1 数据探索
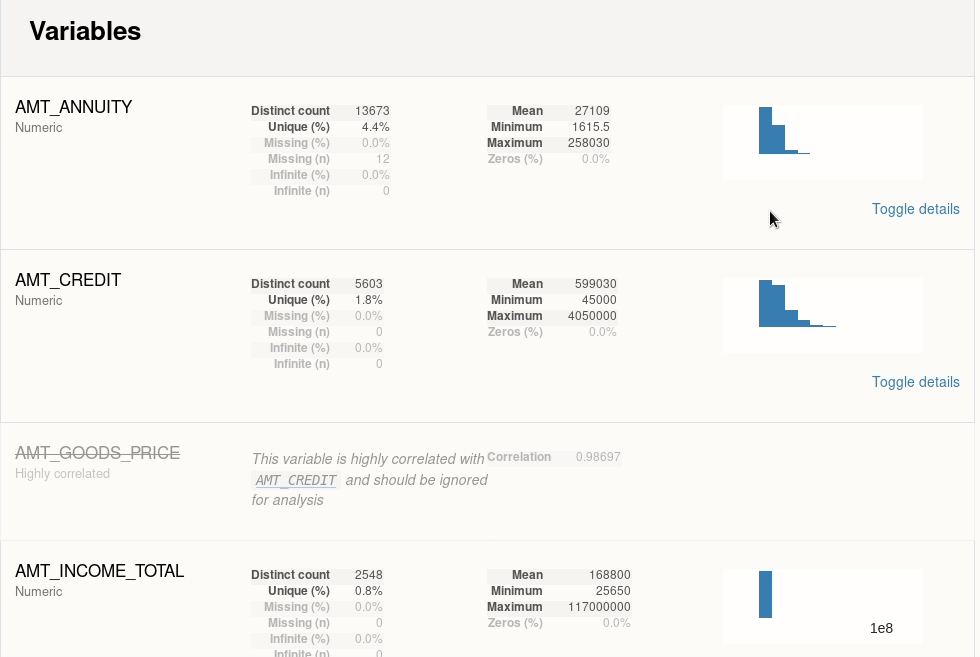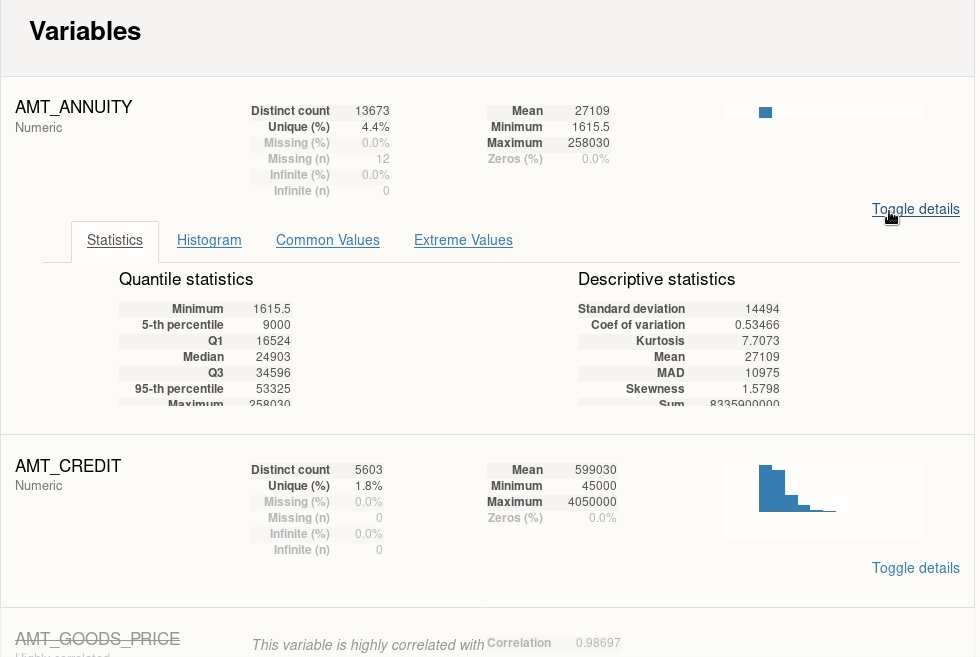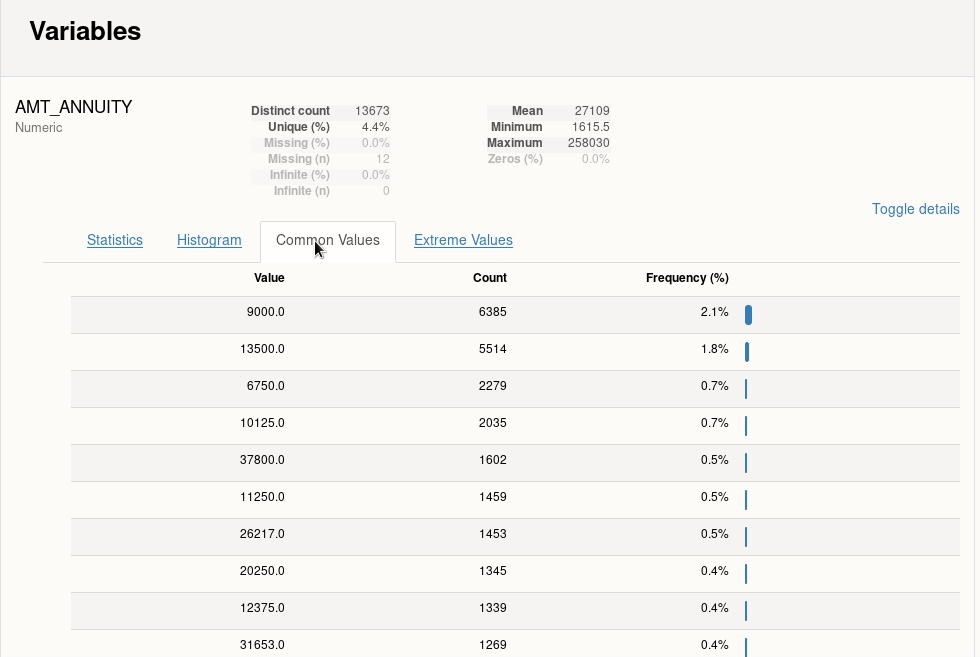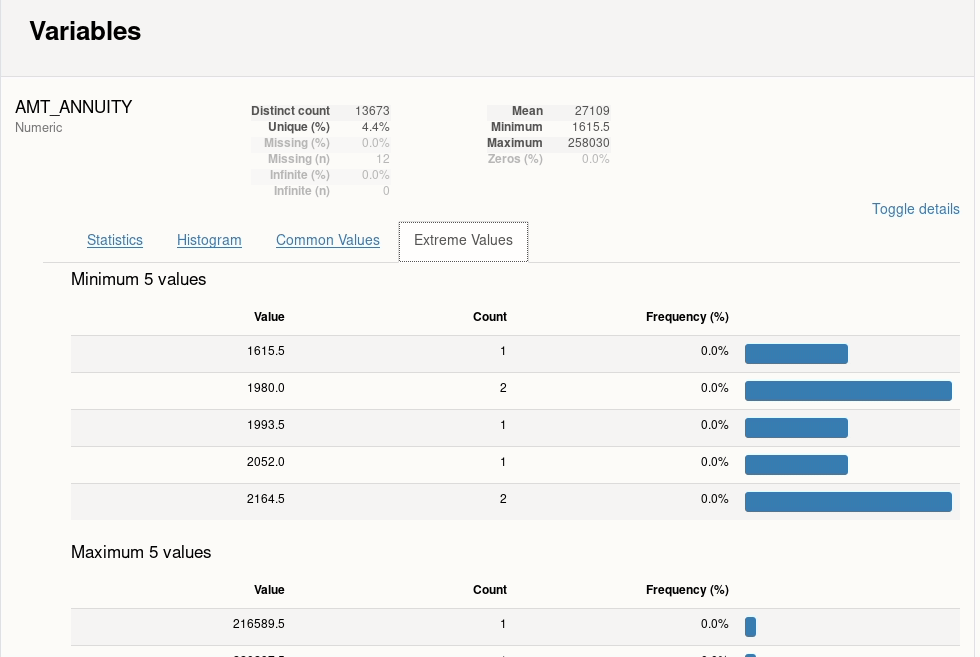
1.1 ydata-profiling-自动化数据探索
一行代码完成针对DataFrame的探索性数据分析(EDA)
主要特性:
- 类型推断、单变量分析、多变量分析、数据比较
- 支持时序、文本、图像、文件等内容格式;支持多格式输出
简单示例:
1.2 missingno-数据缺失可视化
对数据集的完整性/缺失度进行可视化
简单示例:
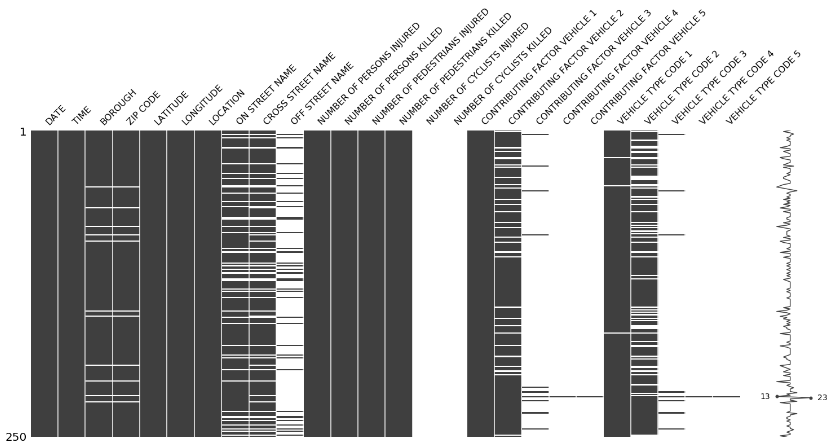
项目地址 3.7k⭐
1.3 LIDA-基于AI的自动数据可视化
数据汇总、目标探索、可视化生成、信息图表生成
可视化解释、自我分析评估、自动修复、内容建议
项目地址 1.7k⭐
2 数据处理
2.1 JAX-提供基于GPU的数组计算
官方描述:JAX is NumPy on the CPU, GPU, and TPU, with great automatic differentiation for high-performance machine learning research.
