中文标题:HTML:基于层次Transformer的多任务学习用于波动率预测
英文标题:HTML: Hierarchical Transformer-based Multi-task Learning for Volatility Prediction
发布平台:WWW
发布日期:2020-04-20
引用量(非实时):89
DOI:10.1145/3366423.3380128
作者:Linyi Yang, Tin Lok James Ng, Barry Smyth, Riuhai Dong
关键字: #HTML #Transformer #波动率
文章类型:conferencePaper
品读时间:2024-01-20 16:22
1 文章萃取
1.1 核心观点
- 本文提出了一种新颖的分层、变压器、多任务架构,旨在利用季度收益电话会议的文本和音频数据来预测未来的短期和长期价格波动。最终模型的预测精度与当前最先进的技术相比,提高了 17% - 49%
1.2 综合评价
- 使用季度收益电话会议的文本和音频数据作为模型输入,具备一定新颖性
- 算法细节和模型结构较为经典,数据的量级和获取难度会是模型落地瓶颈
- 方法上缺少创新性,评价指标单一;不过部分实验分析内容还挺有意思的
1.3 主观评分:⭐⭐⭐⭐
2 精读笔记
2.1 算法细节
多任务训练框架:
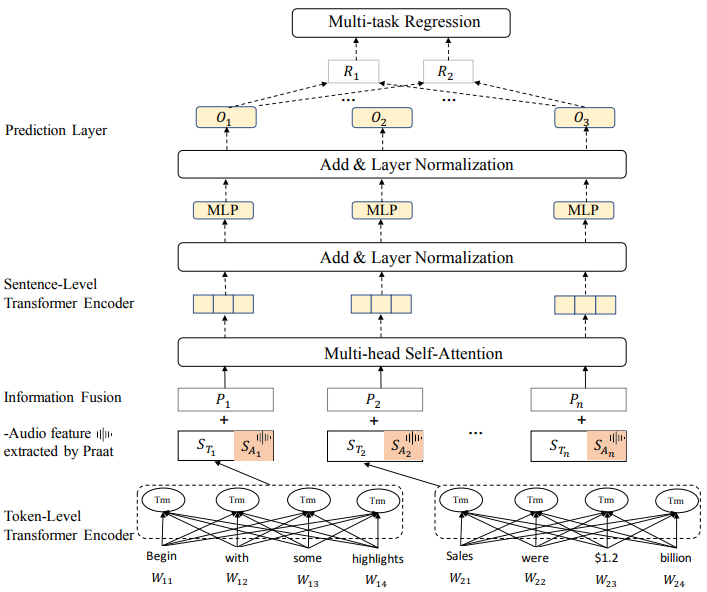
- 使用预训练的 WWM-BERT 模型(Token-Level)将文本数据编码为嵌入表示向量
- 使用 Praat 从句子级音频数据中提取 27 种不同的音频特征(音调、强度、抖动和谐波噪声比等)
- 信息融合层(Information Fusion):融合文本和音频特征,作为句子级 Transformer 编码器的输入
- 句子级 Transformer 编码器输出高级特征信息,并作为多任务学习器的输入表示
- 模型训练的主要任务:未来 n 日的平均波动率 $y_i$;次要任务:未来第 n 日的单日波动率 $y_j$
最终损失函数(两个回归预测任务的组合): $$ {\mathcal F}=\frac{\alpha\sum_{i}\left(\hat{y}_{i}-y_{i}\right)^{2}+(1-\alpha)\sum_{j}\left(\hat{y}_{j}-y_{j}\right)^{2}}{2n} $$
2.2 实验分析
数据说明:
- S&P 500 盈利电话会议数据(包含 2017 年在美国证券交易所 S&P 交易的 500 家大型上市公司的财报电话会议的音频记录和相应的文本记录),合计 2243 条,经过对齐和清洗后保留 576 条(包含 8.88w 句文本和对应音频)
评价指标:MSE
多模型表现对比:
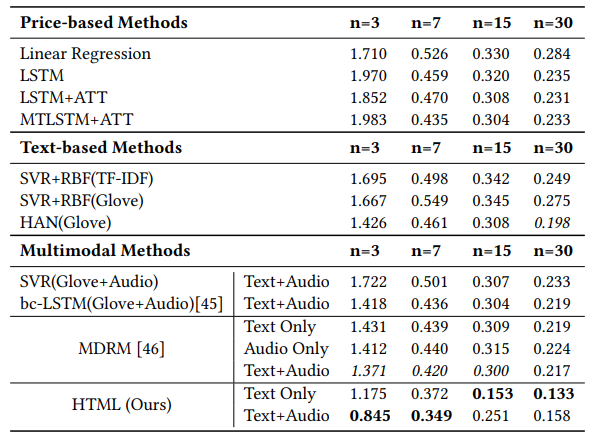
- HTML 使用文本+音频提供最准确的短期预测,但最准确的长期预测来自纯文本版本
消融实验:
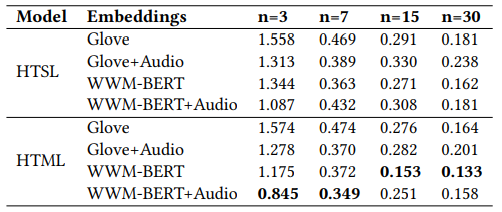
- HTSL 表示单任务学习,HTML 表示多任务学习
- 相比于 Glove 预训练模型,WWM-BERT 有显著优势
其他实验:超参 $\alpha$ 探索
- 使用纯文本数据,对于不同的预测天数,$\alpha$ 的最佳范围在 0.5 ~ 0.8 (最小化 MSE)
- 对于多模态数据,对于不同的预测天数,它往往较低,$\alpha$ 的最佳范围在 0.4 到 0.6
- 说明音频信息的融入,会促进模型对次要任务的学习侧重(证据性一般,因为 $\alpha$ 范围不太稳定)
相关资源
- 论文在线地址
- 本地文件地址:Yang et al_2020_HTML.pdf
- 本地Zotero地址:Yang et al_2020_HTML.pdf