中文标题:一个适用于结构化输入与输出的通用架构
英文标题:Perceiver IO: A General Architecture for Structured Inputs & Outputs
发布平台:ICLR
发布日期:2022-03-15
引用量(非实时):380
DOI:
作者:Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, Joāo Carreira
关键字: #Perceiver #多模态
文章类型:preprint
品读时间:2023-12-21 16:50
1 文章萃取
1.1 核心观点
本文提出了一种适用于多模态学习的通用框架—— Perceiver IO 可以处理任意格式的输入数据,同时模型复杂度仅随输入和输出的大小线性扩展。Perceiver IO 通过灵活的查询机制进行能力增强,同时以编码器-解码器结构为底层结构,支持不同尺度和语义的输出,消除了过往模型中对特定任务或模态的架构组件/工程的需求
Perceiver IO 使用一套相同的架构在自然语言、视觉理解、多任务和多模式推理以及《星际争霸Ⅱ》等任务上取得了出色的成果。在 GLUE 语言基准测试中表现优于 BERT 基线,在 Sintel 光流基准测试上实现了最先进的性能,在音视频分类编码等多模态(音频+视频+文本标签)测试中也表现出色
1.2 综合评价
- 提出了一种通用而高效的多模态解决方案,对输入/输出的格式限制少
- 简化了复杂神经网络的构建过程,并发挥了多任务/多模态的互补优势
- 在实际表现中仅略高于单任务/单模态的情况,但具备较大的挖掘潜力
1.3 主观评分:⭐⭐⭐⭐⭐
2 精读笔记
2.1 背景知识
Perceiver 架构:
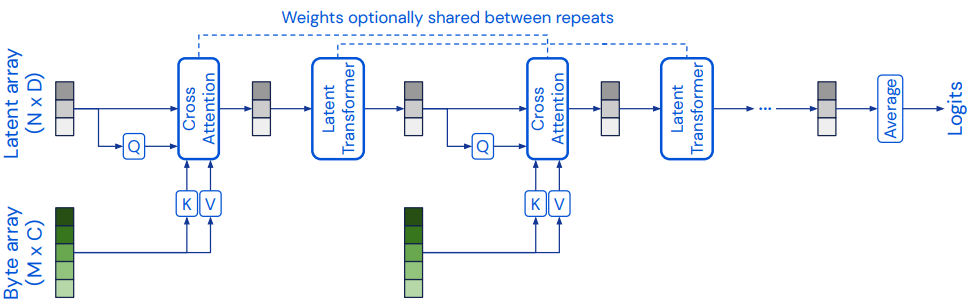
- Perceiver 通过将输入假设为简单的字节数组(byte array,可以是图像、音视频、文本、点云、某种形式的嵌入等)实现了跨模态的通用性,最终输出为分类标签
