仅搜集收录了部分个人感兴趣的文章,并进行简单记录
1 概念科普
1.1 利用 AI 大模型,破解医疗数据困境
2024-03-16 15:31 文章链接
患者、医疗数据、基础模型三者的关系:
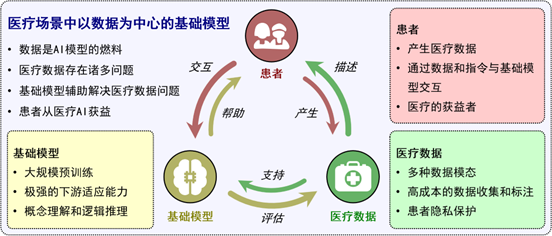
基础模型的优势:
- 数据增强:例如哈佛大学的研究者利用 DALL-E 生成皮肤病图片来训练分类模型,浙江大学的研究者开发的 PathAsst 基础模型能够生成病理学子领域的指令样本来训练其他模型
- 数据高效利用:上海交通大学的研究者利用医学语言基础模型所包含的对医学图像和概念的理解,引导通过自然图像训练的视觉模型迁移至病理图像,从而完成病理图像少样本分类任务。又如,哈佛大学的研究者们实验验证了医疗领域的基础语言模型能在罕见病的诊断中发挥作用
- 辅助数据标注:在医疗数据上微调的大语言模型 Med-PaLM 2 能够进行高质量的医学问答,其回答堪比甚至超过专业临床医生,可以用于医疗文本数据的标注;通用领域视觉分割基础模型 SAM 在医学图像上有较好的分割表现 ;OpenMEDLab 和上海交通大学的研究者们基于 SAM,开发了名为MedLSAM 的 3D CT 图像定位+分割基础模型 ,能够保证不受数据集大小影响的、常数时间的 3D 医学图像标注,大大降低了标注成本
- 支持多模态数据融合:微软的 Benedikt Boecking 等人在大量胸片和其对应的放射报告上训练 BioViL 模型,以获得相匹配的图像和语言特征;斯坦福大学的研究者们大量收集了 Twitter 上包含特定关键词的内容和对应的病理图像,构建了病理图像文本对的公开数据集 OpenPath,并在此数据集上训练了 PLIP 模型;斯坦福大学的研究人员将图片和文字输入拼接成一个序列,经过大语言模型得到输出,并对融合模块进行训练开发了 Med-Flamingo 模型,在涉及医疗图片的问答任务上展现出了很强的少样本学习能力
- 数据隐私:基础模型可以生成足以用于模型训练但不包含任何患者隐私信息的数据
- 模型评估:结合人类专家与利用基础模型的自动评估来获得更高质量的评估结果
