1 门控循环单元(GRU)
1.1 GRU概述
1_study/DeepLearning/基础神经网络/循环神经网络#GRU
1.2 代码实现与训练
PyTorch版本从零实现:
import torch
from torch import nn
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
# 借助标准差为0.01的高斯分布初始化模型参数,偏置项置零
def get_params(vocab_size, num_hiddens, device):
num_inputs = num_outputs = vocab_size
def normal(shape):
return torch.randn(size=shape, device=device)*0.01
def three():
return (normal((num_inputs, num_hiddens)),
normal((num_hiddens, num_hiddens)),
torch.zeros(num_hiddens, device=device))
W_xz, W_hz, b_z = three() # 更新门参数
W_xr, W_hr, b_r = three() # 重置门参数
W_xh, W_hh, b_h = three() # 候选隐状态参数
# 输出层参数
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
# 附加梯度
params = [W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q]
for param in params:
param.requires_grad_(True)
return params
# 隐状态的初始化
def init_gru_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device), )
# 定义GRU
def gru(inputs, state, params):
W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q = params
H, = state
outputs = []
for X in inputs:
Z = torch.sigmoid((X @ W_xz) + (H @ W_hz) + b_z)
R = torch.sigmoid((X @ W_xr) + (H @ W_hr) + b_r)
H_tilda = torch.tanh((X @ W_xh) + ((R * H) @ W_hh) + b_h)
H = Z * H + (1 - Z) * H_tilda
Y = H @ W_hq + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H,)
# 训练与预测
vocab_size, num_hiddens, device = len(vocab), 256, d2l.try_gpu()
num_epochs, lr = 500, 1
model = d2l.RNNModelScratch(len(vocab), num_hiddens, device, get_params,
init_gru_state, gru)
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
# perplexity 1.1, 25850.3 tokens/sec on cuda:0
# time traveller but now you begin to seethe object of my investig
# traveller fir to yy m stad a fourth dimensioni have not sai
PyTorch版本简洁实现(效率明显更高):
num_inputs = vocab_size
gru_layer = nn.GRU(num_inputs, num_hiddens)
model = d2l.RNNModel(gru_layer, len(vocab))
model = model.to(device)
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
# perplexity 1.0, 251738.0 tokens/sec on cuda:0
# time traveller for so it will be convenient to speak of himwas e
# travelleryou can show black is white by argument said filby
Tensorflow版本从零实现:
import tensorflow as tf
from d2l import tensorflow as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
# 借助标准差为0.01的高斯分布初始化模型参数,偏置项置零
def get_params(vocab_size, num_hiddens):
num_inputs = num_outputs = vocab_size
def normal(shape):
return tf.random.normal(shape=shape,stddev=0.01,mean=0,dtype=tf.float32)
def three():
return (tf.Variable(normal((num_inputs, num_hiddens)), dtype=tf.float32),
tf.Variable(normal((num_hiddens, num_hiddens)), dtype=tf.float32),
tf.Variable(tf.zeros(num_hiddens), dtype=tf.float32))
W_xz, W_hz, b_z = three() # 更新门参数
W_xr, W_hr, b_r = three() # 重置门参数
W_xh, W_hh, b_h = three() # 候选隐状态参数
# 输出层参数
W_hq = tf.Variable(normal((num_hiddens, num_outputs)), dtype=tf.float32)
b_q = tf.Variable(tf.zeros(num_outputs), dtype=tf.float32)
params = [W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q]
return params
# 隐状态的初始化
def init_gru_state(batch_size, num_hiddens):
return (tf.zeros((batch_size, num_hiddens)), )
# 定义GRU
def gru(inputs, state, params):
W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q = params
H, = state
outputs = []
for X in inputs:
X = tf.reshape(X,[-1,W_xh.shape[0]])
Z = tf.sigmoid(tf.matmul(X, W_xz) + tf.matmul(H, W_hz) + b_z)
R = tf.sigmoid(tf.matmul(X, W_xr) + tf.matmul(H, W_hr) + b_r)
