1 词嵌入(Word2vec)
任意两个不同的 one-hot(独热)向量余弦相似度为0:无法编码词的相似性
两个经典的word2vec模型:skip-gram和CBOW
细节可参阅:1_study/DeepLearning/基础神经网络/词嵌入表示 Embeddings#word2vec
2 用于预训练词嵌入的数据集
“华尔街日报”的文章:数据源地址
下采样:去除有用信息较少的高频词
对于数据量偏高的文本,可考虑在训练过程中迭代加载,减少内存消耗
方便起见,本小节涉及的代码已整合至下一节(预训练word2vec)
3 预训练word2vec
本小节主要为代码实现与讲解,基于PyTorch实现一个简单的word2vec:
import math
import torch
from torch import nn
from d2l import torch as d2l
#@save
def read_ptb():
"""将PTB数据集加载到文本行的列表中"""
data_dir = d2l.download_extract('ptb')
# Readthetrainingset.
with open(os.path.join(data_dir, 'ptb.train.txt')) as f:
raw_text = f.read()
return [line.split() for line in raw_text.split('\n')]
#@save
def subsample(sentences, vocab):
"""下采样高频词"""
# 排除未知词元'<unk>'
sentences = [[token for token in line if vocab[token] != vocab.unk]
for line in sentences]
counter = d2l.count_corpus(sentences)
num_tokens = sum(counter.values())
# 如果在下采样期间保留词元,则返回True
def keep(token):
return(random.uniform(0, 1) <
math.sqrt(1e-4 / counter[token] * num_tokens))
return ([[token for token in line if keep(token)] for line in sentences], counter)
#@save
def get_centers_and_contexts(corpus, max_window_size):
"""返回skip-gram模型中的中心词和上下文词"""
centers, contexts = [], []
for line in corpus:
# 要形成“中心词-上下文词”对,每个句子至少需要有2个词
if len(line) < 2:
continue
centers += line
for i in range(len(line)): # 上下文窗口中间i
window_size = random.randint(1, max_window_size)
indices = list(range(max(0, i - window_size),
min(len(line), i + 1 + window_size)))
# 从上下文词中排除中心词
indices.remove(i)
contexts.append([line[idx] for idx in indices])
return centers, contexts
#@save
def get_negatives(all_contexts, vocab, counter, K):
"""返回负采样中的噪声词"""
# 索引为1、2、...(索引0是词表中排除的未知标记)
sampling_weights = [counter[vocab.to_tokens(i)]**0.75
for i in range(1, len(vocab))]
all_negatives, generator = [], RandomGenerator(sampling_weights)
for contexts in all_contexts:
negatives = []
while len(negatives) < len(contexts) * K:
neg = generator.draw()
# 噪声词不能是上下文词
if neg not in contexts:
negatives.append(neg)
all_negatives.append(negatives)
return all_negatives
#@save
def load_data_ptb(batch_size, max_window_size, num_noise_words):
"""下载PTB数据集,然后将其加载到内存中"""
num_workers = d2l.get_dataloader_workers() # 设定读取数据的进程数
sentences = read_ptb()
vocab = d2l.Vocab(sentences, min_freq=10) # 为语料库构建一个词表
subsampled, counter = subsample(sentences, vocab) # 下采样高频词
corpus = [vocab[line] for line in subsampled]
all_centers, all_contexts = get_centers_and_contexts(
corpus, max_window_size) # 返回中心词和上下文词
all_negatives = get_negatives( # 负采样
all_contexts, vocab, counter, num_noise_words)
class PTBDataset(torch.utils.data.Dataset):
def __init__(self, centers, contexts, negatives):
assert len(centers) == len(contexts) == len(negatives)
self.centers = centers
