中文标题:Sora:大视觉模型的背景、技术、局限性和机会综述
英文标题:Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
发布平台:预印本
发布日期:2024-02-28
引用量(非实时):
DOI:10.48550/arXiv.2402.17177
作者:Yixin Liu, Kai Zhang, Yuan Li, Zhiling Yan, Chujie Gao, Ruoxi Chen, Zhengqing Yuan, Yue Huang, Hanchi Sun, Jianfeng Gao, Lifang He, Lichao Sun
文章类型:preprint
品读时间:2024-03-07 14:14
1 文章萃取
1.1 核心观点
Sora 是一款由 OpenAI 在 2024 年 2 月发布的文本到视频生成的 AI 模型。该模型被训练用于根据文本指令生成现实或想象场景的视频,并展现出模拟物理世界的潜力。
本文基于公开的技术报告和逆向工程,对 Sora 模型的背景、相关技术、应用、现存挑战和文本到视频 AI 模型的未来方向进行了全面的综述
1.2 综合评价
- 视频生成领域的突破:长时间+高质量+稳定连贯
- 在物理特性、复杂动作和微表情方面仍存在理解不足
- 需要额外关注内容的公平性、安全性和道德合规性
- 由于 Sora 闭源的特性,本文只是提供了部分思路参考
1.3 主观评分:⭐⭐⭐⭐
2 精读笔记
2.1 背景知识
Sora 的特点:
- 理解并遵循用户指令,生成长达 1 分钟的高质量视频
- 支持多角色在复杂环境下的特定操作,视频的连贯性强
- 具备作为世界模拟器的潜力,理解场景的物理和动态变化
视觉领域生成式 AI 的历史:
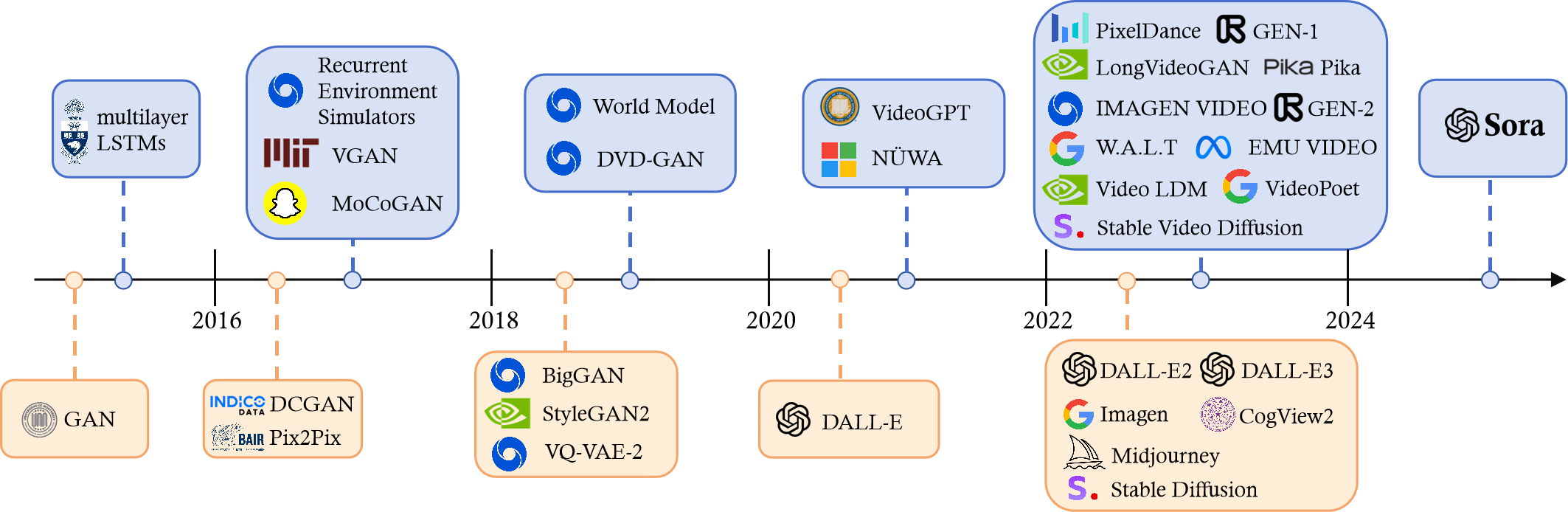
- 生成对抗网络(GAN)和变分自动编码器(VAE)的出现是第一个拐点
- 流动模型(flow models)和扩散模型,进一步增强了图像生成的细节和质量