H_tilda = tf.tanh(tf.matmul(X, W_xh) + tf.matmul(R * H, W_hh) + b_h)
H = Z * H + (1 - Z) * H_tilda
Y = tf.matmul(H, W_hq) + b_q
outputs.append(Y)
return tf.concat(outputs, axis=0), (H,)
# 训练与预测
vocab_size, num_hiddens, device_name = len(vocab), 256, d2l.try_gpu()._device_name
# 定义训练策略
strategy = tf.distribute.OneDeviceStrategy(device_name)
num_epochs, lr = 500, 1
with strategy.scope():
model = d2l.RNNModelScratch(len(vocab), num_hiddens, init_gru_state, gru, get_params)
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, strategy)
# perplexity 1.3, 4530.4 tokens/sec on /GPU:0
# time traveller after the paing travel indific pravile to the ger
# traveller after the painescemelt a see in oneplestor shall
Tensorflow版本简洁实现(效率明显更高):
gru_cell = tf.keras.layers.GRUCell(num_hiddens,
kernel_initializer='glorot_uniform')
gru_layer = tf.keras.layers.RNN(gru_cell, time_major=True,
return_sequences=True, return_state=True)
device_name = d2l.try_gpu()._device_name
strategy = tf.distribute.OneDeviceStrategy(device_name)
with strategy.scope():
model = d2l.RNNModel(gru_layer, vocab_size=len(vocab))
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, strategy)
2 长短期记忆网络(LSTM)
2.1 LSTM 概述
1_study/DeepLearning/基础神经网络/循环神经网络#LSTM
2.2 代码实现与训练
PyTorch版本从零实现:
import torch
from torch import nn
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
def get_lstm_params(vocab_size, num_hiddens, device):
num_inputs = num_outputs = vocab_size
def normal(shape):
return torch.randn(size=shape, device=device)*0.01
def three():
return (normal((num_inputs, num_hiddens)),
normal((num_hiddens, num_hiddens)),
torch.zeros(num_hiddens, device=device))
W_xi, W_hi, b_i = three() # 输入门参数
W_xf, W_hf, b_f = three() # 遗忘门参数
W_xo, W_ho, b_o = three() # 输出门参数
W_xc, W_hc, b_c = three() # 候选记忆元参数
# 输出层参数
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
# 附加梯度
params = [W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc,
b_c, W_hq, b_q]
for param in params:
param.requires_grad_(True)
return params
def init_lstm_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device),
torch.zeros((batch_size, num_hiddens), device=device))
def lstm(inputs, state, params):
[W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c,
W_hq, b_q] = params
(H, C) = state
outputs = []
for X in inputs:
I = torch.sigmoid((X @ W_xi) + (H @ W_hi) + b_i)
F = torch.sigmoid((X @ W_xf) + (H @ W_hf) + b_f)
O = torch.sigmoid((X @ W_xo) + (H @ W_ho) + b_o)
C_tilda = torch.tanh((X @ W_xc) + (H @ W_hc) + b_c)
C = F * C + I * C_tilda
H = O * torch.tanh(C)
Y = (H @ W_hq) + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H, C)
vocab_size, num_hiddens, device = len(vocab), 256, d2l.try_gpu()
num_epochs, lr = 500, 1
model = d2l.RNNModelScratch(len(vocab), num_hiddens, device, get_lstm_params,
init_lstm_state, lstm)
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
# perplexity 1.3, 22457.5 tokens/sec on cuda:0
# time traveller came back andfilby s anecofo cennom think so i gh
# traveller but becan his of the incitan velines abyout his f
PyTorch版本简洁实现(效率明显更高):
num_inputs = vocab_size
lstm_layer = nn.LSTM(num_inputs, num_hiddens)
model = d2l.RNNModel(lstm_layer, len(vocab))
model = model.to(device)
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
# perplexity 1.1, 308523.7 tokens/sec on cuda:0
# time travelleryou can show black is white by argument said filby
# traveller with a slight accession ofcheerfulness really thi
Tensorflow版本从零实现:
import tensorflow as tf
from d2l import tensorflow as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
def get_lstm_params(vocab_size, num_hiddens):
num_inputs = num_outputs = vocab_size
def normal(shape):
return tf.Variable(tf.random.normal(shape=shape, stddev=0.01,
mean=0, dtype=tf.float32))
def three():
return (normal((num_inputs, num_hiddens)),
normal((num_hiddens, num_hiddens)),
tf.Variable(tf.zeros(num_hiddens), dtype=tf.float32))
W_xi, W_hi, b_i = three() # 输入门参数
W_xf, W_hf, b_f = three() # 遗忘门参数
W_xo, W_ho, b_o = three() # 输出门参数
W_xc, W_hc, b_c = three() # 候选记忆元参数
# 输出层参数
W_hq = normal((num_hiddens, num_outputs))
b_q = tf.Variable(tf.zeros(num_outputs), dtype=tf.float32)
# 附加梯度
params = [W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc,
b_c, W_hq, b_q]
return params
def init_lstm_state(batch_size, num_hiddens):
return (tf.zeros(shape=(batch_size, num_hiddens)),
tf.zeros(shape=(batch_size, num_hiddens)))
def lstm(inputs, state, params):
W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c, W_hq, b_q = params
(H, C) = state
outputs = []
for X in inputs:
X=tf.reshape(X,[-1,W_xi.shape[0]])
I = tf.sigmoid(tf.matmul(X, W_xi) + tf.matmul(H, W_hi) + b_i)
F = tf.sigmoid(tf.matmul(X, W_xf) + tf.matmul(H, W_hf) + b_f)
O = tf.sigmoid(tf.matmul(X, W_xo) + tf.matmul(H, W_ho) + b_o)
C_tilda = tf.tanh(tf.matmul(X, W_xc) + tf.matmul(H, W_hc) + b_c)
C = F * C + I * C_tilda
H = O * tf.tanh(C)
Y = tf.matmul(H, W_hq) + b_q
outputs.append(Y)
return tf.concat(outputs, axis=0), (H,C)
vocab_size, num_hiddens, device_name = len(vocab), 256, d2l.try_gpu()._device_name
num_epochs, lr = 500, 1
strategy = tf.distribute.OneDeviceStrategy(device_name)
with strategy.scope():
model = d2l.RNNModelScratch(len(vocab), num_hiddens, init_lstm_state, lstm, get_lstm_params)
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, strategy)
# perplexity 1.1, 3739.6 tokens/sec on /GPU:0
# time travelleritwe can i he earse p and lis some thy onl of the
# traveller he mad been got a ovellook of hos dimension with
Tensorflow版本简洁实现(效率明显更高):
lstm_cell = tf.keras.layers.LSTMCell(num_hiddens,
kernel_initializer='glorot_uniform')
lstm_layer = tf.keras.layers.RNN(lstm_cell, time_major=True,
return_sequences=True, return_state=True)
device_name = d2l.try_gpu()._device_name
strategy = tf.distribute.OneDeviceStrategy(device_name)
with strategy.scope():
model = d2l.RNNModel(lstm_layer, vocab_size=len(vocab))
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, strategy)
# perplexity 1.1, 8103.6 tokens/sec on /GPU:0
# time travelleryou can show black is white by argument said filby
# traveller with a slight accession ofcheerfulness really thi
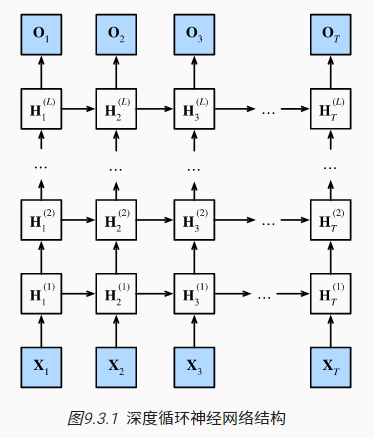
3 深度循环卷积
为了获得更强的非线性拟合能力,将普通循环神经网络的单隐藏层扩展为多隐藏层,当前时刻的每一层隐状态信息都会被传递到当前层的下一时刻和下一层的当前时刻。
PyTorch版本简洁实现:
import torch
from torch import nn
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
vocab_size, num_hiddens, num_layers = len(vocab), 256, 2
num_inputs = vocab_size
device = d2l.try_gpu()
lstm_layer = nn.LSTM(num_inputs, num_hiddens, num_layers)
model = d2l.RNNModel(lstm_layer, len(vocab))
model = model.to(device)
num_epochs, lr = 500, 2
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
# perplexity 1.0, 222604.4 tokens/sec on cuda:0
# time traveller for so it will be convenient to speak of himwas e
# travelleryou can show black is white by argument said filby
4 双向循环神经网络