基础模型的缺陷:
- 幻觉问题:基础模型可能生成看似合理但实际不准确的内容
- 模型偏见:源于训练数据中对某些群体、地域、性别的偏见
- 规范化监管:明确基础模型的实际应用目的和范围,在权威数据上进行性能基准测试,制定用户使用指南,并通过临床试验验证有效性等;在模型部署后,也需持续监管以适应不断变化的任务和环境
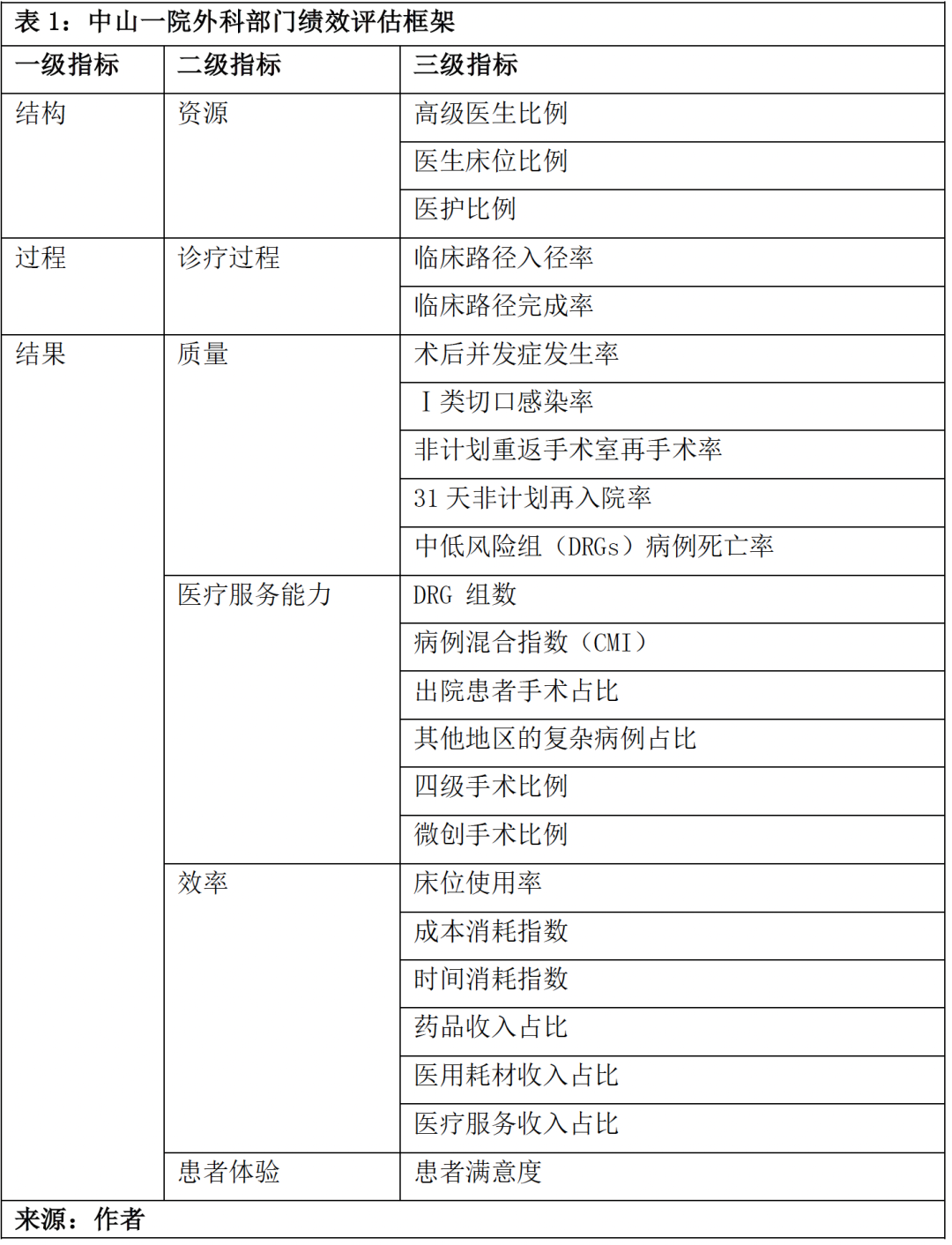
1.2 大数据驱动的绩效评估与改进
2024-03-23 13:58 文章链接
2 模型预测
2.1 机器学习预测死亡风险,改进姑息治疗实践
2024-01-27 11:30 文章链接
数据说明:
- 匹兹堡大学医学中心(UPMC) EHR 系统中获取的与健康相关的数据
- 在2019年,UPMC 医院的出院患者共有306,456人次,就诊人数为201,829人次,平均(中位数)年龄为54.9(60)岁,54.4%为女性,中位住院时间为2.6天
- 机器学习分析人群包括在2015年1月1日至2019年12月31日期间住院的成人参与者
主要结局:以入院日期为起始时间观察到的 90 天内死亡风险
特征变量:
- 82 个连续特征(如年龄)和 308 个分类特征(如性别)与每位住院患者相关联
- 分类:社会人口学、既往医疗保健使用情况、人体测量值和实验室检测值以及合并症
- 在机器学习分析的 611,543 例患者中,77% 患者纳入训练集, 23% 患者纳入验证集
建模结果:
- 高于 0.80 为高风险分类,高于 0.40~0.80 为中度风险分类,低于 0.40 为低风险分类
- 从 2021 年 1 月 1 日到 2022 年 11 月 10 日 ,59.7% 的高风险分类住院患者(即预测死亡概率高于 0.80) 最终在入院后 90 天内死亡。中危和低危患者的相应比例分别为 29.4% 和 4.3%
改进姑息治疗实践部分略:
- 实时嵌入 EHR,提高患者医疗和运营效率
- 对特定患者自动发送临床触发器(如中高危患者的 GOC 对话和姑息治疗会诊)