1 向量数据库概述
“向量数据”:向量数据是由多个数值组成的序列,可以表示数据的大小和方向
向量数据库是一种专门用于存储和查询向量数据的数据库系统,
- 与传统数据库相比,向量数据库使用向量化计算,能够高速地处理大规模的复杂数据
- 可以处理高维数据,例如图像、音频和视频等,解决传统关系型数据库中的痛点
- 支持复杂的查询操作,也可以轻松地扩展到多个节点,以处理更大规模的数据
局限性:技术成熟度较低,学习成本高,产品和落地应用偏少(存在场景局限性)
常见向量数据操作
- 向量检索:根据给定的向量,找出数据库中与之最相似的向量,例如在图像向量数据库中,用户输入一张图片进行搜索时, 根据图片向量的近似检索,找到与输入图片最相似的图片
- 向量聚类:根据给定的相似度度量,将数据库中的向量分类,例如图片风格划分
- 向量降维:将数据库中的高维向量转换成低维向量,以便于可视化或压缩存储
- 向量计算:根据给定的算法或模型对向量进行计算或分析,例如图片分类或标注
核心技术概述:
- Embedding 技术,图像、声音、文本都可以被表达为一个高维的向量
- 向量索引技术,使用近似搜索算法来加速向量的检索(比如 k-d tree,PQ,HNSW等)
- 分布式系统架构,利用多节点的计算资源来实现共同的目标(向量数据规模一般较大)
- 硬件加速技术,利用专用硬件(比如 GPU,FPGA,AI芯片等)来加速向量运算
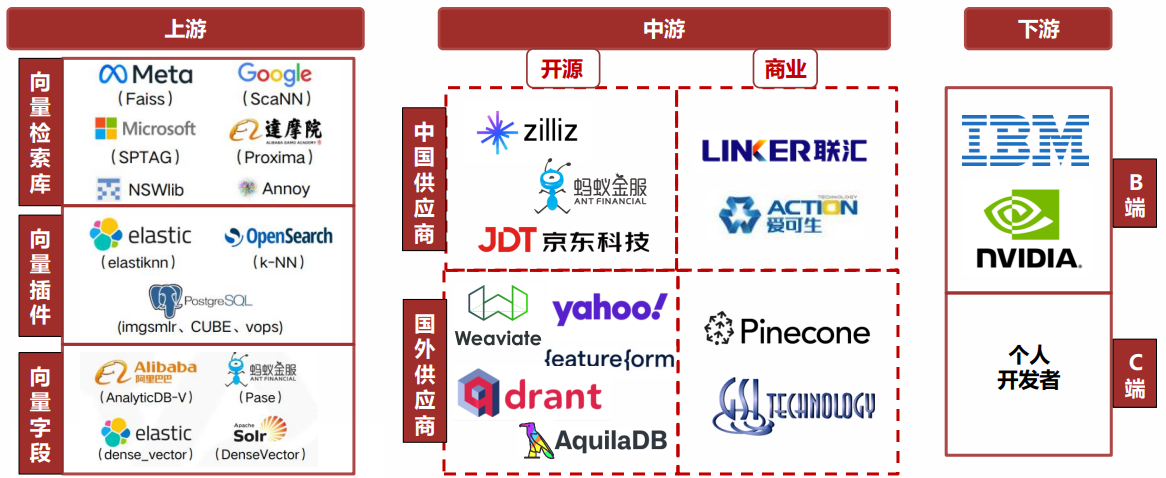
2 主流向量数据库
产业链分布:
向量数据库趋势图 - 图源
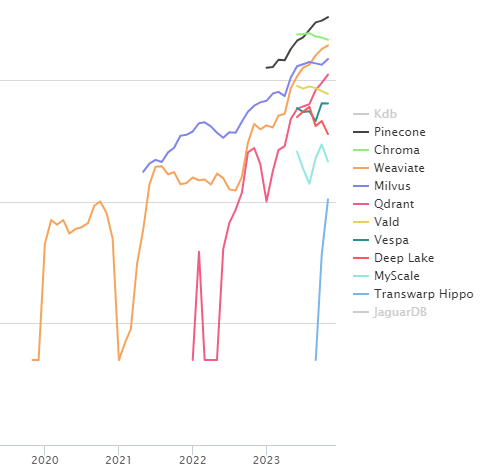
- 其中 Kdb 是一种高性能的时间序列数据库(不在本文探讨范围内,因此已忽略)
2.1 Pinecone
Pinecone 是一款使用直观、速度快且可轻松扩展的向量数据库(不开源)
- 完全托管(Fully-managed),无需维护基础设施、监控服务或排除算法故障
- 搜索快速而准确(Fast, relevant results):以毫秒为单位加速数据传输。利用元数据过滤器和稀疏密集索引支持实现一流的相关性,确保在不同的搜索任务中快速、准确地获得结果
- 成本透明可预测(Predictable costs):资源定价透明,支持无缝扩展;轻松查看和监控使用情况
收费情况:
- 免费版:申请即通过,只支持一个项目和一个索引;如果数据库7天没交互,就会被清空
- 标准版起步价:0.096 美元/小时;企业版起步价:0.144 美元/小时
Pinecone 先后上架 Google 云和 AWS,逐步打开市场,在一级市场获 得1.38亿美元投资。
2.2 Chroma
Chroma 是一款开源免费的嵌入式数据库,能用于 LLM 应用的快速构建
- 核心 API 只有 4 个函数:创建客户端/创建主题/填充文本/开始查询
- 集成到了<code>LangChain</code> 和 <code>LlamaIndex</code>中,支持灵活的拓展
项目地址 9.6k ⭐
Chroma 作为轻量级的向量数据库,功能较为基础,但胜在简单易用
2.3 Weaviate
Weaviate 是一个开源向量数据库,可存储对象和矢量,允许将矢量搜索与结构化过滤与云原生数据库的容错性和可扩展性相结合,所有这些都可以通过 GraphQL、REST 和各种语言客户端进行访问
- 丰富的向量搜索功能:相似性、混合搜索、生成、对象过滤
- 轻松开发:只需加载并搜索;自动向量化;可拓展的搜索插件