序列的预测一般都是借助前段序列进行后续的预测,但有时也需要考虑后段序列的信息,比如完形填空类任务就需要结合上下文信息进行综合考虑
针对此类问题,可以将序列反向循环(从最后一个词元到第一个),然后拼接正向循环的抽取信息,从而构建出双向循环神经网络(bidirectional RNNs)
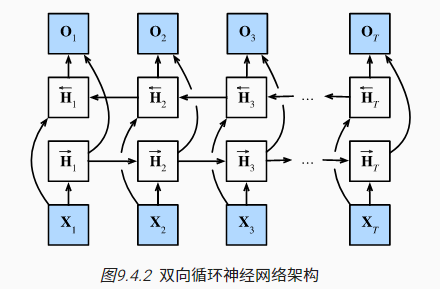
上图中,$\overleftarrow{H}_t$表示反向隐状态,由当前时刻的输入$X_t$和下一刻的隐状态$\overleftarrow{H}_{t+1}$决定
双向循环神经网络能更充分的利用上下文的信息,但由于双向的递归之间存在依赖关系,所以梯度求解过程复杂,模型整体效率偏低。
此类模型常用于完形填空、词元分类(比如命名实体识别)和机器翻译等场景。不适用于对未来信息的预测(因为反向循环过程已经引用了未来信息)
在PyTorch中通过设置LSTM层的参数bidirective=True,即可快速定义双向LSTM模型
5 机器翻译与数据集
机器翻译将文本序列从一种语言自动翻译成另一种语言,是一种典型的序列转换模型(sequence transduction)的问题,也是验证语言模型的常见基准测试
本小节推荐的入门数据集为Tatoeba项目的“英-法”双语句子对,该项目也包含很多其他常见语种与英语的双语句子对
常见的文本预处理技巧:
- 用空格代替不间断空格(non-breaking space)
- 小写字母替换大写字母,单词和标点符号间插入空格
- 将出现次数少于2的低频率词元视为未知(
<unk>)词元 - 通过截断(truncation)和 填充(padding)确保输入序列长度一致
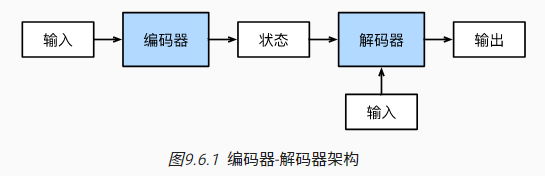
6 编码器-解码器架构
序列转换模型(比如机器翻译)的输入和输出都是长度可变的序列,编码器-解码器(encoder-decoder)架构常用于处理这类问题:
- 编码器将长度可变的序列作为输入,并将其转换为具有固定形状的编码状态
- 解码器将具有固定形状的编码状态映射为长度可变的序列
PyTorch版编码器-解码器架构的实现:
from torch import nn
#@save
class Encoder(nn.Module):
"""编码器-解码器架构的基本编码器接口"""
def __init__(self, **kwargs):
super(Encoder, self).__init__(**kwargs)
def forward(self, X, *args):
raise NotImplementedError
#@save
class Decoder(nn.Module):
"""编码器-解码器架构的基本解码器接口"""
def __init__(self, **kwargs):
super(Decoder, self).__init__(**kwargs)
def init_state(self, enc_outputs, *args):
raise NotImplementedError
def forward(self, X, state):
raise NotImplementedError
#@save
class EncoderDecoder(nn.Module):
"""编码器-解码器架构的基类"""
def __init__(self, encoder, decoder, **kwargs):
super(EncoderDecoder, self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
def forward(self, enc_X, dec_X, *args):
enc_outputs = self.encoder(enc_X, *args)
dec_state = self.decoder.init_state(enc_outputs, *args)
return self.decoder(dec_X, dec_state)
Tensorflow版编码器-解码器架构的实现:
import tensorflow as tf
#@save
class Encoder(tf.keras.layers.Layer):
"""编码器-解码器架构的基本编码器接口"""
def __init__(self, **kwargs):
super(Encoder, self).__init__(**kwargs)
def call(self, X, *args, **kwargs):
raise NotImplementedError
#@save
class Decoder(tf.keras.layers.Layer):
"""编码器-解码器架构的基本解码器接口"""
def __init__(self, **kwargs):
super(Decoder, self).__init__(**kwargs)
def init_state(self, enc_outputs, *args):
raise NotImplementedError
def call(self, X, state, **kwargs):
raise NotImplementedError
#@save
class EncoderDecoder(tf.keras.Model):
"""编码器-解码器架构的基类"""
def __init__(self, encoder, decoder, **kwargs):
super(EncoderDecoder, self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
def call(self, enc_X, dec_X, *args, **kwargs):
enc_outputs = self.encoder(enc_X, *args, **kwargs)
dec_state = self.decoder.init_state(enc_outputs, *args)
return self.decoder(dec_X, dec_state, **kwargs)
7 序列到序列学习(seq2seq)
编码器-解码器架构常用于序列到序列(sequence to sequence,seq2seq)类学习任务
7.1 seq2seq模型实战-机器翻译
本小节将围绕“英-法”数据集实现一个seq2seq的机器翻译模型,其大致流程如下:
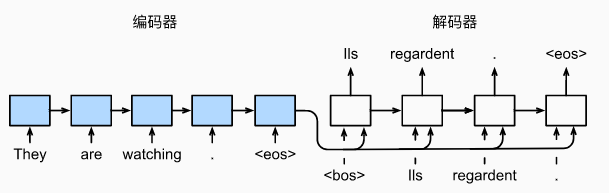
- 使用了嵌入层(embedding layer) 来获得输入序列中每个词元的特征向量
- 将多层的RNN类层作为解码器,输入词元特征和上一刻的隐状态,输出多层隐状态(张量)
- 构建另一个RNN类层作为编码器,并用解码器的输出隐状态初始化编码器的隐状态(因此需要确保两个RNN类层是结构相同的)
- 解码器的输入包括上一刻的解码器输出、上一刻的隐状态以及上下文变量(对整个输入序列进行编码后得到的全局信息,可简化为最后时间步的隐状态)
- 解码器依次输出翻译后的词元和隐状态,最后通过全连接层转换为词元预测概率分布
损失函数说明:
- 由于模型输出了词元的预测概率分布,所以可以使用交叉熵损失函数
- 为了确保序列的长度一致,模型引入了填充词元,这类词元需要排除在损失函数的计算之外。具体来说,一般会将填充词元的对应权重置零,确保其不参与整体损失的计算
预测序列的评估:BLEU
7.2 seq2seq模型实现(PyTorch)
基于PyTorch实现seq2seq的机器翻译模型:
import collections
import math
import torch
from torch import nn
from d2l import torch as d2l
#@save
class Seq2SeqEncoder(d2l.Encoder):
"""用于序列到序列学习的循环神经网络编码器"""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqEncoder, self).__init__(**kwargs)
# 嵌入层
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(embed_size, num_hiddens, num_layers,
dropout=dropout)
def forward(self, X, *args):
# 输出'X'的形状:(batch_size,num_steps,embed_size)
X = self.embedding(X)
# 在循环神经网络模型中,第一个轴对应于时间步
X = X.permute(1, 0, 2)
# 如果未提及状态,则默认为0
output, state = self.rnn(X)
# output的形状:(num_steps,batch_size,num_hiddens)
# state[0]的形状:(num_layers,batch_size,num_hiddens)
return output, state
class Seq2SeqDecoder(d2l.Decoder):
"""用于序列到序列学习的循环神经网络解码器"""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqDecoder, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(embed_size + num_hiddens, num_hiddens, num_layers,
dropout=dropout)
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, *args):
return enc_outputs[1]
def forward(self, X, state):
# 输出'X'的形状:(batch_size,num_steps,embed_size)
X = self.embedding(X).permute(1, 0, 2)
# 广播context,使其具有与X相同的num_steps
context = state[-1].repeat(X.shape[0], 1, 1)
X_and_context = torch.cat((X, context), 2)
output, state = self.rnn(X_and_context, state)
output = self.dense(output).permute(1, 0, 2)
# output的形状:(batch_size,num_steps,vocab_size)
# state[0]的形状:(num_layers,batch_size,num_hiddens)
return output, state
#@save
def sequence_mask(X, valid_len, value=0):
"""在序列中屏蔽不相关的项"""
maxlen = X.size(1)
mask = torch.arange((maxlen), dtype=torch.float32,
device=X.device)[None, :] < valid_len[:, None]
X[~mask] = value
return X
#@save
class MaskedSoftmaxCELoss(nn.CrossEntropyLoss):
"""带遮蔽的softmax交叉熵损失函数"""
# pred的形状:(batch_size,num_steps,vocab_size)
# label的形状:(batch_size,num_steps)
# valid_len的形状:(batch_size,)
def forward(self, pred, label, valid_len):
weights = torch.ones_like(label)
weights = sequence_mask(weights, valid_len)
self.reduction='none'
unweighted_loss = super(MaskedSoftmaxCELoss, self).forward(
pred.permute(0, 2, 1), label)
weighted_loss = (unweighted_loss * weights).mean(dim=1)
return weighted_loss
#@save
def train_seq2seq(net, data_iter, lr, num_epochs, tgt_vocab, device):
"""训练序列到序列模型"""
def xavier_init_weights(m):
if type(m) == nn.Linear:
nn.init.xavier_uniform_(m.weight)
if type(m) == nn.GRU:
for param in m._flat_weights_names:
if "weight" in param:
nn.init.xavier_uniform_(m._parameters[param])
net.apply(xavier_init_weights)
net.to(device)
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
loss = MaskedSoftmaxCELoss()
net.train()
animator = d2l.Animator(xlabel='epoch', ylabel='loss',
xlim=[10, num_epochs])
for epoch in range(num_epochs):
timer = d2l.Timer()
metric = d2l.Accumulator(2) # 训练损失总和,词元数量
for batch in data_iter:
optimizer.zero_grad()
X, X_valid_len, Y, Y_valid_len = [x.to(device) for x in batch]
bos = torch.tensor([tgt_vocab['<bos>']] * Y.shape[0],
device=device).reshape(-1, 1)
dec_input = torch.cat([bos, Y[:, :-1]], 1) # 强制教学
Y_hat, _ = net(X, dec_input, X_valid_len)
l = loss(Y_hat, Y, Y_valid_len)
l.sum().backward() # 损失函数的标量进行“反向传播”
d2l.grad_clipping(net, 1)
num_tokens = Y_valid_len.sum()
optimizer.step()
with torch.no_grad():
metric.add(l.sum(), num_tokens)
if (epoch + 1) % 10 == 0:
animator.add(epoch + 1, (metric[0] / metric[1],))
print(f'loss {metric[0] / metric[1]:.3f}, {metric[1] / timer.stop():.1f} '