- 得益于 Transformer 在 NLP 领域的成功,研究人员开始将其与视觉组件相结合
- CLIP 等多模态模型基于 Transformer 架构将文本和图像元素进行联合训练
- 2023年出现图像生成的商业化产品:Stable Diffusion、Midjourney、DALL-E 3
2.2 核心技术
逆向工程:Sora 框架概述
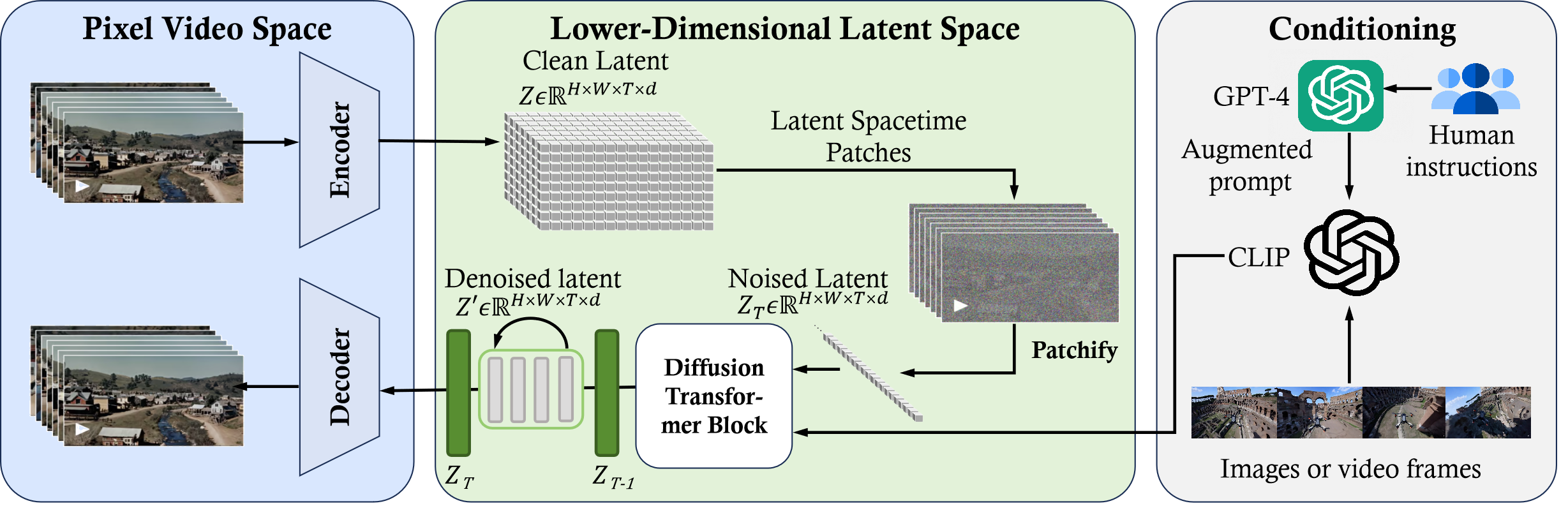
- 首先借助一个时空压缩器模块将原始视频输入从像素级视频空间(Pixel Video Space)映射到低维的潜在空间(Lower-Dimensional Latent Space)
- 然后使用 ViT 架构处理潜在空间的信息表征,输出去噪后的潜在信息表征
- 接收 LLM 增强的用户指令或视觉提示后,扩散模型生成特定主题或风格的视频
2.2.1 细节 1:统一视觉表示
数据预处理:统一视觉表示

- Sora 可以生成灵活尺寸或分辨率的图像,范围从 1920x1080p 到 1080x1920p
- Sora 生成的视频表现出更好的取景,确保在场景中完全捕捉到拍摄对象
- 这意味着 Sora 需要将所有形式的视觉数据(包括具有不同持续时间、分辨率和纵横比的图像和视频)转换为统一的表示,这有利于生成模型的大规模训练
- 虽然细节不清楚,但 Sora 需要借助模型(VAE 或 VQ-VAE )将视频压缩到低维潜在空间,然后将潜在空间的信息表示分解为时空信息补丁(patch)
最终不同尺寸输入的时空信息补丁的尺寸应该是一致的,而为了实现这一点,本文推测 Sora 可能采取了以下两种方式中的一种(1)限制了时间步长,仅考虑空间补丁压缩,然后再进行额外的时间信息聚合(2)直接进行时间+空间的补丁压缩,但使用了类似 3 D 卷积的操作来兼容不同尺寸和时长的视频
本文认为 Sora 最可能使用的打包方式是 PNP(patch n’ pack)