- 高性能:支持高可用、并行处理、可拓展到数亿个对象
- 灵活部署:支持云部署;开源;可嵌入(Embeddable)
项目地址 8.2k ⭐
起步很早的一款向量数据库。基础好,还有先发优势
2.4 Zilliz Milvus
Milvus 是一个开源矢量数据库,旨在为嵌入相似性搜索和人工智能应用程序提供支持。 Milvus 使非结构化数据搜索更容易访问,并且无论部署环境如何,都可以提供一致的用户体验。
- 在万亿向量数据集上可以达到毫秒级的平均搜索延迟
- 简化的非结构化数据管理(API 丰富,跨平台,可嵌入任意应用)
- 可靠、始终在线的矢量数据库(内置备份、故障转移/故障恢复功能)
- 根据负载实现高度可扩展和弹性,使资源调度更加高效
- 支持多种数据类型和字段属性的混合搜索;机构认可度高,社区活跃
- 集合流处理和批处理进行数据存储,兼顾效率和时效性
项目地址 24.1k ⭐
Zilliz 目前已与 Nvidia、IBM、 Mircosof t等公司展开合作,在一级市场获得1.13亿美元投资;
2.5 Qdrant
Qdrant 是一个向量相似性搜索引擎和向量数据库
- 基于 Rust 编写,即使在高负载下也能快速可靠
- 快速转变 LLMs 为成熟的应用程序,用于匹配、搜索、推荐等
- 可以作为完全托管的 Qdrant Cloud 提供,包括免费版本
项目地址 14.5k⭐
2.6 总结与对比
| 数据库名称 | 开发商 | 特点 | 缺点 | 代码 | 类型 |
|---|---|---|---|---|---|
| Pinecone | Pinecone Systems | 易于上手,完全托管,专注于搜索和推荐;文档完善 | 成本较高,功能不如开源项目灵活 | 闭源 | 托管 |
| Chroma | Facebook AI | 启动快速,简单易用,轻量级;与应用程序紧密集成 | 功能单薄,暂不支持GPU加速 | 开源 | 没有托管版本 |
| Weaviate | Weaviate | 擅长图查询,支持模型训练 | 更适合知识图谱应用而非通用向量 | 开源 | 自托管 |
| Milvus | Zilliz | 可拓展性强,支持多种相似性搜索;开源社区活跃 | 高度的可拓展性导致系统复杂且资源密集,开发体验较低 | 开源 | 自托管 |
| Qdrant | Qdrant | 基于rust开发,资源利用率高;后起之秀;文档完善 | 起步较晚,追赶中 | 开源 | 自托管 |
3 未来趋势
市场规模预估
- 据 Statista 数据,2021 年全球数据库市场规模为 800 亿美元,同比增长约20.3%。 假设增速保持20%,预计到2025年,全球数据库市场规模将达到1658.9 亿美元。
- 据中国信通院测算,2020年中国数据库市场规模约 241亿元;预计到2025年,中国数据库市场规模将达688亿元,复合增长率为23.4%。
- 随着AI应用场景加速落地,西南证券团队预计2025年向量数据库渗透率约为30%,则全球向量数据库市场规模约为99.5亿美元,中国向量数据库市场规模约为82.56亿元
过去经验:数据库世界中,最成功的商业模式是预先开源代码的久经考验的方法(以便围绕该技术建立一个充满热情的社区),然后通过托管服务或云产品将该工具商业化
关键挑战:矢量数据库供应商(如 Milvus 、 Weaviate )都在试图解决的一个关键问题,即如何以尽可能低的延迟实现万亿规模的矢量搜索。这是一项极其困难的任务
进阶阅读:ANN 近似最近邻搜索
其他资源:bilibili-向量数据库技术鉴赏