据说计算效率很高,但debug麻烦,文档有待进一步完善(可以再观望一下)
模块地址 24.9k⭐
2.2 portion-处理区间类数据
原为python-intervals,内置区间类数据结构和常用操作
主要特性:开闭区间、间隔集、交并补、常见类型转换等等
模块地址 416⭐
2.3 imblearn-处理数据不平衡问题
主要特性:
- 内置大量降采样和过采样方法
- 对常用模块有友好的对接(比如scikit-learn、Keras等)
- 包含丰富处数据处理模板(pipeline)和不平衡数据的评价指标(metrics)
2.4 Pydantic-数据验证
主要特性
- 使用 python 类型注释来进行数据校验和 settings 管理
- pydantic 可以在代码运行时强制执行类型提示,并在数据校验无效时提供友好的错误提示
- 定义数据应该如何在规范的 python 代码中保存,然后通过 Python 验证它
- pydantic 保证输出模型的类型和约束,而不是输入数据
1_study/Python/Python 数据处理/Pydantic 数据验证与转换
3 文本分析
3.1 keyBERT-提取文本关键词和短语
主要特性:
- 余弦相似度来查找文档中与文档本身最相似的关键词/短语
- 支持n-gram模式候选词/短语,支持文本的关键字高亮
- 支持多种嵌入表示模型,可直接下拉使用Huggingface开源模型
3.2 Trafilatura-Web文本搜集与解析
Trafilatura 是一个 Python 包和命令行工具,旨在收集 Web 上的文本。它包括发现、提取和文本处理组件。其主要应用是网络爬行、下载、抓取以及主要文本、元数据和评论的提取
模块地址 2.1k⭐
3.3 JioNLP 中文 NLP 预处理/解析工具包
JioNLP 是一个面向 NLP 开发者的工具包,提供 NLP 任务预处理、解析功能,准确、高效、零使用门槛。
主要功能:分词、情感分析、文本分类、NER、词典、文本读写、常用正则抽取、数据增强、其他小工具
模块地址 2.8k⭐
4 模型解释
4.1 InterpretML-机器学习可解释性技术整合
InterpretML 是一个开源包,将最先进的机器学习可解释性技术整合到了一起。使用此软件包,您可以训练可解释的玻璃盒模型并解释黑盒系统。 InterpretML 可帮助您了解模型的全局行为,或了解各个预测背后的原因
模块地址 5.7k⭐
5 辅助工具
5.1 ToolLLM-基于外部API的大模型调优
- 从 RapidAPI Hub 收集了 16,464 个真实世界的 RESTful API
- 提示 ChatGPT 生成涉及这些 API 的各种人工指令(ToolBench)