PNP 支持保留宽高比的可变分辨率图像或视频
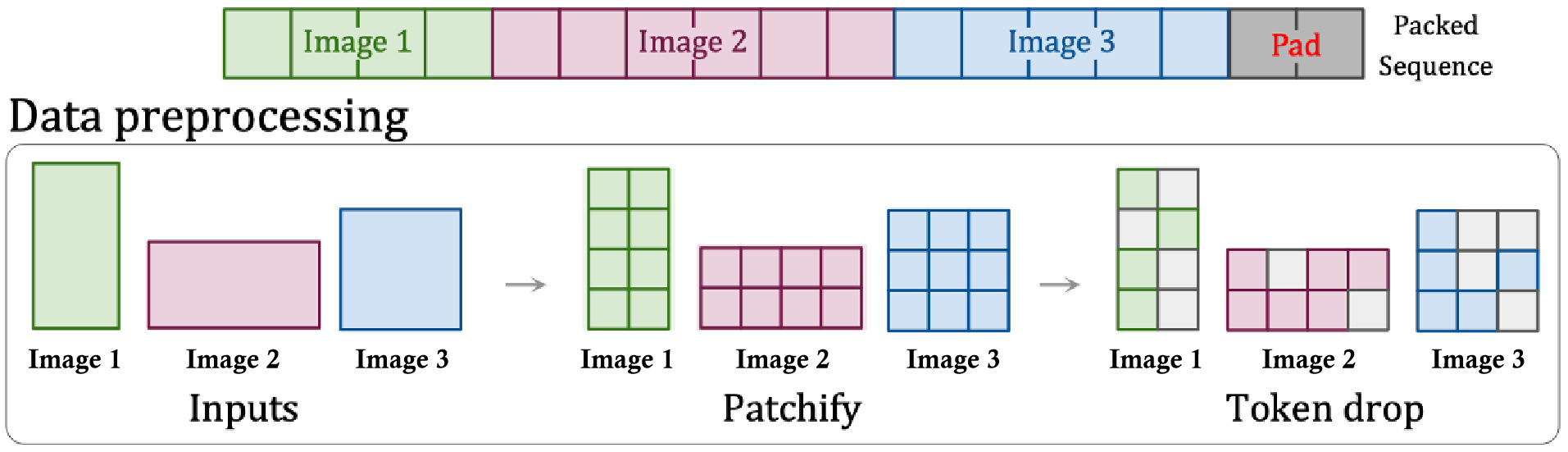
- PNP 将来自不同图像的多个补丁打包在单个序列中
- PNP 通过删除/遮蔽标记来适应对可变长度输入的有效训练
- 删除标记可以看作一种数据增强方式,但可能导致模型对细节的忽略
- OpenAI 可能会使用超长上下文窗口并打包视频中的所有标记(高计算成本)
2.2.2 细节 2:扩散变压器
本小节作为 Sora 的核心,暂时缺少足够的资料支持,只是确定扩散变压器和部分技术细节,其他部分仍然存在很多推理和思考的地方~
本小节首先介绍两个主流的图像类扩散变压器 DiT 和 U-ViT ,然后介绍了将掩码潜在建模纳入扩散模型的 MDT (Masked Diffusion Transformer),最后根据 Sora 技术报告的参考列表介绍了两个重要的视频扩散模型 Imagen Video 和 Video LDM
DiT(左)和 U-ViT(右)的整体框架:
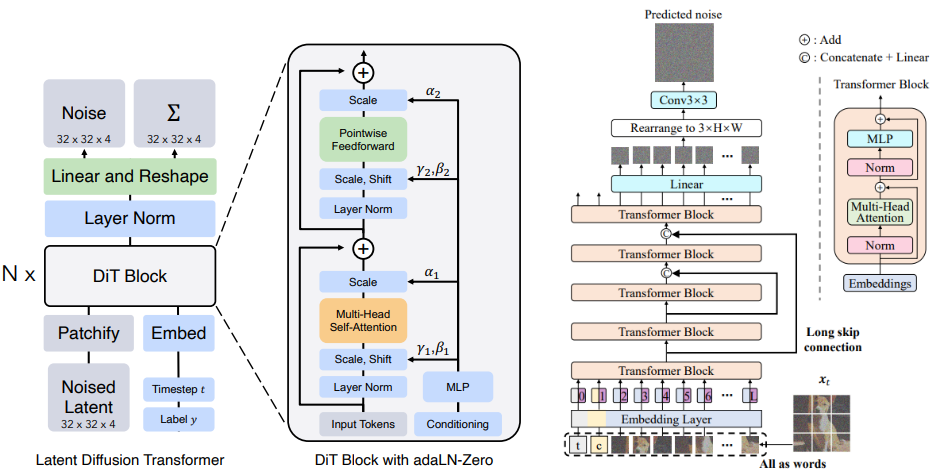
- DiT 和 U-ViT 是最早将视觉变换器(ViT)用于潜在扩散模型的两个模型
- DiT 先通过 patchify 操作将输入图像切割成一系列尺寸固定的小块,所有小块映射到一个高维空间并组成一个向量序列;DiT 的核心组件依然是多头自注意力层和点式前馈网络,只不过 DiT 会根据输入条件信息的嵌入表示之间回归预测不同层之间的缩放和平移(即自适应层范数 AdaLN)
- U-ViT 则将时间 t、条件 c、图像块拼接成一个序列(视作文本的 token 序列)作为输入,然后经过位置编码和一系列的 Transformer 层;U-ViT 的不同层之间会通过长跳跃连接(Long skip connection)来实现跨层的信息融合
- 扩散模型的去噪过程,可以转化为扩散变压器模型对噪声的预测
Masked Diffusion Transformer(MDT)的整体框架:

- 上图中,实线/虚线分别表示每个时间步的训练/推理过程
- MDT 在潜在空间中进行扩散过程以节省计算成本;MDT 将潜在掩码建模纳入扩散过程,显式增强上下文学习能力,改善了模型对图像内 token 间的关系理解
- MDT 设计了一个非对称屏蔽扩散变压器(AMDT),以扩散生成方式从未屏蔽的令牌中预测屏蔽的令牌。AMDT 包括一个编码器、一个侧面插值(side-interpolated)器和一个解码器
- 编码器仅在训练期间处理未屏蔽的标记,而在推理期间处理所有标记;由小型网络实现的侧面插值器旨在在训练期间从编码器输出中预测屏蔽标记,在推理时可删除
Imagen Video 的整体框架:
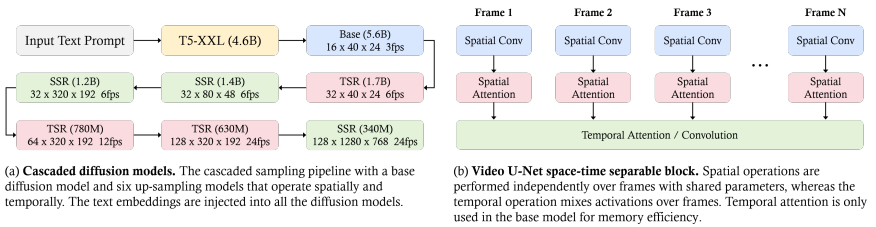
- Imagen Video 是由 7 个子模型(1 个 T5 文本编码器、1 个基础视频扩散模型、3 个 SSR 扩散模型、 3 个 TSR 扩散模型)组成的级联架构,共 116 亿个参数
- T5 模型将文本 prompt 编码为嵌入表示,基础视频扩散模型则以文本为条件,生成初始视频;SSR 空间超分辨率模型提升视频的分辨率;TSR 时域超分辨率模型提高视频的帧数;除了 T 5 文本编码器不需要训练,其他 6 个子模型之间的训练是单独并行的
- 基础视频和超分辨率模型(SSR/TSR)以时空可分离的方式使用 3D U-Net 架构。该架构将时间注意力层和卷积层与空间对应层编织在一起,以有效捕获帧间依赖性
- Imagen Video 能根据短文本生成不同风格的视频,视频一致性较强并具备较好的结构理解
Video LDM 的整体框架:
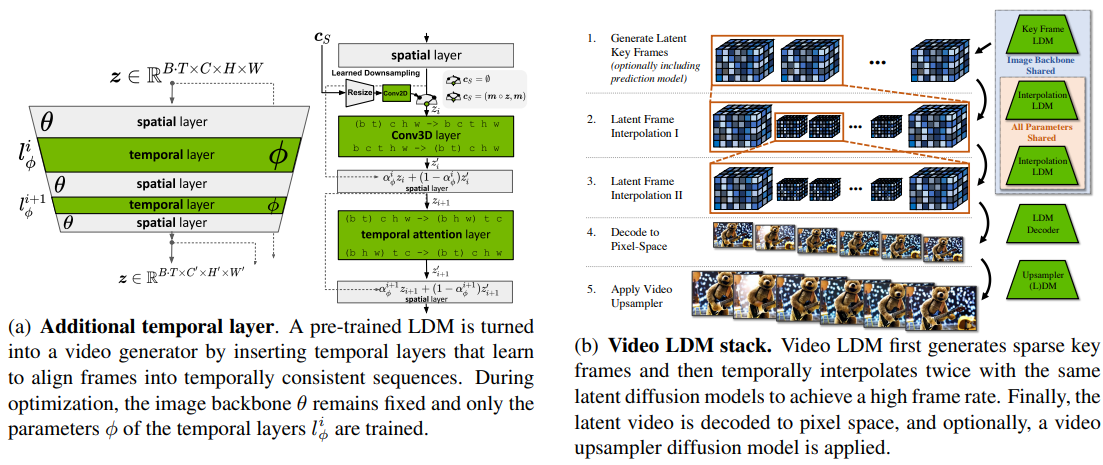
- LDM 的视频生成流程(图b):1. 基于预训练的图像 LDM 模型生成离散的关键帧; 2. 使用插值模型(Interpolation LDM)在关键帧之间进行时序插值,以提高帧率; 3. 重复第 2 步继续提高帧率; 4. 将前向量解码到像素空间;5. 使用上采样(Upsampler)模型继续改善分辨率
