1 情感分析与数据集
情感分析(sentiment analysis):研究人们在文本中 (如产品评论、博客评论和论坛讨论等)“隐藏”的情绪
常见应用领域
- 政治(如公众对政策的情绪分析)
- 金融(如市场情绪分析)
- 营销(如产品研究和品牌管理)
情感分析采用的示例数据集是电影评价数据集
基于PyTorch的情感分析数据读取与预处理:
import os
import torch
from torch import nn
from d2l import torch as d2l
#@save
d2l.DATA_HUB['aclImdb'] = (
'http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz',
'01ada507287d82875905620988597833ad4e0903')
data_dir = d2l.download_extract('aclImdb', 'aclImdb')
#@save
def read_imdb(data_dir, is_train):
"""读取IMDb评论数据集文本序列和标签"""
data, labels = [], []
for label in ('pos', 'neg'):
folder_name = os.path.join(data_dir, 'train' if is_train else 'test',
label)
for file in os.listdir(folder_name):
with open(os.path.join(folder_name, file), 'rb') as f:
review = f.read().decode('utf-8').replace('\n', '')
data.append(review)
labels.append(1 if label == 'pos' else 0)
return data, labels
train_data = read_imdb(data_dir, is_train=True)
print('训练集数目:', len(train_data[0]))
# 训练集数目: 25000
#@save
def load_data\_imdb(batch_size, num_steps=500): # 截断填充后长度默认为5000
"""返回数据迭代器和IMDb评论数据集的词表"""
data_dir = d2l.download_extract('aclImdb', 'aclImdb')
train_data = read_imdb(data_dir, True)
test_data = read_imdb(data_dir, False)
train_tokens = d2l.tokenize(train_data[0], token='word') # 创建词表
test_tokens = d2l.tokenize(test_data[0], token='word')
vocab = d2l.Vocab(train_tokens, min_freq=5) # 过滤次数<5的词
train_features = torch.tensor([d2l.truncate_pad(
vocab[line], num_steps, vocab['<pad>']) for line in train_tokens])
test_features = torch.tensor([d2l.truncate_pad(
vocab[line], num_steps, vocab['<pad>']) for line in test_tokens])
train_iter = d2l.load_array((train_features, torch.tensor(train_data[1])),batch_size)
test_iter = d2l.load_array((test_features, torch.tensor(test_data[1])),
batch_size,is_train=False)
return train_iter, test_iter, vocab
2 情感分析:使用RNN
基于BiRNN的情感分析:
- 使用预训练的GloVe模型来表示每个词元(构建词向量)
- 将词向量输入多层BiRNN网络,获得文本序列的表示
- 将文本序列表示通过简单线性层MLP转化为情感预测(积极1;消极0)
基于PyTorch的BiRNN情感分析建模:
import torch
from torch import nn
from d2l import torch as d2l
batch_size = 64
train_iter, test_iter, vocab = d2l.load_data\_imdb(batch_size)
class BiRNN(nn.Module):
def __init__(self, vocab_size, embed_size, num_hiddens,
num_layers, **kwargs):
super(BiRNN, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embed_size)
# 将bidirectional设置为True以获取双向循环神经网络
self.encoder = nn.LSTM(embed_size, num_hiddens, num_layers=num_layers,bidirectional=True)
self.decoder = nn.Linear(4 * num_hiddens, 2)
def forward(self, inputs):
# inputs的形状是(批量大小,时间步数)
# 因为长短期记忆网络要求其输入的第一个维度是时间维,
# 所以在获得词元表示之前,输入会被转置。
# 输出形状为(时间步数,批量大小,词向量维度)
embeddings = self.embedding(inputs.T)
self.encoder.flatten_parameters()
# 返回上一个隐藏层在不同时间步的隐状态,
# outputs的形状是(时间步数,批量大小,2*隐藏单元数)
outputs, _ = self.encoder(embeddings)
