1 基本介绍
PyCaret是一个开源的、低代码的Python机器学习库,可以实现机器学习工作流程的自动化。作为一个端到端的机器学习和模型管理工具,PyCaret可以成倍地缩短实验周期,实现更有效率的科研探索。
- 以包装器的形式大幅度缩减代码量(用几行代码实现数百行代码的功能)
- 主要围绕 scikit-learn、XGBoost、LightGBM、CatBoost、Optuna、Hyperopt、Ray等框架
- 支持初级和中等难度的数据分析与建模工作,适合作为前期探索工具
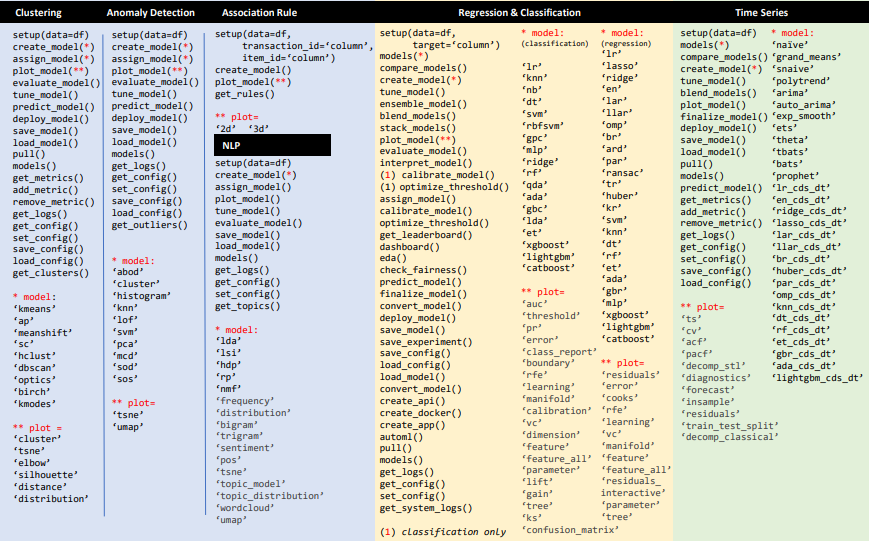
- 主要支持以下几种算法场景:聚类,异常检测,关联规则,分类&回归,时序分析
2 简单上手
以最常见的分类问题为例(摘自官方示例):
- 加载数据
from pycaret.datasets import get_data
data = get_data('diabetes')
- 数据准备
from pycaret.classification import *
s = setup(data, target = 'Class variable') # target:指定预测目标
# 程序会根据数据特性自动推断数据类型
# 对于不确定的数据类型,会提示进行手动录入
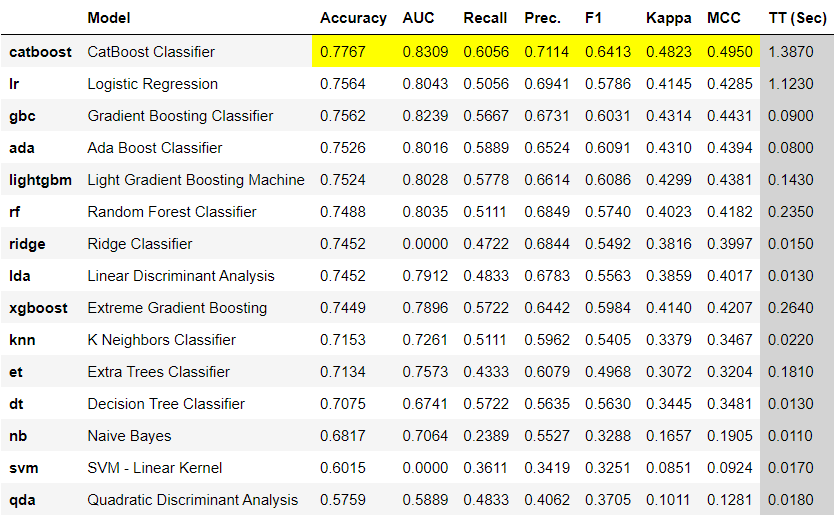
- 模型对比
