程汇总
- 词级别特征:格(case)、词法(morphology)、词性、大小写
- 类别型特征:所属类目、近似词组、拼写特征
- 文章级特征:章节级别、局部语法、上下文
3.2 NER的改进方向
- 顽固痛点的解决:新实体、实体嵌套、实体歧义
- 深度学习的落地:迁移学习;模型压缩、剪枝
- 深度学习的改进:多模态、跨领域;结合知识
- 其他:数据评估的完善
词汇增强方法可参考:词汇增强方法总结:从Lattice LSTM到FLAT
嵌套实体问题可参考:浅谈嵌套命名实体识别(Nested NER)、GlobalPointer:用统一的方式处理嵌套和非嵌套NER 、
3.3 NER的论文精读
4 NER资源
4.1 相关优质论文(都没看过)
Bidirectional LSTM-CRF Models for Sequence Tagging
Neural Architectures for Named Entity Recognition
End-to-end Sequence Labeling via Bi-directional LSTM- CNNs-CRF
2017Fast and Accurate Entity Recognition with Iterated Dilated Convolutions
Joint Slot Filling and Intent Detection via Capsule Neural Networks
Character-Based LSTM-CRF with Radical-LevelFeatures for Chinese Named Entity Recognition.
4.2 英文NER类数据集
| 名称 | 年份 | 来源 | 标签数 | 地址 |
|---|---|---|---|---|
| MUC-6 | 1995 | Wall Street Journal | 7 | https://catalog.ldc.upenn.edu/LDC2003T13 |
| MUC-6 Plus | 1995 | Additional news to MUC-6 | 7 | https://catalog.ldc.upenn.edu/LDC96T10 |
| MUC-7 | 1997 | New York Times news | 7 | https://catalog.ldc.upenn.edu/LDC2001T02 |
| CoNLL03 | 2003 | Reuters news | 4 | https://www.clips.uantwerpen.be/conll2003/ner/ |
| ACE | 2000 - 2008 | Transcripts, news | 7 | https://www.ldc.upenn.edu/collaborations/past-projects/ace |
| OntoNotes | 2007 - 2012 | Magazine, news, web, etc. | 18 | https://catalog.ldc.upenn.edu/LDC2013T19 |
| W-NUT | 2015 - 2018 | User-generated text | 6/10 | http://noisy-text.github.io |
| BBN | 2005 | Wall Street Journal | 64 | https://catalog.ldc.upenn.edu/LDC2005T33 |
| WikiGold | 2009 | Wikipedia | 4 | https://figshare.com/articles/Learning_multilingual_named_entity_recognition_from_Wikipedia/5462500 |
| WiNER | 2012 | Wikipedia | 4 | http://rali.iro.umontreal.ca/rali/en/winer-wikipedia-for-ner |
| WikiFiger | 2012 | Wikipedia | 112 | https://github.com/xiaoling/figer |
| HYENA | 2012 | Wikipedia | 505 | https://www.mpi-inf.mpg.de/departments/databases-andinformation-systems/research/yago-naga/hyena |
| N3 | 2014 | News | 3 | http://aksw.org/Projects/N3NERNEDNIF.html |
| Gillick | 2016 | Magazine, news, web, etc. | 89 | https://arxiv.org/e-print/1412.1820v2 |
| FG-NER | 2018 | Various | 200 | https://fgner.alt.ai/ |
| NNE | 2019 | Newswire | 114 | https://github.com/nickyringland/nested_named_entities |
| GENIA | 2004 | Biology and clinical text | 36 | http://www.geniaproject.org/home |
| GENETAG | 2005 | MEDLINE | 2 | https://sourceforge.net/projects/bioc/files/ |
| FSU-PRGE | 2010 | PubMed and MEDLINE | 5 | https://julielab.de/Resources/FSU_PRGE.html |
| NCBI-Disease | 2014 | PubMed | 1 | https://www.ncbi.nlm.nih.gov/CBBresearch/Dogan/DISEASE/ |
| BC5CDR | 2015 | PubMed | 3 | http://bioc.sourceforge.net/ |
| DFKI | 2018 | Business news and social media | 7 | https://dfki-lt-re-group.bitbucket.io/product-corpus/ |
4.3 中文NER类数据集
4.4 英文NER类工具
| 名称 | 来源 |
|---|---|
| StanfordCoreNLP | https://stanfordnlp.github.io/CoreNLP/ |
| OSU Twitter NLP | https://github.com/aritter/twitter_nlp |
| Illinois NLP | http://cogcomp.org/page/software/ |
| NeuroNER | http://neuroner.com/ |
| NERsuite | http://nersuite.nlplab.org/ |
| Polyglot | https://polyglot.readthedocs.io |
| Gimli | http://bioinformatics.ua.pt/gimli |
| spaCy | https://spacy.io/api/entityrecognizer |
| NLTK | https://www.nltk.org |
| OpenNLP | https://opennlp.apache.org/ |
| LingPipe | http://alias-i.com/lingpipe-3.9.3/ |
| AllenNLP | https://demo.allennlp.org/ |
| IBM Watson | https://natural-language-understandingdemo.ng.bluemix.net |
| FG-NER | https://fgner.alt.ai/extractor/ |
| Intellexer | http://demo.intellexer.com/ |
| Repustate | https://repustate.com/named-entityrecognition-api-demo |
| AYLIEN | https://developer.aylien.com/text-api-demo |
| Dandelion API | https://dandelion.eu/semantic-text/entityextraction-demo |
| displaCy | https://explosion.ai/demos/displacy-ent |
| ParallelDots | https://www.paralleldots.com/namedentity-recognition |
| TextRazor | https://www.textrazor.com/named_entity_recognition |
4.5 中文NER类工具
斯坦福大学的Stanza和CoreNLP
百度的Paddle Lac,哈工大的LTP,Jieba,SnowNLP,PKUSeg,Thulac,HanLP,FoolNLTK