# 连结初始和最终时间步的隐状态,作为全连接层的输入,
# 其形状为(批量大小,4*隐藏单元数)
encoding = torch.cat((outputs[0], outputs[-1]), dim=1)
outs = self.decoder(encoding)
return outs
embed_size, num_hiddens, num_layers = 100, 100, 2
devices = d2l.try_all_gpus()
net = BiRNN(len(vocab), embed_size, num_hiddens, num_layers)
def init_weights(m):
if type(m) == nn.Linear:
nn.init.xavier_uniform_(m.weight)
if type(m) == nn.LSTM:
for param in m._flat_weights_names:
if "weight" in param:
nn.init.xavier_uniform_(m._parameters[param])
net.apply(init_weights);
# 加载预训练模型
glove_embedding = d2l.TokenEmbedding('glove.6b.100d')
embeds = glove_embedding[vocab.idx_to_token]
net.embedding.weight.data.copy_(embeds)
net.embedding.weight.requires_grad = False
# 训练和评估模型
lr, num_epochs = 0.01, 5
trainer = torch.optim.Adam(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss(reduction="none")
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,
devices)
# loss 0.518, train acc 0.748, test acc 0.743
# 789.9 examples/sec on [device(type='cuda', index=0), device(type='cuda', index=1)]
#@save
def predict_sentiment(net, vocab, sequence):
"""预测文本序列的情感"""
sequence = torch.tensor(vocab[sequence.split()], device=d2l.try_gpu())
label = torch.argmax(net(sequence.reshape(1, -1)), dim=1)
return 'positive' if label == 1 else 'negative'
predict_sentiment(net, vocab, 'this movie is so great') # 'positive'
predict_sentiment(net, vocab, 'this movie is so bad') # 'negative'
3 情感分析:使用CNN
基于BiRNN的情感分析:
- 使用预训练的GloVe模型来表示每个词元(构建词向量)
- 使用textCNN模型架构将词向量转化为情感预测(积极1;消极0)
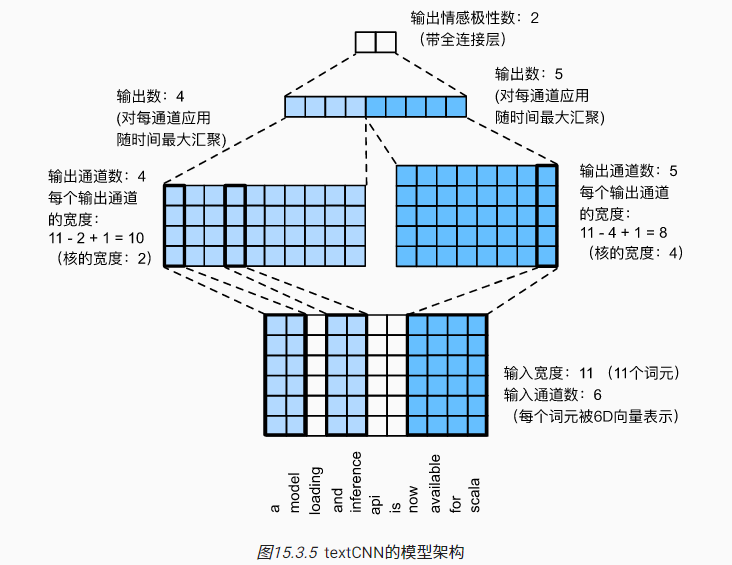
一个简单的textCNN模型示例:
- 输入为长度11的句子(11个词元),每个词元由6维向量表示
- 定理两个一维卷积核,左侧卷积核宽度为2,通道数为4,最终输出维度为$4\times 10$;右侧卷积核宽度为4,通道数为5,最终输出维度为$5\times 8$
- 对每个通道进行最大池化(汇聚),最近拼接在一起,并通过全连接层实现预测
基于PyTorch的CNN情感分析建模:
import torch
from torch import nn
from d2l import torch as d2l
batch_size = 64
train_iter, test_iter, vocab = d2l.load_data\_imdb(batch_size)
def corr1d(X, K):
"""一维互相关"""
w = K.shape[0]
Y = torch.zeros((X.shape[0] - w + 1))
for i in range(Y.shape[0]):
Y[i] = (X[i: i + w] * K).sum()
return Y
def corr1d_multi_in(X, K):
"""通道为K的一维互相关"""
# 首先,遍历'X'和'K'的第0维(通道维)。然后,把它们加在一起
return sum(corr1d(x, k) for x, k in zip(X, K))
class TextCNN(nn.Module):
def __init__(self, vocab_size, embed_size, kernel_sizes, num_channels,
**kwargs):
super(TextCNN, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embed_size)
# 这个嵌入层不需要训练
self.constant_embedding = nn.Embedding(vocab_size, embed_size)
self.dropout = nn.Dropout(0.5)
self.decoder = nn.Linear(sum(num_channels), 2)
# 最大时间汇聚层没有参数,因此可以共享此实例
self.pool = nn.AdaptiveAvgPool1d(1)
self.relu = nn.ReLU()
# 创建多个一维卷积层
self.convs = nn.ModuleList()
for c, k in zip(num_channels, kernel_sizes):
self.convs.append(nn.Conv1d(2 * embed_size, c, k))