f'tokens/sec on {str(device)}')
embed_size, num_hiddens, num_layers, dropout = 32, 32, 2, 0.1
batch_size, num_steps = 64, 10
lr, num_epochs, device = 0.005, 300, d2l.try_gpu()
train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
encoder = Seq2SeqEncoder(len(src_vocab), embed_size, num_hiddens, num_layers,
dropout)
decoder = Seq2SeqDecoder(len(tgt_vocab), embed_size, num_hiddens, num_layers,
dropout)
net = d2l.EncoderDecoder(encoder, decoder)
train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
# loss 0.020, 11208.3 tokens/sec on cuda:0
#@save
def predict_seq2seq(net, src_sentence, src_vocab, tgt_vocab, num_steps,
device, save_attention_weights=False):
"""序列到序列模型的预测"""
# 在预测时将net设置为评估模式
net.eval()
src_tokens = src_vocab[src_sentence.lower().split(' ')] + [
src_vocab['<eos>']]
enc_valid_len = torch.tensor([len(src_tokens)], device=device)
src_tokens = d2l.truncate_pad(src_tokens, num_steps, src_vocab['<pad>'])
# 添加批量轴
enc_X = torch.unsqueeze(
torch.tensor(src_tokens, dtype=torch.long, device=device), dim=0)
enc_outputs = net.encoder(enc_X, enc_valid_len)
dec_state = net.decoder.init_state(enc_outputs, enc_valid_len)
# 添加批量轴
dec_X = torch.unsqueeze(torch.tensor(
[tgt_vocab['<bos>']], dtype=torch.long, device=device), dim=0)
output_seq, attention_weight_seq = [], []
for _ in range(num_steps):
Y, dec_state = net.decoder(dec_X, dec_state)
# 我们使用具有预测最高可能性的词元,作为解码器在下一时间步的输入
dec_X = Y.argmax(dim=2)
pred = dec_X.squeeze(dim=0).type(torch.int32).item()
# 保存注意力权重(稍后讨论)
if save_attention_weights:
attention_weight_seq.append(net.decoder.attention_weights)
# 一旦序列结束词元被预测,输出序列的生成就完成了
if pred == tgt_vocab['<eos>']:
break
output_seq.append(pred)
return ' '.join(tgt_vocab.to_tokens(output_seq)), attention_weight_seq
def bleu(pred_seq, label_seq, k): #@save
"""计算BLEU"""
pred_tokens, label_tokens = pred_seq.split(' '), label_seq.split(' ')
len_pred, len_label = len(pred_tokens), len(label_tokens)
score = math.exp(min(0, 1 - len_label / len_pred))
for n in range(1, k + 1):
num_matches, label_subs = 0, collections.defaultdict(int)
for i in range(len_label - n + 1):
label_subs[' '.join(label_tokens[i: i + n])] += 1
for i in range(len_pred - n + 1):
if label_subs[' '.join(pred_tokens[i: i + n])] > 0:
num_matches += 1
label_subs[' '.join(pred_tokens[i: i + n])] -= 1
score *= math.pow(num_matches / (len_pred - n + 1), math.pow(0.5, n))
return score
engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):
translation, attention_weight_seq = predict_seq2seq(
net, eng, src_vocab, tgt_vocab, num_steps, device)
print(f'{eng} => {translation}, bleu {bleu(translation, fra, k=2):.3f}')
# go . => va doucement <unk> <unk> ., bleu 0.000
# i lost . => j'ai perdu ., bleu 1.000
# he's calm . => <unk> ça ., bleu 0.000
# i'm home . => je suis chez aller ., bleu 0.752
7.3 seq2seq模型实现(Tensorflow)
基于PyTorch实现seq2seq的机器翻译模型:
import collections
import math
import tensorflow as tf
from d2l import tensorflow as d2l
#@save
class Seq2SeqEncoder(d2l.Encoder):
"""用于序列到序列学习的循环神经网络编码器"""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers, dropout=0, **kwargs):
super().__init__(*kwargs)
# 嵌入层
self.embedding = tf.keras.layers.Embedding(vocab_size, embed_size)
self.rnn = tf.keras.layers.RNN(tf.keras.layers.StackedRNNCells(
[tf.keras.layers.GRUCell(num_hiddens, dropout=dropout)
for _ in range(num_layers)]), return_sequences=True,