best = compare_models() # 对比内置的多项模型并进行评估
print(best) # 自动返回最优的预测模型,本例中的最优模型是CatBoost
#
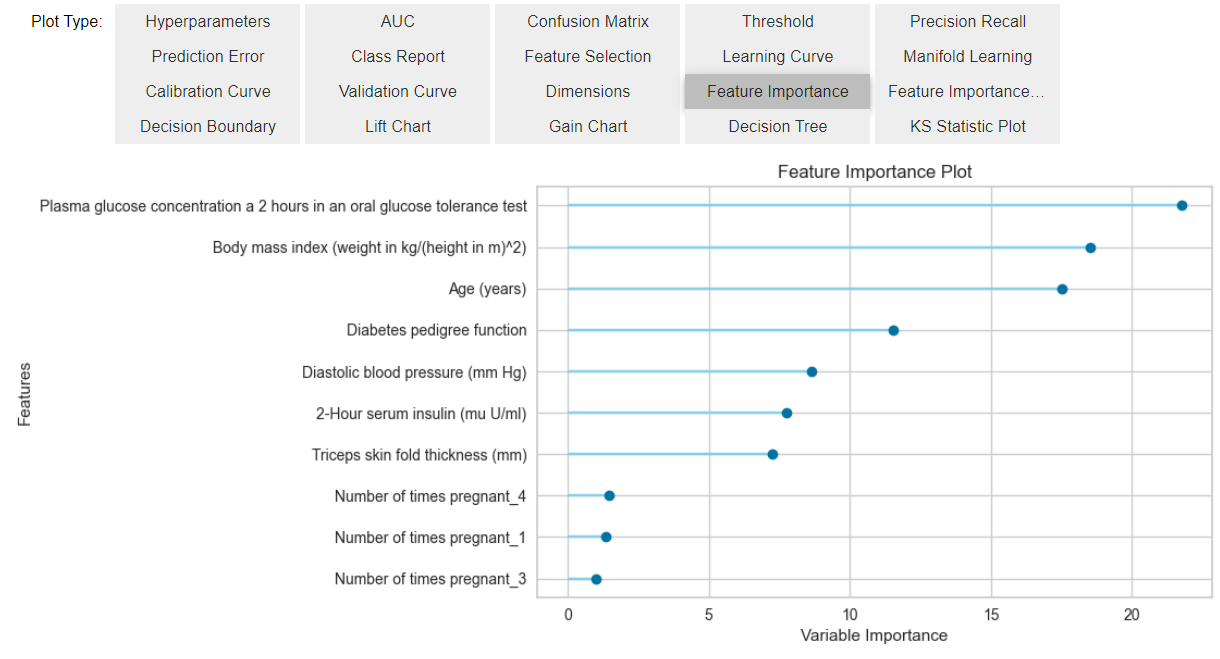
- 模型分析
evaluate_model(best) # 分析模型并进行可视化:支持多种结果的展示
# 也可以指定所需绘制的图像类型
plot_model(best, plot = 'auc') # 汇总模型的AUROC,支持多分类的情况
plot_model(best, plot = 'confusion_matrix') # 绘制模型的混淆矩阵
- 模型调用与存储
predict_model(best) # 查看模型基本分析指标
predictions = predict_model(best, data=data)
predictions.head() # 查看预测结果
save_model(best, 'my_best_pipeline') # 保存模型
loaded_model = load_model('my_best_pipeline') # 加载模型
其他说明
- 除了分类问题,PyCaret目前还支持聚类,异常检测,关联规则,分类&回归,时序分析
- 不同任务类型对应的模型流程与代码也是类似的,只不过建模方法、分析指标和可视化存在些许差异
参考
官方Cheat sheet(聚类,异常检测,关联规则,分类&回归,时序分析):