def forward(self, inputs):
# 沿着向量维度将两个嵌入层连结起来,
# 每个嵌入层的输出形状都是(批量大小,词元数量,词元向量维度)连结起来
embeddings = torch.cat((
self.embedding(inputs), self.constant_embedding(inputs)), dim=2)
# 根据一维卷积层的输入格式,重新排列张量,以便通道作为第2维
embeddings = embeddings.permute(0, 2, 1)
# 每个一维卷积层在最大时间汇聚层合并后,获得的张量形状是(批量大小,通道数,1)
# 删除最后一个维度并沿通道维度连结
encoding = torch.cat([
torch.squeeze(self.relu(self.pool(conv(embeddings))), dim=-1)
for conv in self.convs], dim=1)
outputs = self.decoder(self.dropout(encoding))
return outputs
# 创建一个textCNN实例。它有3个卷积层,卷积核宽度分别为3、4和5,均有100个输出通道
embed_size, kernel_sizes, nums_channels = 100, [3, 4, 5], [100, 100, 100]
devices = d2l.try_all_gpus()
net = TextCNN(len(vocab), embed_size, kernel_sizes, nums_channels)
def init_weights(m):
if type(m) in (nn.Linear, nn.Conv1d):
nn.init.xavier_uniform_(m.weight)
# 初始化权重
net.apply(init_weights);
# 加载预训练模型-glove
glove_embedding = d2l.TokenEmbedding('glove.6b.100d')
embeds = glove_embedding[vocab.idx_to_token]
net.embedding.weight.data.copy_(embeds)
net.constant_embedding.weight.data.copy_(embeds)
net.constant_embedding.weight.requires_grad = False
# 训练
lr, num_epochs = 0.001, 5
trainer = torch.optim.Adam(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss(reduction="none")
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs, devices)
# 预测 验证
d2l.predict_sentiment(net, vocab, 'this movie is so great') # 'positive'
d2l.predict_sentiment(net, vocab, 'this movie is so bad') # 'negative'
4 自然语言推断与数据集
自然语言推断(natural language inference)
- 主要研究 假设(hypothesis)是否可以从前提(premise)中推断出来
- 假设和前提都是文本序列,推断是在寻找一对文本序列间的逻辑关系
假设和前提间常见的逻辑关系:
- 蕴涵(entailment):假设可以从前提中推断出来
- 矛盾(contradiction):假设的否定可以从前提中推断出来
- 中性(neutral):所有其他情况
自然语言推断采用的示例数据集是斯坦福自然语言推断语料库(Stanford Natural Language Inference,SNLI):
- 包含500000多个带标签的英语句子对
- “0”、“1”和“2”分别对应于“蕴涵”、“矛盾”和“中性”
- 不同逻辑关系的句子对数量是相对均衡的
基于PyTorch的自然语言推断数据读取与预处理:
import os
import re
import torch
from torch import nn
from d2l import torch as d2l
#@save
d2l.DATA_HUB['SNLI'] = (
'https://nlp.stanford.edu/projects/snli/snli_1.0.zip',
'9fcde07509c7e87ec61c640c1b2753d9041758e4')
data_dir = d2l.download_extract('SNLI')
#@save
def read_snli(data_dir, is_train):
"""将SNLI数据集解析为前提、假设和标签"""
def extract_text(s):
# 删除我们不会使用的信息
s = re.sub('\\(', '', s)
s = re.sub('\\)', '', s)
# 用一个空格替换两个或多个连续的空格
s = re.sub('\\s{2,}', ' ', s)
return s.strip()
label_set = {'entailment': 0, 'contradiction': 1, 'neutral': 2}
file_name = os.path.join(data_dir, 'snli_1.0_train.txt'
if is_train else 'snli_1.0_test.txt')
with open(file_name, 'r') as f:
rows = [row.split('\t') for row in f.readlines()[1:]]
premises = [extract_text(row[1]) for row in rows if row[0] in label_set]
hypotheses = [extract_text(row[2]) for row in rows if row[0] \
in label_set]
labels = [label_set[row[0]] for row in rows if row[0] in label_set]
