中文标题:FAST:基于财经新闻和推特的时间感知股票交易网络
英文标题:FAST: Financial News and Tweet Based Time Aware Network for Stock Trading
发布平台:EACL
发布日期:2021-01-01
引用量(非实时):25
DOI:10.18653/v1/2021.eacl-main.185
作者:Ramit Sawhney, Arnav Wadhwa, Shivam Agarwal, Rajiv Ratn Shah
文章类型:conferencePaper
品读时间:2023-12-09 19:59
1 文章萃取
1.1 核心观点
财经新闻和社交媒体中存在的嘈杂数据和不规则时间间隔;为了应对这类限制,本文提出了一种新颖的分层学习排名方法 FAST。FAST 模型会先学习财经新闻和推文的时间感知表示,并使用分层时间注意力捕获相关的市场信号;最后,模型通过同时优化预测能力和股票的最佳排名来实现利润最大化
在两个基准的交易模拟(涵盖两个主要股指和四个全球市场,文本包括英文推文和中文财经新闻)中,FAST 模型在累积利润和风险调整回报方面比最先进的方法高出 8% 以上
1.2 综合评价
- 先进行日内注意力,再进行日间注意力;逻辑合理且更贴近现实场景
- 在日内编码器中引入 t-LSTM 机制,改善文本中细粒度时间的不规则性
- 模型实验充分,包含了模型对比、消融实验、解释性分析和灵敏度分析
1.3 主观评分:⭐⭐⭐⭐⭐
2 精读笔记
2.1 FAST 模型细节
FAST 模型结构:
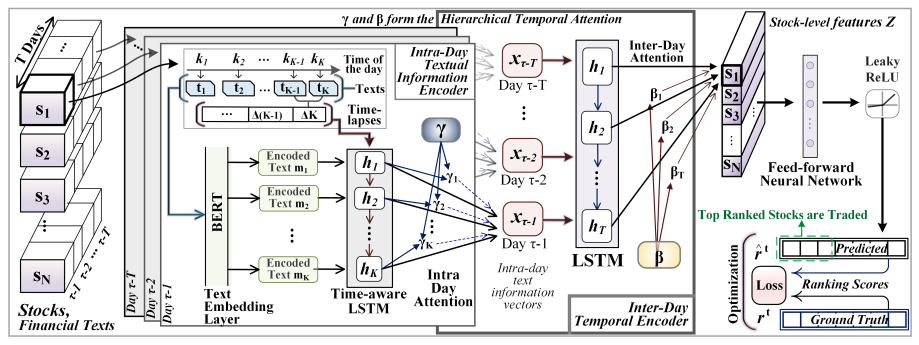
- FAST 通过嵌入层(BERT)对文本进行编码,并使用具备时间感知的 t-LSTM (根据时间间隔对短期记忆进行衰减)实现同一天内不同时间间隔的$K$个文本流的表示:
$$\begin{aligned}C_{k-1}^S&=tanh(W_dC_{k-1}+b_d)\quad\lfloor\text{短期记忆 }\rceil \\\tilde{C}_{k-1}^S&=C_{k-1}^S*g(\Delta k)\quad \lfloor \text{短期记忆衰减}\rceil \\C_{k-1}^{LT}&=C_{k-1}-C_{k-1}^S\quad \lfloor \text{长期记忆} \rceil \\C_{k-1}^*&=C_{k-1}^{LT}+\tilde{C}_{k-1}^S\quad \lfloor \text{调整后的记忆} \rceil \end{aligned}$$
其中$C_{k-1}$表示历史的单元记忆,$\Delta k$表示两次文本流之间的时间间隔,根据经验选择 $g(\Delta k) = \frac{1}{\Delta k}$;直观上,两条新闻或推文之间的间隔时间越长,它们对彼此的影响就越小
- FAST 使用日内注意力机制(Intra Day Attention)挖掘可能对价格影响更大的文本,其中$\gamma$表示此阶段学习到的注意力权重;最终文本流加权汇总得到每日的文本表示