- 视频 LDM 模型的关键技巧(图 a ):在图像 LDM 模型的基础上交错加入时间层(temporal layer,绿色部分)来理解不同关键帧之间的时间概念,从而生成连续的视频帧
- 时间层则主要包括 3D 卷积(Conv3D)层和时间注意力层(temporal attention)两种类型
- 视频 LDM 模型是图像 LDM 模型的拓展,训练和推理计算成本低(微调发生在低维潜在空间),通过关键帧插值可以实现较长时间视频的生成
本文通过逆向工程推测:
- Sora 使用了空间和时间上采样的级联扩散结构来生成高分辨率视频
- Sora 很可能将分辨率较低的较长视频用于训练(维持时间一致性)
- Sora 很可能自行训练了时空 VAE 编码器,而不是已有的预训练 VAE
2.2.3 细节 3:文本与提示
Sora 采用了与 DALL·E 3 类似的方法来解决指令跟随(prompt following)问题
- 指令跟随问题:文生图模型可能会忽视给定的文字描述中的词语、词顺序或具体含义
- DALL·E 3 通过训练一个强大的描述性字幕器(图像-文本生成器),并利用字幕器生成详细准确的文本/字幕来描述图像,从而生成更优质的文图配对数据来微调文生图模型
- 为了更好地匹配实际用户的文本提示和训练集中描述图像的文本/字幕,DALL·E 3 还会借助 LLMs 将简短的用户提示重写为详细而冗长的指令,确保推理过程的文本输入与训练过程的文本输入一致
- Sora 能够满足不同的用户需求,关注指令细节的一丝不苟,并生成精确满足用户需求的视频
一个精心设计的文本提示,能确保 Sora 生成与预期视觉非常吻合的视频:

- 蓝色文本突出了 Sora 生成所需要考虑的元素(时尚女性、黑色皮夹克+红色内搭、墨镜...)
- 黄色文本强度模型对动作、场景和角色外观的诠释(东京街头漫步、自信而随性、霓虹...)