return premises, hypotheses, labels
#@save
class SNLIDataset(torch.utils.data.Dataset):
"""用于加载SNLI数据集的自定义数据集"""
def __init__(self, dataset, num_steps, vocab=None):
self.num_steps = num_steps
all_premise_tokens = d2l.tokenize(dataset[0])
all_hypothesis_tokens = d2l.tokenize(dataset[1])
if vocab is None:
self.vocab = d2l.Vocab(all_premise_tokens + \
all_hypothesis_tokens, min_freq=5, reserved_tokens=['<pad>'])
else:
self.vocab = vocab
self.premises = self._pad(all_premise_tokens)
self.hypotheses = self._pad(all_hypothesis_tokens)
self.labels = torch.tensor(dataset[2])
print('read ' + str(len(self.premises)) + ' examples')
def _pad(self, lines):
return torch.tensor([d2l.truncate_pad(
self.vocab[line], self.num_steps, self.vocab['<pad>'])
for line in lines])
def __getitem__(self, idx):
return (self.premises[idx], self.hypotheses[idx]), self.labels[idx]
def __len__(self):
return len(self.premises)
#@save
def load_data_snli(batch_size, num_steps=50):
"""下载SNLI数据集并返回数据迭代器和词表"""
num_workers = d2l.get_dataloader_workers()
data_dir = d2l.download_extract('SNLI')
train_data = read_snli(data_dir, True)
test_data = read_snli(data_dir, False)
train_set = SNLIDataset(train_data, num_steps)
test_set = SNLIDataset(test_data, num_steps, train_set.vocab)
train_iter = torch.utils.data.DataLoader(train_set, batch_size,
shuffle=True,
num_workers=num_workers)
test_iter = torch.utils.data.DataLoader(test_set, batch_size,
shuffle=False,
num_workers=num_workers)
return train_iter, test_iter, train_set.vocab
5 自然语言推断:使用注意力
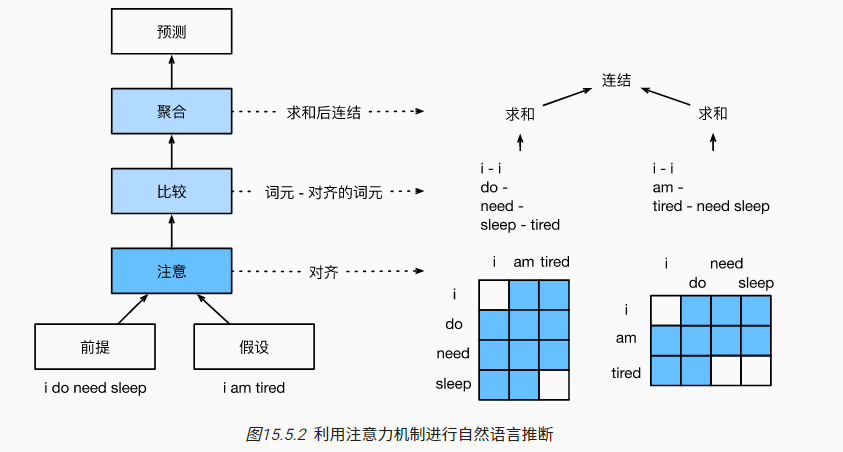
基于注意力的自然语言推断方法,主要包括三个步骤:注意、比较和聚合
注意(Attending)
- 序列$A=(a_1,...,a_n)$表示前提,序列$B=(b_1,...,b_m)$表示假设
- 注意力权重$e_{ij}=f(a_i)^Tf(b_j)$,其中$f$为多层感知机MLP
- 对于序列$A$中的第$i$个词元来说,序列$B$的表示为$\beta_i=\Sigma_{j=1}^n\frac{exp(e_{ij})}{\Sigma_{k=1}^nexp(e_{ik})}b_j$
- 对于序列$B$中的第$j$个词元来说,序列$A$的表示为$\alpha_j=\Sigma_{i=1}^m\frac{exp(e_{ij})}{\Sigma_{k=1}^mexp(e_{kj})}a_i$
加速技巧:计算$e_{ij}=f(a_i)^Tf(b_j)$时,可以先分别计算$f(a_i)$和$f(b_j)$再聚合,而不是每次输入$a_i$和$b_j$。这样能将原本$mn$次函数$f$的计算转为$m+n$次函数$f$的计算。
比较:将一个序列中的词元与另一个序列进行比较
- 序列$A$中的第$i$个词元与序列$B$的比较结果:$v_{A,i}=g([a_i,\beta_i])$
- 序列$B$中的第$j$个词元与序列$A$的比较结果:$v_{B,j}=g([b_j,\alpha_j])$
- 其中$g$为多层感知机MLP
聚合:拼接对比后的结果,推断逻辑关系的分类结果
- 对比较向量进行求和,$v_A=\Sigma_{i=1}^mv_{A,i},v_B=\Sigma_{j=1}^nv_{B,j}$
- 拼接求和结果并进行分类预测,$\hat{y}=h([v_A,v_B])$,其中$h$为多层感知机MLP
基于PyTorch的注意力自然语言推断建模:
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
def mlp(num_inputs, num_hiddens, flatten):
net = []
net.append(nn.Dropout(0.2))
net.append(nn.Linear(num_inputs, num_hiddens))
net.append(nn.ReLU())
if flatten:
net.append(nn.Flatten(start_dim=1))
net.append(nn.Dropout(0.2))
net.append(nn.Linear(num_hiddens, num_hiddens))
net.append(nn.ReLU())
if flatten:
net.append(nn.Flatten(start_dim=1))
return nn.Sequential(*net)
class Attend(nn.Module):
def __init__(self, num_inputs, num_hiddens, **kwargs):
super(Attend, self).__init__(**kwargs)
self.f = mlp(num_inputs, num_hiddens, flatten=False)
def forward(self, A, B):
# A/B的形状:(批量大小,序列A/B的词元数,embed_size)
# f_A/f_B的形状:(批量大小,序列A/B的词元数,num_hiddens)
f_A = self.f(A)
f_B = self.f(B)
# e的形状:(批量大小,序列A的词元数,序列B的词元数)
e = torch.bmm(f_A, f_B.permute(0, 2, 1))
# beta的形状:(批量大小,序列A的词元数,embed_size),
# 意味着序列B被软对齐到序列A的每个词元(beta的第1个维度)
beta = torch.bmm(F.softmax(e, dim=-1), B)
# beta的形状:(批量大小,序列B的词元数,embed_size),
# 意味着序列A被软对齐到序列B的每个词元(alpha的第1个维度)
alpha = torch.bmm(F.softmax(e.permute(0, 2, 1), dim=-1), A)
return beta, alpha
class Compare(nn.Module):
def __init__(self, num_inputs, num_hiddens, **kwargs):
super(Compare, self).__init__(**kwargs)
self.g = mlp(num_inputs, num_hiddens, flatten=False)
def forward(self, A, B, beta, alpha):
V_A = self.g(torch.cat([A, beta], dim=2))
V_B = self.g(torch.cat([B, alpha], dim=2))
return V_A, V_B
class Aggregate(nn.Module):
def __init__(self, num_inputs, num_hiddens, num_outputs, **kwargs):
super(Aggregate, self).__init__(**kwargs)
self.h = mlp(num_inputs, num_hiddens, flatten=True)
self.linear = nn.Linear(num_hiddens, num_outputs)
def forward(self, V_A, V_B):
# 对两组比较向量分别求和
V_A = V_A.sum(dim=1)
V_B = V_B.sum(dim=1)
# 将两个求和结果的连结送到多层感知机中
Y_hat = self.linear(self.h(torch.cat([V_A, V_B], dim=1)))
return Y_hat
# 将注意步骤、比较步骤和聚合步骤组合在一起
class DecomposableAttention(nn.Module):
def __init__(self, vocab, embed_size, num_hiddens, num_inputs_attend=100,
num_inputs_compare=200, num_inputs_agg=400, **kwargs):
super(DecomposableAttention, self).__init__(**kwargs)
self.embedding = nn.Embedding(len(vocab), embed_size)
self.attend = Attend(num_inputs_attend, num_hiddens)
self.compare = Compare(num_inputs_compare, num_hiddens)
# 有3种可能的输出:蕴涵、矛盾和中性
self.aggregate = Aggregate(num_inputs_agg, num_hiddens, num_outputs=3)
def forward(self, X):
premises, hypotheses = X
A = self.embedding(premises)
B = self.embedding(hypotheses)
beta, alpha = self.attend(A, B)
V_A, V_B = self.compare(A, B, beta, alpha)
Y_hat = self.aggregate(V_A, V_B)
return Y_hat
# 读取数据
batch_size, num_steps = 256, 50
train_iter, test_iter, vocab = d2l.load_data_snli(batch_size, num_steps)
# 加载预训练模型-glove
embed_size, num_hiddens, devices = 100, 200, d2l.try_all_gpus()
net = DecomposableAttention(vocab, embed_size, num_hiddens)
glove_embedding = d2l.TokenEmbedding('glove.6b.100d')
embeds = glove_embedding[vocab.idx_to_token]
net.embedding.weight.data.copy_(embeds);
# 训练和评估
lr, num_epochs = 0.001, 4
trainer = torch.optim.Adam(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss(reduction="none")
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,
devices)