self.contexts = contexts
self.negatives = negatives
def __getitem__(self, index):
return (self.centers[index], self.contexts[index],
self.negatives[index])
def __len__(self):
return len(self.centers)
dataset = PTBDataset(all_centers, all_contexts, all_negatives)
data_iter = torch.utils.data.DataLoader(
dataset, batch_size, shuffle=True,
collate_fn=batchify, num_workers=num_workers)
return data_iter, vocab
batch_size, max_window_size, num_noise_words = 512, 5, 5
data_iter, vocab = d2l.load_data_ptb(batch_size, max_window_size,
num_noise_words)
def skip_gram(center, contexts_and_negatives, embed_v, embed_u):
"""定义前向传播"""
v = embed_v(center)
u = embed_u(contexts_and_negatives)
pred = torch.bmm(v, u.permute(0, 2, 1))
return pred
class SigmoidBCELoss(nn.Module):
# 带掩码的二元交叉熵损失
def __init__(self):
super().__init__()
def forward(self, inputs, target, mask=None):
out = nn.functional.binary_cross_entropy_with_logits(
inputs, target, weight=mask, reduction="none")
return out.mean(dim=1)
loss = SigmoidBCELoss()
def sigmd(x): # sigmoid激活函数
return -math.log(1 / (1 + math.exp(-x)))
# 初始化模型参数
embed_size = 100
net = nn.Sequential(nn.Embedding(num_embeddings=len(vocab),
embedding_dim=embed_size),
nn.Embedding(num_embeddings=len(vocab),
embedding_dim=embed_size))
def train(net, data_iter, lr, num_epochs, device=d2l.try_gpu()):
def init_weights(m):
if type(m) == nn.Embedding:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
net = net.to(device)
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
# 辅助绘图类-Animator定义在第三章
animator = d2l.Animator(xlabel='epoch', ylabel='loss',
xlim=[1, num_epochs])
# 规范化的损失之和,规范化的损失数
metric = d2l.Accumulator(2) # 辅助计算类-Accumulator定义在第三章
for epoch in range(num_epochs):
timer, num_batches = d2l.Timer(), len(data_iter)
for i, batch in enumerate(data_iter):
optimizer.zero_grad()
center, context_negative, mask, label = [
data.to(device) for data in batch]
pred = skip_gram(center, context_negative, net[0], net[1])
l = (loss(pred.reshape(label.shape).float(), label.float(), mask)
/ mask.sum(axis=1) * mask.shape[1])
l.sum().backward()
optimizer.step()
metric.add(l.sum(), l.numel())
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(metric[0] / metric[1],))
print(f'loss {metric[0] / metric[1]:.3f}, '
f'{metric[1] / timer.stop():.1f} tokens/sec on {str(device)}')
lr, num_epochs = 0.002, 5
train(net, data_iter, lr, num_epochs) # 训练
# loss 0.410, 346244.5 tokens/sec on cuda:0
def get_similar_tokens(query_token, k, embed):
W = embed.weight.data
x = W[vocab[query_token]]
# 计算余弦相似性。增加1e-9以获得数值稳定性
cos = torch.mv(W, x) / torch.sqrt(torch.sum(W * W, dim=1) *
torch.sum(x * x) + 1e-9)
topk = torch.topk(cos, k=k+1)[1].cpu().numpy().astype('int32')
for i in topk[1:]: # 删除输入词