Sora 可以利用视觉和文本信息将静态图像转换为动态的、叙事驱动的视频:
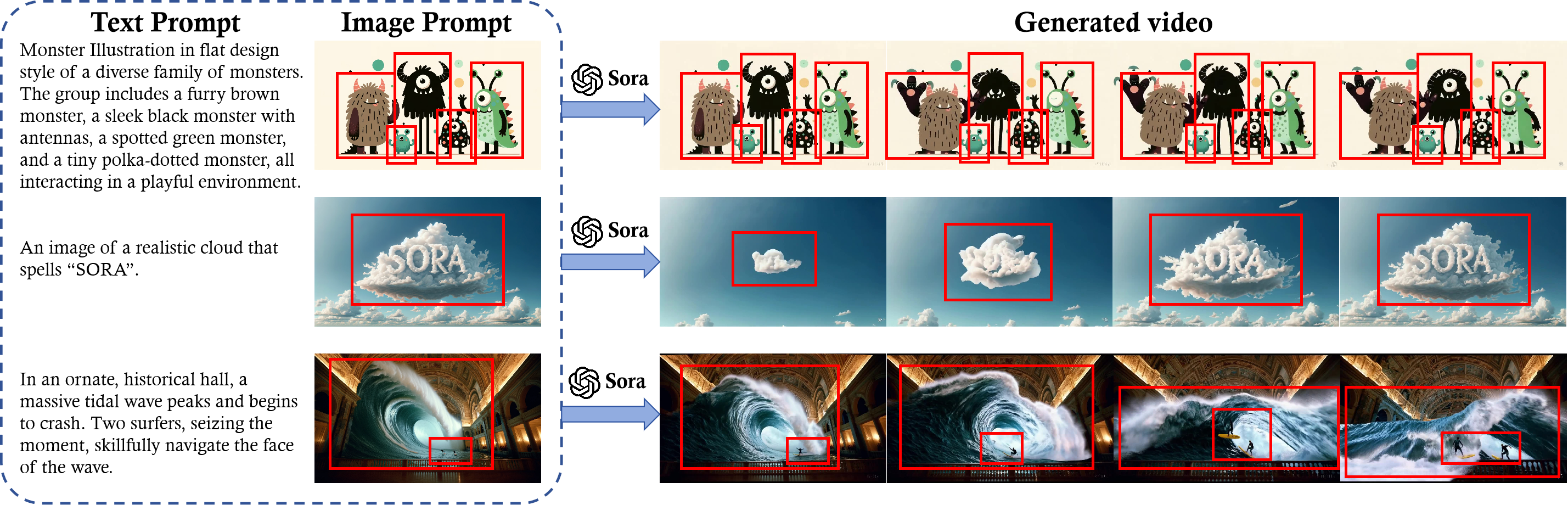
- 红色边框在视觉上锚定了每个场景的关键元素
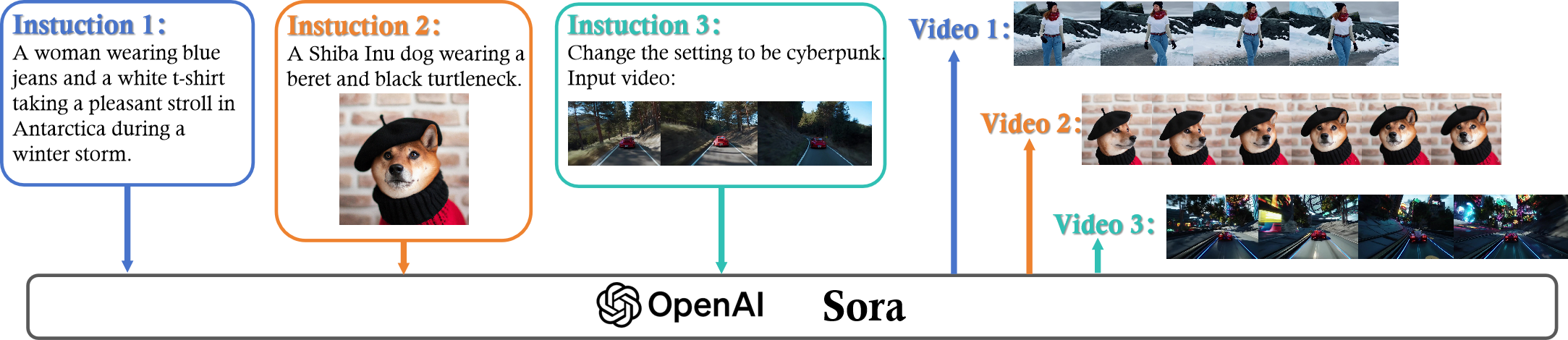
除了文本提示和图像提示,Sora 还可以用视频作为提示,进行视频的拓展、编辑和拼接:
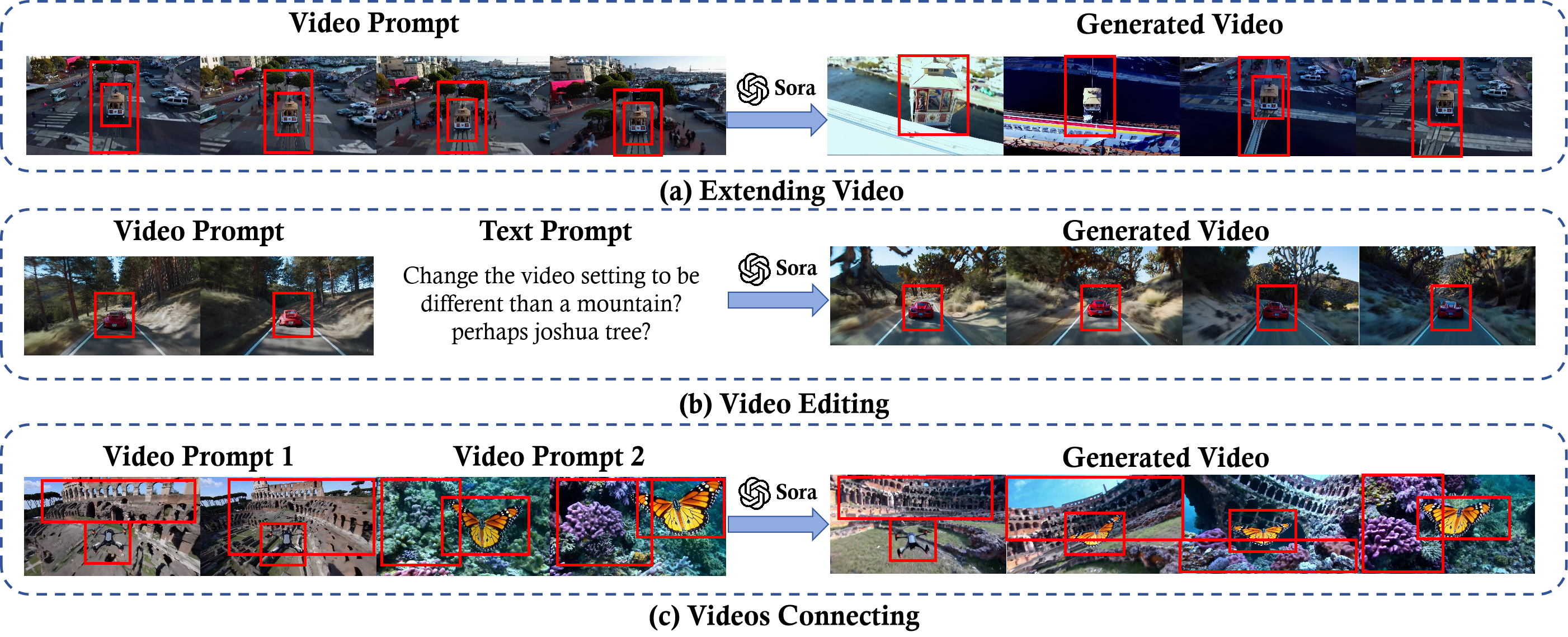
2.3 讨论与应用
可信度与安全问题:
- 大型多模态模型更容易受到“越狱”攻击(jailbreak,即用户试图利用漏洞生成禁止或有害内容),因为视觉输入的连续和高维性质意味更大范围的攻击面,使得模型抵御对抗性攻击的能力较弱
- 由于模型的复杂的训练集和训练方法,模型生成结果的真实性需要增强,幻觉问题(模型容易产生看似合理但毫无根据或错误的结果)影响着模型输出的可靠性和可信度
- 可信度的另一个重要方面是公平和偏见,开发不会延续或加剧社会偏见(种族、性别或其他敏感属性)的模型至关重要;通过检测和减轻数据集中的偏见,或者使用算法设计来主动抵消此类偏差的传播