# loss 0.495, train acc 0.805, test acc 0.823
# 18922.8 examples/sec on [device(type='cuda', index=0), device(type='cuda', index=1)]
#@save
def predict_snli(net, vocab, premise, hypothesis):
"""预测前提和假设之间的逻辑关系"""
net.eval()
premise = torch.tensor(vocab[premise], device=d2l.try_gpu())
hypothesis = torch.tensor(vocab[hypothesis], device=d2l.try_gpu())
label = torch.argmax(net([premise.reshape((1, -1)),
hypothesis.reshape((1, -1))]), dim=1)
return 'entailment' if label == 0 else 'contradiction' if label == 1 \
else 'neutral'
predict_snli(net, vocab, ['he', 'is', 'good', '.'], ['he', 'is', 'bad', '.']) # 'contradiction'
6 针对序列级和词元级应用程序微调BERT
BERT的输入:
- 兼容单文本序列和两个文本序列(文本对)情况
- 内置了特殊占位符
<cls>实现对整个输入文本的嵌入表示
不同类型的下游任务的BERT微调:
- 对于单文本分类/回归任务,只需在特殊占位符
<cls>后添加额外的全连接层 - 对于文本对分类/回归任务(比如文本推断、相似度计算 ),方法同单文本的情况
- 对于文本标注的情况,每个词元都会输出预测标签,微调BERT需要在每个词元的最终表示后添加一个额外的全连接层,不同词元表示后的全连接层是参数共享的
- 对于文本问答的情况,此时输入的文本对是“问题”和“文章”,BERT微调时需在“文章”对应的每个词元最后添加额外的全连接层,预测输出“答案”在“文章”中的位置
补充说明:微调BERT时,额外的全连接层参数会从头开始学习。而其他参数可以进行微调,也可以固定(不固定一般来说效果会更好,固定前几层训练速度会更快)。一般来说多个额外的全连接层参数会是参数共享的
7 自然语言推断:微调BERT
基于PyTorch的微调BERT自然语言推断建模:
import json
import multiprocessing
import os
import torch
from torch import nn
from d2l import torch as d2l
# bert.base计算成本高 bert.small便于演示
# d2l.DATA_HUB['bert.base'] = (d2l.DATA_URL + 'bert.base.torch.zip',
# '225d66f04cae318b841a13d32af3acc165f253ac')
d2l.DATA_HUB['bert.small'] = (d2l.DATA_URL + 'bert.small.torch.zip',
'c72329e68a732bef0452e4b96a1c341c8910f81f')
def load_pretrained_model(pretrained_model, num_hiddens, ffn_num_hiddens,
num_heads, num_layers, dropout, max_len, devices):
data_dir = d2l.download_extract(pretrained_model)
# 定义空词表以加载预定义词表
vocab = d2l.Vocab()
vocab.idx_to_token = json.load(open(os.path.join(data_dir,
'vocab.json')))
vocab.token_to_idx = {token: idx for idx, token in enumerate(
vocab.idx_to_token)}
bert = d2l.BERTModel(len(vocab), num_hiddens, norm_shape=[256],
ffn_num_input=256, ffn_num_hiddens=ffn_num_hiddens,
num_heads=4, num_layers=2, dropout=0.2,
max_len=max_len, key_size=256, query_size=256,
value_size=256, hid_in_features=256,
mlm_in_features=256, nsp_in_features=256)
# 加载预训练BERT参数
bert.load_state_dict(torch.load(os.path.join(data_dir,
'pretrained.params')))
return bert, vocab
devices = d2l.try_all_gpus()
bert, vocab = load_pretrained_model(
'bert.small', num_hiddens=256, ffn_num_hiddens=512, num_heads=4,
num_layers=2, dropout=0.1, max_len=512, devices=devices)
class SNLIBERTDataset(torch.utils.data.Dataset):
def __init__(self, dataset, max_len, vocab=None):
all_premise_hypothesis_tokens = [[
p_tokens, h_tokens] for p_tokens, h_tokens in zip(
*[d2l.tokenize([s.lower() for s in sentences])
for sentences in dataset[:2]])]
self.labels = torch.tensor(dataset[2])
self.vocab = vocab