print(f'cosine sim={float(cos[i]):.3f}: {vocab.to_tokens(i)}')
# 应用词向量-寻找最相似的单词Top3
get_similar_tokens('chip', 3, net[0])
# cosine sim=0.695: intel
# cosine sim=0.627: desktop
# cosine sim=0.627: computer
4 全局向量的词嵌入(GloVe)
Glove模型在skip-gram模型的基础上进行改进:
- 使用全局预料计算词元间的带权重共现概率(构建共现矩阵)
- 可看作针对共现次数的回归问题,目标函数可以是平方损失函数-RMSE
- 计算损失时需要考虑样本权重(在一定范围内,共现概率越高,权重越大)
更多细节可参阅:1_study/DeepLearning/基础神经网络/词嵌入表示 Embeddings#Glove
5 子词嵌入
有的词内部存在相似的组成,比如“helps”、“helped”和“helping”等
有的词组间存在相似的结构,比如“boy”和“boyfriend”与“girl”和“girlfriend”
为了更好地利用文本中的形态信息,fastText模型提出了子词(subword)嵌入的方法。
更多细节可参阅:1_study/DeepLearning/基础神经网络/词嵌入表示 Embeddings#fasText
6 词的相似性和类比任务
网上有很多基于大量文本数据预训练的词向量模型
词向量模型的基础用法:
- 输入单词,寻找最相似的前$n$个单词
- 实现词的类比,比如国王=皇后-女人+男人
- 作为其他下游任务的输入项或编码器
7 基于Transformers的双向编码器表示(BERT)
细节可参阅:1_study/DeepLearning/基础神经网络/词嵌入表示 Embeddings#BERT
8 用于预训练BERT的数据集
原始的BERT使用图书语料库(8亿词)和英文维基百科(25亿词)进行预训练
本书中使用了较小的数据WikiText-2进行BERT训练的演示
9 预训练BERT
原始BERT有两个版本
- Base版本:12层Transformer编码器块+768个隐藏单元+12个自注意力头
- Large版本:24层Transformer编码器块+1024个隐藏单元+16个自注意力头
- 前者有1.1亿个参数,后者有3.4亿个参数
- 本节定义了一个Small版本用于演示:2层+128个隐藏单元+2个自注意力头
基于PyTorch的BERT预训练:
注:为方便运行,本小节将原书8、9、10节是所有代码进行了汇总
- 数据读取和预处理部分
import os
import random
import torch
from torch import nn
from d2l import torch as d2l
#@save
d2l.DATA_HUB['wikitext-2'] = (
'https://s3.amazonaws.com/research.metamind.io/wikitext/'
'wikitext-2-v1.zip', '3c914d17d80b1459be871a5039ac23e752a53cbe')
#@save
def _read_wiki(data_dir):
"""读取数据 wikitext-2并进行简单清洗分割"""
file_name = os.path.join(data_dir, 'wiki.train.tokens')
with open(file_name, 'r') as f:
lines = f.readlines()
# 大写字母转换为小写字母
paragraphs = [line.strip().lower().split(' . ')
for line in lines if len(line.split(' . ')) >= 2]
random.shuffle(paragraphs) # 使用句号作为分隔符来拆分句子
return paragraphs
#@save
def _get_next_sentence(sentence, next_sentence, paragraphs):
"""50%的概率随机替换到正确的下一句-形成正负例"""
if random.random() < 0.5:
is_next = True #
else:
# paragraphs是三重列表的嵌套
next_sentence = random.choice(random.choice(paragraphs))
is_next = False
return sentence, next_sentence, is_next
#@save
def get_tokens_and_segments(tokens_a, tokens_b=None):
"""获取输入序列的词元及其片段索引"""
tokens = ['<cls>'] + tokens_a + ['<sep>']
# 0和1分别标记片段A和B
segments = [0] * (len(tokens_a) + 2)
if tokens_b is not None:
tokens += tokens_b + ['<sep>']
segments += [1] * (len(tokens_b) + 1)
return tokens, segments
#@save
def _get_nsp_data_from_paragraph(paragraph, paragraphs, vocab, max_len):
"""生成用于下一句预测任务的训练样本"""
nsp_data_from_paragraph = []
for i in range(len(paragraph) - 1):
tokens_a, tokens_b, is_next = _get_next_sentence(
paragraph[i], paragraph[i + 1], paragraphs)
# 考虑1个'<cls>'词元和2个'<sep>'词元
if len(tokens_a) + len(tokens_b) + 3 > max_len:
continue
tokens, segments = d2l.get_tokens_and_segments(tokens_a, tokens_b)