- 使用 ChatGPT 为每条指令搜索有效的解决方案路径(API 调用链)
- 基于ToolBench微调的LLaMA表现出与ChatGPT 相当的性能
模块地址 3.4k⭐
5.2 Outlines-文本生成的引导和约束
- 提供保证输出与正则表达式匹配或遵循 JSON 模式的生成方法
- 提供了强大的提示原语,将提示与执行逻辑分开
- 兼容广泛的Python生态系统和不同的模型类型
模块地址 3k⭐
5.3 obsidiantools-抽取obsidian笔记的元数据
体验效果:
- 可以一行代码导出obsidian笔记的结构化元数据
- 支持知识图的可视化和常见的图搜索方法
- 抽取过程较慢,不支持动态更新,适合离线分析
模块地址 291⭐
5.4 EasyLiterature-自动文献管理
- 自动收集并在Markdown文件中完善相关信息
- 下载论文的PDF到本地机器,并将PDF链接到Markdown文件中的论文
- 永久保存实时编辑的论文PDF和Markdown中的笔记,方便论文一站式分类和管理
模块地址 98⭐
6 性能优化
6.1 Ray-分布式AI运算与加速
Ray 是用于扩展 AI 和 Python 应用程序的统一框架。 Ray 由一个核心分布式运行时和一组用于加速 ML 工作负载的 AI 库组成;Ray 可以将相同的代码从笔记本电脑无缝扩展到集群
项目地址 28.1k⭐