self.max_len = max_len
(self.all_token_ids, self.all_segments,
self.valid_lens) = self._preprocess(all_premise_hypothesis_tokens)
print('read ' + str(len(self.all_token_ids)) + ' examples')
def _preprocess(self, all_premise_hypothesis_tokens):
pool = multiprocessing.Pool(4) # 使用4个进程(数据预处理需要赶上训练速度)
out = pool.map(self._mp_worker, all_premise_hypothesis_tokens)
all_token_ids = [
token_ids for token_ids, segments, valid_len in out]
all_segments = [segments for token_ids, segments, valid_len in out]
valid_lens = [valid_len for token_ids, segments, valid_len in out]
return (torch.tensor(all_token_ids, dtype=torch.long),
torch.tensor(all_segments, dtype=torch.long),
torch.tensor(valid_lens))
def _mp_worker(self, premise_hypothesis_tokens):
p_tokens, h_tokens = premise_hypothesis_tokens
self._truncate_pair_of_tokens(p_tokens, h_tokens)
tokens, segments = d2l.get_tokens_and_segments(p_tokens, h_tokens)
token_ids = self.vocab[tokens] + [self.vocab['<pad>']] \
* (self.max_len - len(tokens))
segments = segments + [0] * (self.max_len - len(segments))
valid_len = len(tokens)
return token_ids, segments, valid_len
def _truncate_pair_of_tokens(self, p_tokens, h_tokens):
# 为BERT输入中的'<CLS>'、'<SEP>'和'<SEP>'词元保留位置
while len(p_tokens) + len(h_tokens) > self.max_len - 3:
if len(p_tokens) > len(h_tokens):
p_tokens.pop()
else:
h_tokens.pop()
def __getitem__(self, idx):
return (self.all_token_ids[idx], self.all_segments[idx],
self.valid_lens[idx]), self.labels[idx]
def __len__(self):
return len(self.all_token_ids)
# 如果出现显存不足错误,请减少“batch_size”。在原始的BERT模型中,max_len=512
batch_size, max_len, num_workers = 512, 128, d2l.get_dataloader_workers()
data_dir = d2l.download_extract('SNLI')
train_set = SNLIBERTDataset(d2l.read_snli(data_dir, True), max_len, vocab)
test_set = SNLIBERTDataset(d2l.read_snli(data_dir, False), max_len, vocab)
train_iter = torch.utils.data.DataLoader(train_set, batch_size, shuffle=True,
num_workers=num_workers)
test_iter = torch.utils.data.DataLoader(test_set, batch_size,
num_workers=num_workers)
class BERTClassifier(nn.Module):
def __init__(self, bert):
super(BERTClassifier, self).__init__()
self.encoder = bert.encoder
self.hidden = bert.hidden
self.output = nn.Linear(256, 3)
def forward(self, inputs):
tokens_X, segments_X, valid_lens_x = inputs
encoded_X = self.encoder(tokens_X, segments_X, valid_lens_x)
return self.output(self.hidden(encoded_X[:, 0, :]))
net = BERTClassifier(bert)
lr, num_epochs = 1e-4, 5
trainer = torch.optim.Adam(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss(reduction='none')
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,
devices)
# loss 0.520, train acc 0.790, test acc 0.784
# 10573.7 examples/sec on [device(type='cuda', index=0), device(type='cuda', index=1)]