- 每日文本表示再通过 LSTM 和日间注意力机制(Inter-Day Attention)继续从时间维度感知依赖关系,得到每日文本表示的注意力权重$\beta$;最后加权聚合为一个整体信息表征,这一模块也被称为日间时序编码器(Inter-Day Temporal Encoder)
- 所有股票的整体信息表征$Z$,通过前馈神经网络和ReLU激活,实现最终回报率的预测;而最终的损失函数还会添加约束$TopN$股票排序顺序的损失
$$L=|\hat{r}^\tau-r^\tau|^2+\phi\sum_{i=1}^N\sum_{j=1}^N\max\left(0,-\left(\hat{r}_i^\tau-\hat{r}_j^\tau\right)\left(r_i^\tau-r_j^\tau\right)\right)$$
其中$\hat{r}^\tau$和$r^\tau$分别表示第$\tau$天已排序股票得分的预测值和真实值
2.2 实验结果与分析
实验数据说明:
- 美国:标准普尔 500 指数中 88 只高交易量股票,对应的文本信息包含 2014 年 1 月至 2015 年 12 月期间来自社交媒体平台 Twitter 的 109915 条英文推文
- 中国和香港:沪深或香港中 85 只交易量最高的中国 A 股股票,对应的文本信息包含2015 年 1 月至 12 月的 90361 条中文财经新闻(Wind 汇总)
- 英文文本处理:NLTK 清洗文本(URL、@ 和主题标签#);采用 Bert 的预训练嵌入
- 中文文本处理:不需要清洗;采用 Chinese-Bert 的预训练嵌入
与其他主流模型对比(FAST 显著最优):
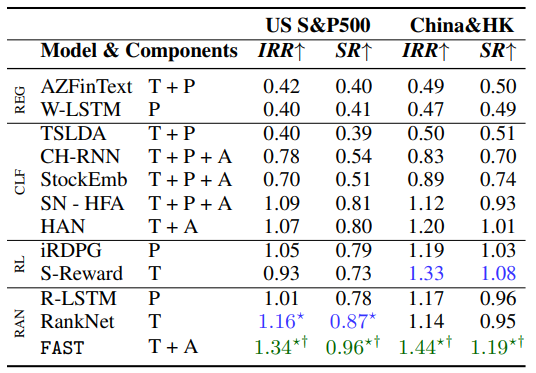
- 在组件(components)中,T = 文本,P = 价格,A = 跨模式的注意力
- IRR 表示累积投资回报率(内部收益率);SR 表示考虑到风险收益的夏普比率
部分模型简述:
- RankNet:基于情感和趋势分数来优化概率排名函数的 DNN(Song 等人,2017)
- R-LSTM:利用 5、10、20、30 天的均值和收盘价训练 LSTM(Feng 等人,2019)
- HAN:双向 GRU 编码器 +(新闻/时间)分层注意力网络(Hu et al., 2017)
消融实验:
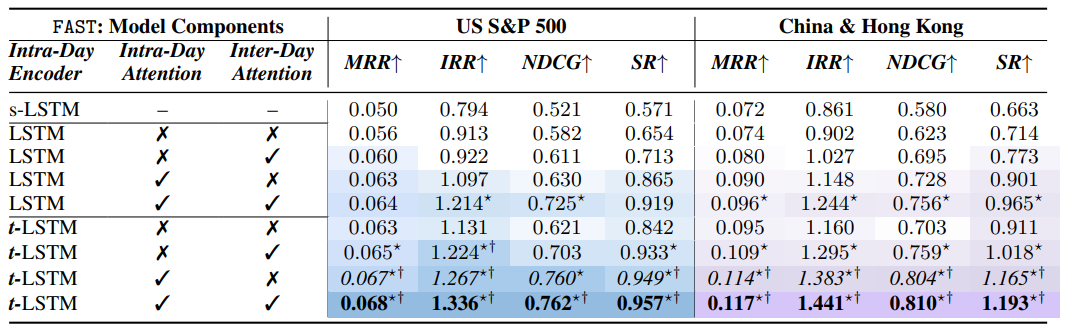
- 颜色越深表示模型实际效果越好,粗体表示最佳结果,斜体表示次佳结果
- s-LSTM 表示单个 LSTM 层;
*和↑表示存在对应的改进存在显著性优势 - 日内注意力比日间注意力更重要,整体提升最大的技巧是 t-LSTM 操作
FAST 模型的注意力可视化和股票交易表现如下:
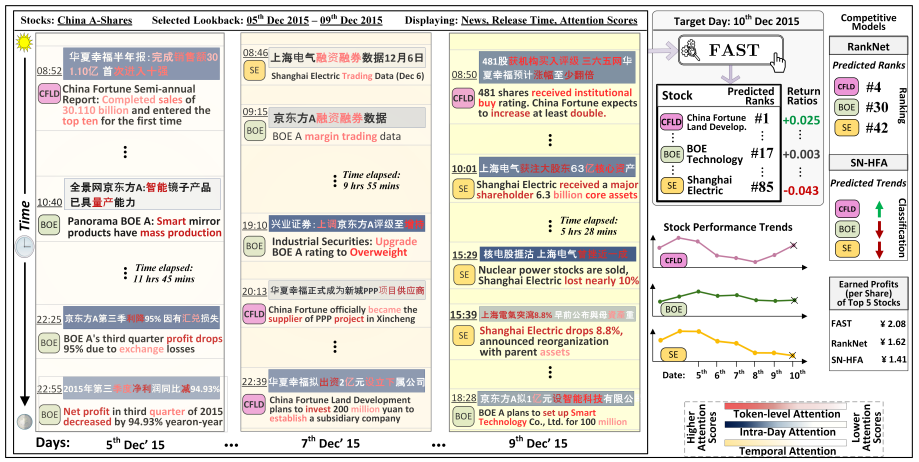
- 左侧三图为不同类型注意力的可视化;右侧为实际股票交易表现
其他细节:
- 使用网格法进行超参搜索,针对最终模型进行超参取值的灵敏度分析
- 伴随 t-LSTM 模块中时间颗粒度 $\Delta k$ 的增加,模型性能呈现下降趋势
相关资源
- 论文在线地址
- 本地文件地址:Sawhney et al_2021_FAST.pdf
- 本地Zotero地址:Sawhney et al_2021_FAST.pdf