nsp_data_from_paragraph.append((tokens, segments, is_next))
return nsp_data_from_paragraph
#@save
def _replace_mlm_tokens(tokens, candidate_pred_positions, num_mlm_preds,
vocab):
# 为遮蔽语言模型的输入创建新的词元副本,其中输入可能包含替换的“<mask>”或随机词元
mlm_input_tokens = [token for token in tokens]
pred_positions_and_labels = []
# 打乱后用于在遮蔽语言模型任务中获取15%的随机词元进行预测
random.shuffle(candidate_pred_positions)
for mlm_pred_position in candidate_pred_positions:
if len(pred_positions_and_labels) >= num_mlm_preds:
break
masked_token = None
# 80%的时间:将词替换为“<mask>”词元
if random.random() < 0.8:
masked_token = '<mask>'
else:
# 10%的时间:保持词不变
if random.random() < 0.5:
masked_token = tokens[mlm_pred_position]
# 10%的时间:用随机词替换该词
else:
masked_token = random.choice(vocab.idx_to_token)
mlm_input_tokens[mlm_pred_position] = masked_token
pred_positions_and_labels.append(
(mlm_pred_position, tokens[mlm_pred_position]))
return mlm_input_tokens, pred_positions_and_labels
#@save
def _get_mlm_data_from_tokens(tokens, vocab):
"""生成用于遮蔽语言模型任务的训练样本"""
candidate_pred_positions = []
# tokens是一个字符串列表
for i, token in enumerate(tokens):
# 在遮蔽语言模型任务中不会预测特殊词元
if token in ['<cls>', '<sep>']:
continue
candidate_pred_positions.append(i)
# 遮蔽语言模型任务中预测15%的随机词元
num_mlm_preds = max(1, round(len(tokens) * 0.15))
mlm_input_tokens, pred_positions_and_labels = _replace_mlm_tokens(
tokens, candidate_pred_positions, num_mlm_preds, vocab)
pred_positions_and_labels = sorted(pred_positions_and_labels,
key=lambda x: x[0])
pred_positions = [v[0] for v in pred_positions_and_labels]
mlm_pred_labels = [v[1] for v in pred_positions_and_labels]
return vocab[mlm_input_tokens], pred_positions, vocab[mlm_pred_labels]
#@save
def _pad_bert_inputs(examples, max_len, vocab):
"""用于填充输入的辅助函数,examples来自两个预训练任务的训练样本生成方法"""
max_num_mlm_preds = round(max_len * 0.15)
all_token_ids, all_segments, valid_lens, = [], [], []
all_pred_positions, all_mlm_weights, all_mlm_labels = [], [], []
nsp_labels = []
for (token_ids, pred_positions, mlm_pred_label_ids, segments,
is_next) in examples:
all_token_ids.append(torch.tensor(token_ids + [vocab['<pad>']] * (
max_len - len(token_ids)), dtype=torch.long))
all_segments.append(torch.tensor(segments + [0] * (
max_len - len(segments)), dtype=torch.long))
# valid_lens不包括'<pad>'的计数
valid_lens.append(torch.tensor(len(token_ids), dtype=torch.float32))
all_pred_positions.append(torch.tensor(pred_positions + [0] * (
max_num_mlm_preds - len(pred_positions)), dtype=torch.long))
# 填充词元的预测将通过乘以0权重在损失中过滤掉
all_mlm_weights.append(
torch.tensor([1.0] * len(mlm_pred_label_ids) + [0.0] * (
max_num_mlm_preds - len(pred_positions)),
dtype=torch.float32))
all_mlm_labels.append(torch.tensor(mlm_pred_label_ids + [0] * (
max_num_mlm_preds - len(mlm_pred_label_ids)), dtype=torch.long))
