1 常见 Pandas 参数配置
pd.set_option('display.max_rows', 5) # 最大显示行数
pd.set_option('display.max_columns', 15) # 最大显示列数
pd.set_option('display.max_colwidth', 15) # 每列的最大宽度
pd.set_option('display.float_format', '${:,.2f}') # 设置浮点数的显示格式
pd.set_option('display.precision', 4) # 设置浮点数的小数显示精度
2 Series 与 DataFrame 的互转
# 利用to_frame()实现Series转DataFrame
s = pd.Series([0, 1, 2])
s = s.to_frame(name='列名')
# 单列数据的DataFrame转为Series
s.squeeze()
3 减少类别型数据的内存消耗
类别型数据包含大量重复值,因此存在不必要的内存消耗
使用 astype('category'),可以优化存储,减少内存消耗
import numpy as np
pool = ['A', 'B', 'C', 'D']
df = pd.DataFrame({
'V1': np.random.choice(pool, 1000000)
}) # V1列由ABCD大量重复形成
# 查看内存使用情况:58M
df.memory_usage(deep=True)
df['V1'] = df['V1'].astype('category') df.memory_usage(deep=True)
# 查看内存使用情况:1M
df.memory_usage(deep=True)
4 警惕 object 类型陷阱
object 在 pandas 中可以代表不确定的数据类型
类型为 object 的 Series 中可以混杂着多种数据类型
s = pd.Series(['111100', '111100', 111100, '111100'])
# s的类型就是object类型,但其实里面包含了整数型
s.str.replace('00', '11')
# 直接调用replace会导致整数型数据变为NaN
s.astype('str').str.replace('00', '11')
# 应该先做类型转换,再调用replace方法
5 基于范围条件进行表连接
普通做法:先按照关键列进行关联,再进行范围条件过滤
进阶做法:直接借用 pyjanitor 包的条件连接方法(支持 numba 加速运算)
# pip install pyjanitor
import janitor
import pandas as pd
# 示例数据框
demo_left = pd.DataFrame( {
'left_id': ['a', 'b', 'c'],
'datetime': ['2023-01-01', '2023-02-01', '2023-03-01'] } )
demo_right = pd.DataFrame( {
'right_id': ['a', 'a', 'b', 'b'],
'datetime': ['2022-12-28', '2023-01-06', '2023-02-15', '2023-02-02'] } )
demo_left['datetime'], demo_right['datetime'] = pd.to_datetime(demo_left['datetime']), pd.to_datetime(demo_right['datetime'])
(
demo_left
# 添加辅助范围判断用上下限字段
.assign(
datetime_past_limit=demo_left['datetime'] - pd.Timedelta(days=7),
datetime_future_limit=demo_left['datetime'] + pd.Timedelta(days=7)
)
# 执行条件连接
.conditional_join(
demo_right,
('left_id', 'right_id', '=='),
('datetime_past_limit', 'datetime', '<='),
('datetime_future_limit', 'datetime', '>=')
)
)
6 处理 SettingWithCopyWarning 问题
Pandas 中的操作有时会返回数据的视图(View),有时会返回数据的副本(Copy)
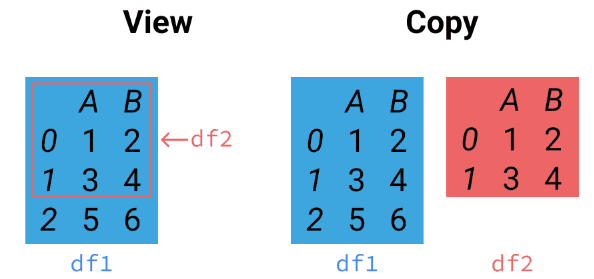
在视图上的修改会影响原始数据,而在副本上的修改不会影响原始数据。因此在链式赋值等场景下,pandas可能报出SettingWithCopyWarning的警告,这类警告通常意味着程序并不知道赋值过程是否成功,因此是值得重视的
SettingWithCopyWarning的解决方案:
- 更改原始数据时,使用单一赋值操作(loc)
data.loc[data.bidder == 'parakeet2004', 'bidderrate'] = 100
- 需要处理副本时,显式调用copy()创建副本
winners = data.loc[data.bid == data.price].copy()
winners.loc[304, 'bidder'] = 'therealname'
- 直接关闭警告(不推荐)
pd.set_option('mode.chained_assignment', None)
回顾历史来看,这一警告的成因既包括对多种索引的兼容,也有为了继承Numy数组优质特性的妥协。总的来说,SettingWithCopyWarning 的复杂性是 Pandas 库中为数不多的坑
参考
SettingWithCopyWarning 原理与解决方案
6个冷门但实用的 pandas 知识点
pandas中基于范围条件进行表连接