return_state=True)
def call(self, X, *args, **kwargs):
# 输入'X'的形状:(batch_size,num_steps)
# 输出'X'的形状:(batch_size,num_steps,embed_size)
X = self.embedding(X)
output = self.rnn(X, **kwargs)
state = output[1:]
return output[0], state
class Seq2SeqDecoder(d2l.Decoder):
"""用于序列到序列学习的循环神经网络解码器"""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super().__init__(**kwargs)
self.embedding = tf.keras.layers.Embedding(vocab_size, embed_size)
self.rnn = tf.keras.layers.RNN(tf.keras.layers.StackedRNNCells(
[tf.keras.layers.GRUCell(num_hiddens, dropout=dropout)
for _ in range(num_layers)]), return_sequences=True,
return_state=True)
self.dense = tf.keras.layers.Dense(vocab_size)
def init_state(self, enc_outputs, *args):
return enc_outputs[1]
def call(self, X, state, **kwargs):
# 输出'X'的形状:(batch_size,num_steps,embed_size)
X = self.embedding(X)
# 广播context,使其具有与X相同的num_steps
context = tf.repeat(tf.expand_dims(state[-1], axis=1), repeats=X.shape[1], axis=1)
X_and_context = tf.concat((X, context), axis=2)
rnn_output = self.rnn(X_and_context, state, **kwargs)
output = self.dense(rnn_output[0])
# output的形状:(batch_size,num_steps,vocab_size)
# state是一个包含num_layers个元素的列表,每个元素的形状:(batch_size,num_hiddens)
return output, rnn_output[1:]
#@save
def sequence_mask(X, valid_len, value=0):
"""在序列中屏蔽不相关的项"""
maxlen = X.shape[1]
mask = tf.range(start=0, limit=maxlen, dtype=tf.float32)[
None, :] < tf.cast(valid_len[:, None], dtype=tf.float32)
if len(X.shape) == 3:
return tf.where(tf.expand_dims(mask, axis=-1), X, value)
else:
return tf.where(mask, X, value)
X = tf.constant([[1, 2, 3], [4, 5, 6]])
sequence_mask(X, tf.constant([1, 2]))
#@save
class MaskedSoftmaxCELoss(tf.keras.losses.Loss):
"""带遮蔽的softmax交叉熵损失函数"""
def __init__(self, valid_len):
super().__init__(reduction='none')
self.valid_len = valid_len
# pred的形状:(batch_size,num_steps,vocab_size)
# label的形状:(batch_size,num_steps)
# valid_len的形状:(batch_size,)
def call(self, label, pred):
weights = tf.ones_like(label, dtype=tf.float32)
weights = sequence_mask(weights, self.valid_len)
label_one_hot = tf.one_hot(label, depth=pred.shape[-1])
unweighted_loss = tf.keras.losses.CategoricalCrossentropy(
from_logits=True, reduction='none')(label_one_hot, pred)
weighted_loss = tf.reduce_mean((unweighted_loss*weights), axis=1)
return weighted_loss
#@save
def train_seq2seq(net, data_iter, lr, num_epochs, tgt_vocab, device):
"""训练序列到序列模型"""
optimizer = tf.keras.optimizers.Adam(learning_rate=lr)
animator = d2l.Animator(xlabel="epoch", ylabel="loss",
xlim=[10, num_epochs])
for epoch in range(num_epochs):
timer = d2l.Timer()
metric = d2l.Accumulator(2) # 训练损失总和,词元数量
for batch in data_iter:
X, X_valid_len, Y, Y_valid_len = [x for x in batch]
bos = tf.reshape(tf.constant([tgt_vocab['<bos>']] * Y.shape[0]),
shape=(-1, 1))
dec_input = tf.concat([bos, Y[:, :-1]], 1) # 强制教学
with tf.GradientTape() as tape:
Y_hat, _ = net(X, dec_input, X_valid_len, training=True)
l = MaskedSoftmaxCELoss(Y_valid_len)(Y, Y_hat)
gradients = tape.gradient(l, net.trainable_variables)
gradients = d2l.grad_clipping(gradients, 1)
optimizer.apply_gradients(zip(gradients, net.trainable_variables))
num_tokens = tf.reduce_sum(Y_valid_len).numpy()
metric.add(tf.reduce_sum(l), num_tokens)
if (epoch + 1) % 10 == 0:
animator.add(epoch + 1, (metric[0] / metric[1],))
print(f'loss {metric[0] / metric[1]:.3f}, {metric[1] / timer.stop():.1f} '