6.2 Mojo-兼容Python语法的高性能语言
Mojo 是一种新的编程语言,通过将 Python 语法和生态系统与系统编程和元编程功能相结合,借鉴学习其他语言的特点和优势,弥合了研究和生产之间的差距
2_object/computer/Mojo 编程语言 15k⭐
7 垂直领域
7.1 Qlib-面向AI的量化投资平台
Qlib是由微软亚洲研究院推出的AI 量化投资平台,旨在利用人工智能技术在量化投资中实现潜力、赋能研究、创造价值,从探索创意到实施生产。Qlib 支持多种机器学习建模范式。包括监督学习、市场动态建模和强化学习。
模块地址 12.6k⭐
7.2 TA-LIB-内置 150+量化指标计算器
TA-Lib 广泛应用与交易软件,和金融市场数据进行技术分析
- 包括 ADX、MACD、RSI、随机指标、布林带等 150+ 指标
- 包括 K 线形态识别,适用于 C/C++、Java、Perl、Python 的开源 API
模块地址 8.5k⭐
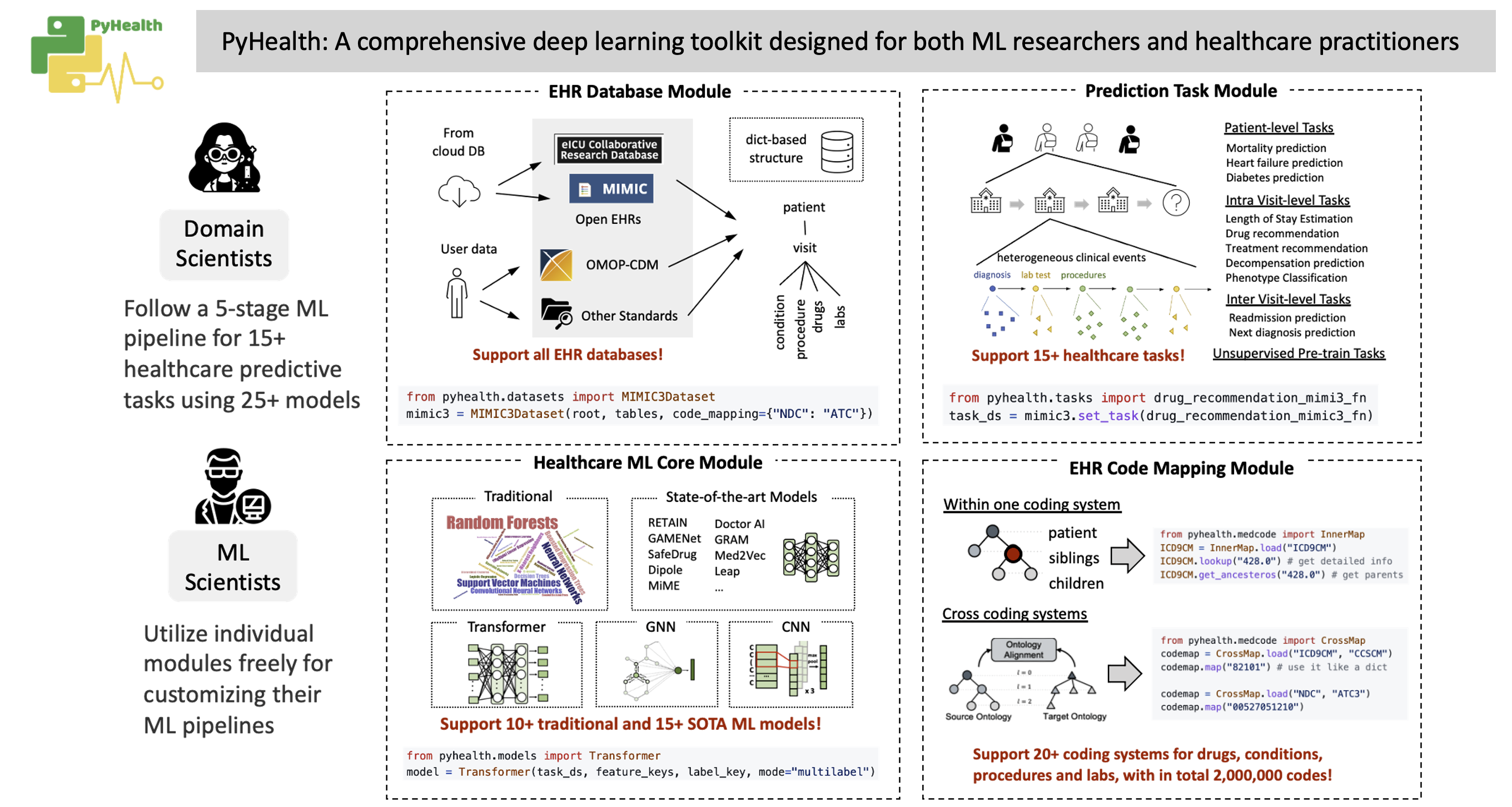
7.3 PyHealth-临床预测的深度学习工具包
PyHealth 是一个用于支持临床预测建模的综合深度学习工具包,专为 ML 研究人员和医疗从业者设计。我们可以使您的医疗保健人工智能应用程序更易于部署、更加灵活和可定制
模块地址 849⭐