nsp_labels.append(torch.tensor(is_next, dtype=torch.long))
return (all_token_ids, all_segments, valid_lens, all_pred_positions,
all_mlm_weights, all_mlm_labels, nsp_labels)
#@save
class _WikiTextDataset(torch.utils.data.Dataset):
"""定制一个用于训练的`Dataset`类"""
def __init__(self, paragraphs, max_len):
# 输入paragraphs[i]是代表段落的句子字符串列表;
# 而输出paragraphs[i]是代表段落的句子列表,其中每个句子都是词元列表
paragraphs = [d2l.tokenize(
paragraph, token='word') for paragraph in paragraphs]
sentences = [sentence for paragraph in paragraphs
for sentence in paragraph]
self.vocab = d2l.Vocab(sentences, min_freq=5, reserved_tokens=[
'<pad>', '<mask>', '<cls>', '<sep>'])
# 获取下一句子预测任务的数据
examples = []
for paragraph in paragraphs:
examples.extend(_get_nsp_data_from_paragraph(
paragraph, paragraphs, self.vocab, max_len))
# 获取遮蔽语言模型任务的数据
examples = [(_get_mlm_data_from_tokens(tokens, self.vocab)
+ (segments, is_next))
for tokens, segments, is_next in examples]
# 填充输入
(self.all_token_ids, self.all_segments, self.valid_lens,
self.all_pred_positions, self.all_mlm_weights,
self.all_mlm_labels, self.nsp_labels) = _pad_bert_inputs(
examples, max_len, self.vocab)
def __getitem__(self, idx):
return (self.all_token_ids[idx], self.all_segments[idx],
self.valid_lens[idx], self.all_pred_positions[idx],
self.all_mlm_weights[idx], self.all_mlm_labels[idx],
self.nsp_labels[idx])
def __len__(self):
return len(self.all_token_ids)
#@save
def load_data_wiki(batch_size, max_len):
"""封装以上所有方法,构成加载WikiText-2数据集的函数"""
num_workers = d2l.get_dataloader_workers()
data_dir = d2l.download_extract('wikitext-2', 'wikitext-2')
paragraphs = _read_wiki(data_dir)
train_set = _WikiTextDataset(paragraphs, max_len)
train_iter = torch.utils.data.DataLoader(train_set, batch_size,
shuffle=True, num_workers=num_workers)
return train_iter, train_set.vocab
batch_size, max_len = 512, 64
train_iter, vocab = d2l.load_data_wiki(batch_size, max_len)
- 模型结构设计与训练
#@save
class BERTEncoder(nn.Module):
"""BERT编码器"""
def __init__(self, vocab_size, num_hiddens, norm_shape, ffn_num_input,
ffn_num_hiddens, num_heads, num_layers, dropout,
max_len=1000, key_size=768, query_size=768, value_size=768,
**kwargs):
super(BERTEncoder, self).__init__(**kwargs)
self.token_embedding = nn.Embedding(vocab_size, num_hiddens)
self.segment_embedding = nn.Embedding(2, num_hiddens)
self.blks = nn.Sequential()
for i in range(num_layers):
self.blks.add_module(f"{i}", d2l.EncoderBlock(
key_size, query_size, value_size, num_hiddens, norm_shape,
ffn_num_input, ffn_num_hiddens, num_heads, dropout, True))
# 在BERT中,位置嵌入是可学习的,因此我们创建一个足够长的位置嵌入参数
self.pos_embedding = nn.Parameter(torch.randn(1, max_len,
num_hiddens))
def forward(self, tokens, segments, valid_lens):