- 在数据隐私问题不断升级的时代,保护用户数据变得前所未有的重要。公众对个人数据处理方式的认识和关注不断增强,促使对大型模型进行更严格的评估
Sora 的可应用领域:
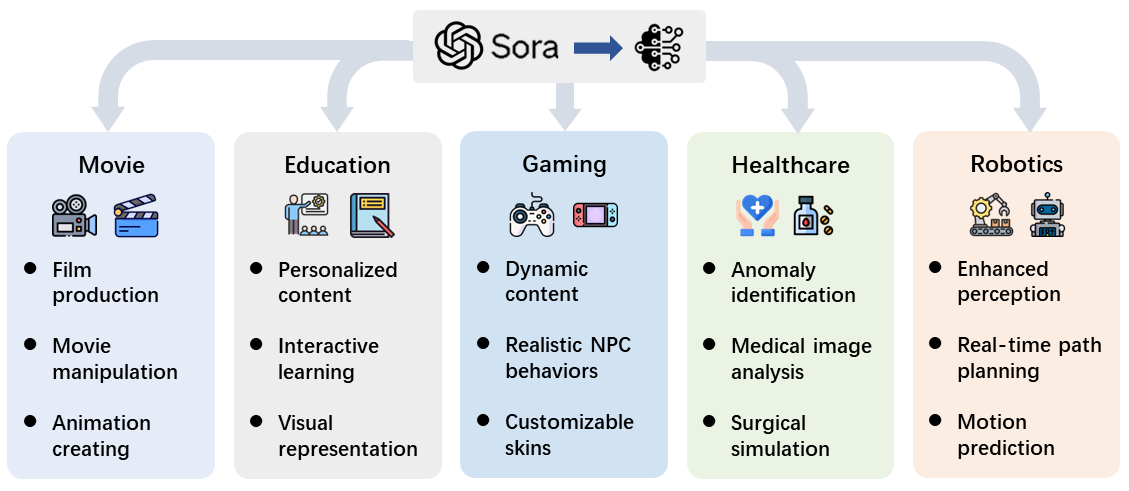
- 电影:Sora 等模型能轻松制作引人入胜的电影内容,标志着电影制作民主化的关键时刻
- 教育:实现学习资料的定制化,提高学习者的参与感、交互性,降低复杂概念的理解门槛
- 游戏:实时产生动态高质量的音视频,游戏的开发、玩法和体验方式都将得到改变与创新
- 医疗:识别体内的动态异常;改进诊断过程;实现个性化患者护理(注意隐私和医疗道德)
- 机器人:增强机器人视觉和理解能力,为机器人生成多样化训练场景(有望带来突破性进展)
局限性:
- 对复杂场景中的物理原理处理不到位(吃一口饼干后可能不会产生相应的咬痕)
- 现实的物理建模和运动模拟仍存在问题(物体不自然或对椅子等刚性结构不正确)
- 误解给定提示中物体和角色之间的放置或排列,从而导致方向上的混乱(左右不分)
- 在保持事件的时间准确性方面存在物体(可能插入不相干的人或物,偏离计划的布局)
- 在人机交互 (HCI) 领域存在限制,用户有时候会难以描述某些动作细节或场景切换逻辑(限制了Sora在视频编辑和增强方面的潜力,也影响了用户体验的整体满意度)
- 尚未确定具体的发布日期,说明在安全、隐私保护、内容审核等方面仍需改进和测试
机遇与影响:
- 科研:为科研领域提供了新思路,鼓励使用扩散技术和 Transformer 技术更深入地探索文本到视频模型;强调利用未经修改的数据集的好处,开辟了创建更先进的生成模型的新途径
- 行业:可能引发游戏领域的革命性变化;降低广告视频的制作成本;改变品牌与受众的互动方式
- 社会:内容创作模式的改变,带来了强调创造和参与的新时代;编剧和创意者能更好地展示和分享自己的创作理念;新闻/解说视频的快速生成,新闻内容更加生动;为视觉叙事提供更强大的解决方案
相关资源
- 论文在线地址
- 本地文件地址:Liu et al_2024_Sora.pdf
- 本地Zotero地址:Liu et al_2024_Sora.pdf