f'tokens/sec on {str(device)}')
embed_size, num_hiddens, num_layers, dropout = 32, 32, 2, 0.1
batch_size, num_steps = 64, 10
lr, num_epochs, device = 0.005, 300, d2l.try_gpu()
train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
encoder = Seq2SeqEncoder(len(src_vocab), embed_size, num_hiddens, num_layers,
dropout)
decoder = Seq2SeqDecoder(len(tgt_vocab), embed_size, num_hiddens, num_layers,
dropout)
net = d2l.EncoderDecoder(encoder, decoder)
train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
# loss 0.038, 1004.4 tokens/sec
#@save
def predict_seq2seq(net, src_sentence, src_vocab, tgt_vocab, num_steps,
save_attention_weights=False):
"""序列到序列模型的预测"""
src_tokens = src_vocab[src_sentence.lower().split(' ')] + [
src_vocab['<eos>']]
enc_valid_len = tf.constant([len(src_tokens)])
src_tokens = d2l.truncate_pad(src_tokens, num_steps, src_vocab['<pad>'])
# 添加批量轴
enc_X = tf.expand_dims(src_tokens, axis=0)
enc_outputs = net.encoder(enc_X, enc_valid_len, training=False)
dec_state = net.decoder.init_state(enc_outputs, enc_valid_len)
# 添加批量轴
dec_X = tf.expand_dims(tf.constant([tgt_vocab['<bos>']]), axis=0)
output_seq, attention_weight_seq = [], []
for _ in range(num_steps):
Y, dec_state = net.decoder(dec_X, dec_state, training=False)
# 我们使用具有预测最高可能性的词元,作为解码器在下一时间步的输入
dec_X = tf.argmax(Y, axis=2)
pred = tf.squeeze(dec_X, axis=0)
# 保存注意力权重
if save_attention_weights:
attention_weight_seq.append(net.decoder.attention_weights)
# 一旦序列结束词元被预测,输出序列的生成就完成了
if pred == tgt_vocab['<eos>']:
break
output_seq.append(pred.numpy())
return ' '.join(tgt_vocab.to_tokens(tf.reshape(output_seq,
shape = -1).numpy().tolist())), attention_weight_seq
def bleu(pred_seq, label_seq, k): #@save
"""计算BLEU"""
pred_tokens, label_tokens = pred_seq.split(' '), label_seq.split(' ')
len_pred, len_label = len(pred_tokens), len(label_tokens)
score = math.exp(min(0, 1 - len_label / len_pred))
for n in range(1, k + 1):
num_matches, label_subs = 0, collections.defaultdict(int)
for i in range(len_label - n + 1):
label_subs[' '.join(label_tokens[i: i + n])] += 1
for i in range(len_pred - n + 1):
if label_subs[' '.join(pred_tokens[i: i + n])] > 0:
num_matches += 1
label_subs[' '.join(pred_tokens[i: i + n])] -= 1
score *= math.pow(num_matches / (len_pred - n + 1), math.pow(0.5, n))
return score
engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):
translation, attention_weight_seq = predict_seq2seq(
net, eng, src_vocab, tgt_vocab, num_steps)
print(f'{eng} => {translation}, bleu {bleu(translation, fra, k=2):.3f}')
# go . => va !, bleu 1.000
# i lost . => j'ai perdu ., bleu 1.000
# he's calm . => <unk> tom ., bleu 0.000
# i'm home . => je suis certain ., bleu 0.512
8 束搜索
针对序列生成问题,RNN类解码器会在每一刻输出词元的预测概率分布,一个简单的方法的是每一刻都选择概率最高的词元进行输出,这就是贪心搜索(greedy search)
而贪心搜索的局限性在于其搜索得到的序列并不一定是全局最优的,穷举搜索(exhaustive search)能在列举输出序列的所有可能后选择出最优序列(optimal sequence)
很显然,穷举搜索的计算成本太高了,所以束搜索(beam search)是二者折中后的有效方法,即指定超参数束宽(beam size)为$k$,每次计算出词元的预测概率分布后,选择条件概率最高的前$k$个候选输出序列,然后进行下一刻的词元预测:
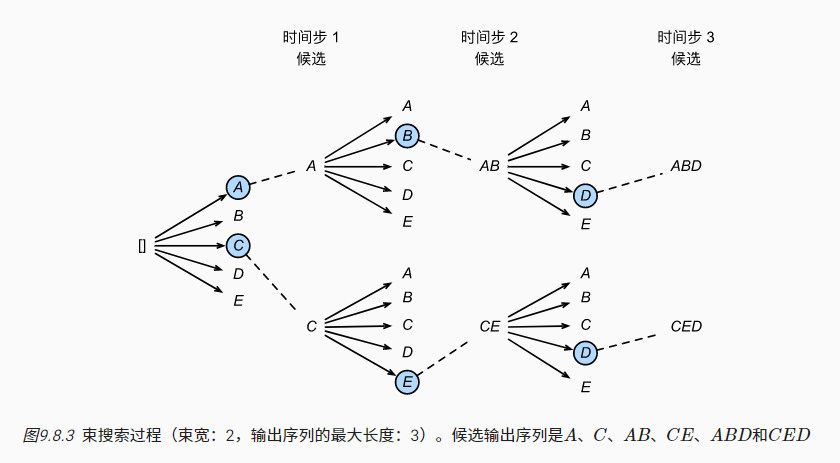
对于最终的候选序列,使用以下公式计算条件概率累积,并选择概率最高的作为最终输出: $$\frac{1}{L^{\alpha}}logP(y_1,...,y_L|c)=\frac{1}{L^{\alpha}}\Sigma_{t'=1}^n logP(y_{t'}|y_1,...,y_{t'-1},c)$$ 其中$L$表示最终候选序列的长度,$\alpha$为超参数(通常为0.75)用于增大长序列的概率权重
束搜索算法分析:
- 相比穷举搜索计算量更低,相比贪心搜索精度更高,在精度和计算代价间进行权衡
- 假设样本量为$n$,束宽为$k$,序列最大长度为$T$,束搜索的时间复杂度为$O(knT)$
- 当$k=1$时,束搜索退化为贪心搜索;如果时刻$t$时的$k=T^t$,束搜索变为穷举搜索