# 在以下代码段中,X的形状保持不变:(批量大小,最大序列长度,num_hiddens)
X = self.token_embedding(tokens) + self.segment_embedding(segments)
X = X + self.pos_embedding.data[:, :X.shape[1], :]
for blk in self.blks:
X = blk(X, valid_lens)
return X
#@save
class MaskLM(nn.Module):
"""BERT的掩蔽语言模型任务"""
def __init__(self, vocab_size, num_hiddens, num_inputs=768, **kwargs):
super(MaskLM, self).__init__(**kwargs)
self.mlp = nn.Sequential(nn.Linear(num_inputs, num_hiddens),
nn.ReLU(),
nn.LayerNorm(num_hiddens),
nn.Linear(num_hiddens, vocab_size))
def forward(self, X, pred_positions):
num_pred_positions = pred_positions.shape[1]
pred_positions = pred_positions.reshape(-1)
batch_size = X.shape[0]
batch_idx = torch.arange(0, batch_size)
# 假设batch_size=2,num_pred_positions=3
# 那么batch_idx是np.array([0,0,0,1,1,1])
batch_idx = torch.repeat_interleave(batch_idx, num_pred_positions)
masked_X = X[batch_idx, pred_positions]
masked_X = masked_X.reshape((batch_size, num_pred_positions, -1))
mlm_Y_hat = self.mlp(masked_X)
return mlm_Y_hat
#@save
class NextSentencePred(nn.Module):
"""BERT的下一句预测任务"""
def __init__(self, num_inputs, **kwargs):
super(NextSentencePred, self).__init__(**kwargs)
self.output = nn.Linear(num_inputs, 2)
def forward(self, X):
# X的形状:(batchsize,num_hiddens)
return self.output(X)
#@save
class BERTModel(nn.Module):
"""BERT模型:整合以上的三个类"""
def __init__(self, vocab_size, num_hiddens, norm_shape, ffn_num_input,
ffn_num_hiddens, num_heads, num_layers, dropout,
max_len=1000, key_size=768, query_size=768, value_size=768,
hid_in_features=768, mlm_in_features=768,
nsp_in_features=768):
super(BERTModel, self).__init__()
self.encoder = BERTEncoder(vocab_size, num_hiddens, norm_shape,
ffn_num_input, ffn_num_hiddens, num_heads, num_layers,
dropout, max_len=max_len, key_size=key_size,
query_size=query_size, value_size=value_size)
self.hidden = nn.Sequential(nn.Linear(hid_in_features, num_hiddens),
nn.Tanh())
self.mlm = MaskLM(vocab_size, num_hiddens, mlm_in_features)
self.nsp = NextSentencePred(nsp_in_features)
def forward(self, tokens, segments, valid_lens=None,
pred_positions=None):
encoded_X = self.encoder(tokens, segments, valid_lens)
if pred_positions is not None:
mlm_Y_hat = self.mlm(encoded_X, pred_positions)
else:
mlm_Y_hat = None
# 用于下一句预测的多层感知机分类器的隐藏层,0是“<cls>”标记的索引
nsp_Y_hat = self.nsp(self.hidden(encoded_X[:, 0, :]))
return encoded_X, mlm_Y_hat, nsp_Y_hat
net = d2l.BERTModel(len(vocab), num_hiddens=128, norm_shape=[128],
ffn_num_input=128, ffn_num_hiddens=256, num_heads=2,
num_layers=2, dropout=0.2, key_size=128, query_size=128,
value_size=128, hid_in_features=128, mlm_in_features=128,
nsp_in_features=128)
devices = d2l.try_all_gpus()
loss = nn.CrossEntropyLoss()
#@save
def _get_batch_loss_bert(net, loss, vocab_size, tokens_X,
segments_X, valid_lens_x,
pred_positions_X, mlm_weights_X,
mlm_Y, nsp_y):
"""辅助函数,给定训练样本,计算两个任务的对应损失与最终损失"""
_, mlm_Y_hat, nsp_Y_hat = net(tokens_X, segments_X,
valid_lens_x.reshape(-1),
pred_positions_X)# 前向传播
# 计算遮蔽语言模型损失
mlm_l = loss(mlm_Y_hat.reshape(-1, vocab_size), mlm_Y.reshape(-1)) *\
mlm_weights_X.reshape(-1, 1)
mlm_l = mlm_l.sum() / (mlm_weights_X.sum() + 1e-8)
# 计算下一句子预测任务的损失
nsp_l = loss(nsp_Y_hat, nsp_y)
l = mlm_l + nsp_l
return mlm_l, nsp_l, l
def train_bert(train_iter, net, loss, vocab_size, devices, num_steps):
net = nn.DataParallel(net, device_ids=devices).to(devices[0])
trainer = torch.optim.Adam(net.parameters(), lr=0.01)
step, timer = 0, d2l.Timer()
animator = d2l.Animator(xlabel='step', ylabel='loss',
xlim=[1, num_steps], legend=['mlm', 'nsp'])
# 遮蔽语言模型损失的和,下一句预测任务损失的和,句子对的数量,计数
metric = d2l.Accumulator(4)
num_steps_reached = False
while step < num_steps and not num_steps_reached:
for tokens_X, segments_X, valid_lens_x, pred_positions_X,\
mlm_weights_X, mlm_Y, nsp_y in train_iter:
tokens_X = tokens_X.to(devices[0])
segments_X = segments_X.to(devices[0])
valid_lens_x = valid_lens_x.to(devices[0])
pred_positions_X = pred_positions_X.to(devices[0])
mlm_weights_X = mlm_weights_X.to(devices[0])
mlm_Y, nsp_y = mlm_Y.to(devices[0]), nsp_y.to(devices[0])
trainer.zero_grad()
timer.start()
mlm_l, nsp_l, l = _get_batch_loss_bert(
net, loss, vocab_size, tokens_X, segments_X, valid_lens_x,
pred_positions_X, mlm_weights_X, mlm_Y, nsp_y)
l.backward()
trainer.step()
metric.add(mlm_l, nsp_l, tokens_X.shape[0], 1)
timer.stop()
animator.add(step + 1,
(metric[0] / metric[3], metric[1] / metric[3]))
step += 1
if step == num_steps:
num_steps_reached = True
break
print(f'MLM loss {metric[0] / metric[3]:.3f}, '
f'NSP loss {metric[1] / metric[3]:.3f}')
print(f'{metric[2] / timer.sum():.1f} sentence pairs/sec on '
f'{str(devices)}')
train_bert(train_iter, net, loss, len(vocab), devices, 50)
# MLM loss 5.680, NSP loss 0.770
# 4531.9 sentence pairs/sec on [device(type='cuda', index=0), device(type='cuda', index=1)]
def get_bert_encoding(net, tokens_a, tokens_b=None):
"""辅助函数:获取BERT的输入表示"""
tokens, segments = d2l.get_tokens_and_segments(tokens_a, tokens_b)
token_ids = torch.tensor(vocab[tokens], device=devices[0]).unsqueeze(0)
segments = torch.tensor(segments, device=devices[0]).unsqueeze(0)
valid_len = torch.tensor(len(tokens), device=devices[0]).unsqueeze(0)
encoded_X, _, _ = net(token_ids, segments, valid_len)
return encoded_X
tokens_a = ['a', 'crane', 'is', 'flying']
encoded_text = get_bert_encoding(net, tokens_a)
encoded_text_cls = encoded_text[:, 0, :] # 输入语句的BERT表示
encoded_text_crane = encoded_text[: 2, :] # 第二个单词的BERT表示
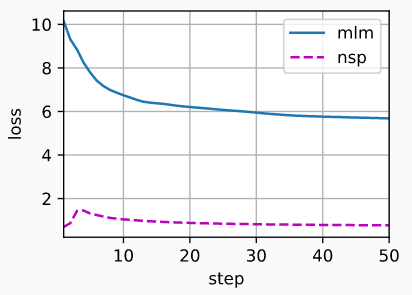
mlm表示遮盖语言模型对应的损失,nsp表示下一句预测任务对应的损失