- Perceiver 先利用交叉注意力(Cross Attention) 将字节数组投影到固定维度(超参数,一般会比输入维度小很多)的潜空间,实现不同源信息的交流;
- 之后 Perceiver 再通过 Latent Transformer(原论文使用了 GPT-2 的架构和自注意力机制)来解耦模型深度与输入尺寸间的关系,并进行特征信息的深入加工和理解;
- 迭代重复以上过程多次(通过参数共享以提高参数效率并减少运算成本,实现了类似于 RNN 的功能结构)后,Perceiver 实现最终隐特征的提取
Perceiver IO 是 Perceiver 的泛化,除了处理任意输入之外,还可以处理任意输出。比如分类、语言生成、音视频、游戏操作(星战 2)

2.2 算法细节
Perceiver IO 架构:
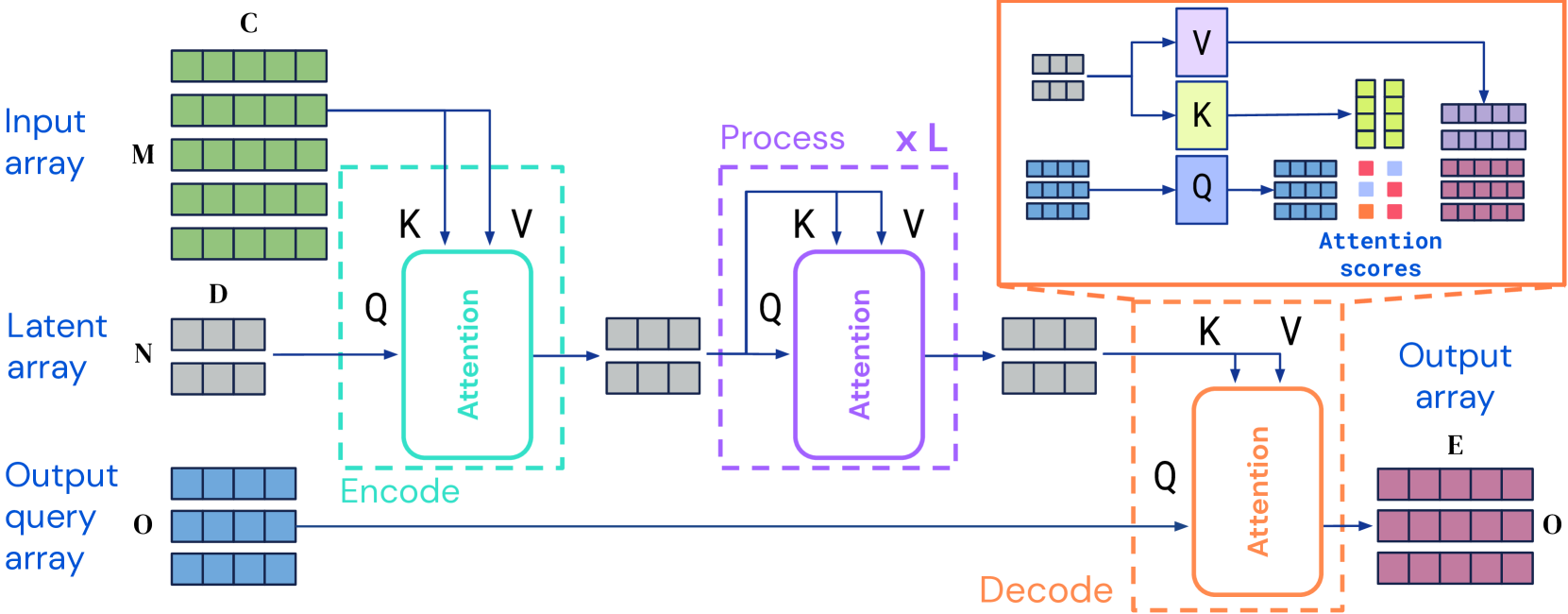
- Perceiver IO 在 Perceiver 的基础上增加了解码器结构,以增强其输出的多样性
- 编码器部分:模型借助 Transformer 注意机制对输入数组的进行初步的信息编码,之后重复迭代这一过程 L 次(权重共享),最终结果为维度较小的潜在特征向量
- 解码器部分:综合考虑期望的输出及其类型,对潜在特征向量进行解码
- Perceiver IO 的编码器和解码器的每个模块都接受两个输入数组,第一个用作模块的键和值网络的输入(K,V),第二个用作模块的查询网络的输入 (Q); 注意力计算后接一个多层感知器(MLP),模块的输出与查询输入具有相同的索引维度
Perceiver IO 使用了完全不同的非均匀注意力机制,首先将输入映射到隐空间,而后在隐空间中进一步处理,并最终映射到输出空间中去。
这使得模型的计算量不再依赖于输入输出的维度。编码器和解码器模块和注意力模块都线性依赖于输入和输出大小,而潜在向量独立于输入和输出大小(潜在向量维度一般远小于输入输出维度);该结构能大幅减小了计算开销,并将输入和输出拓展到更多维度
Perceiver IO 根据不同的任务类型来进行解码:
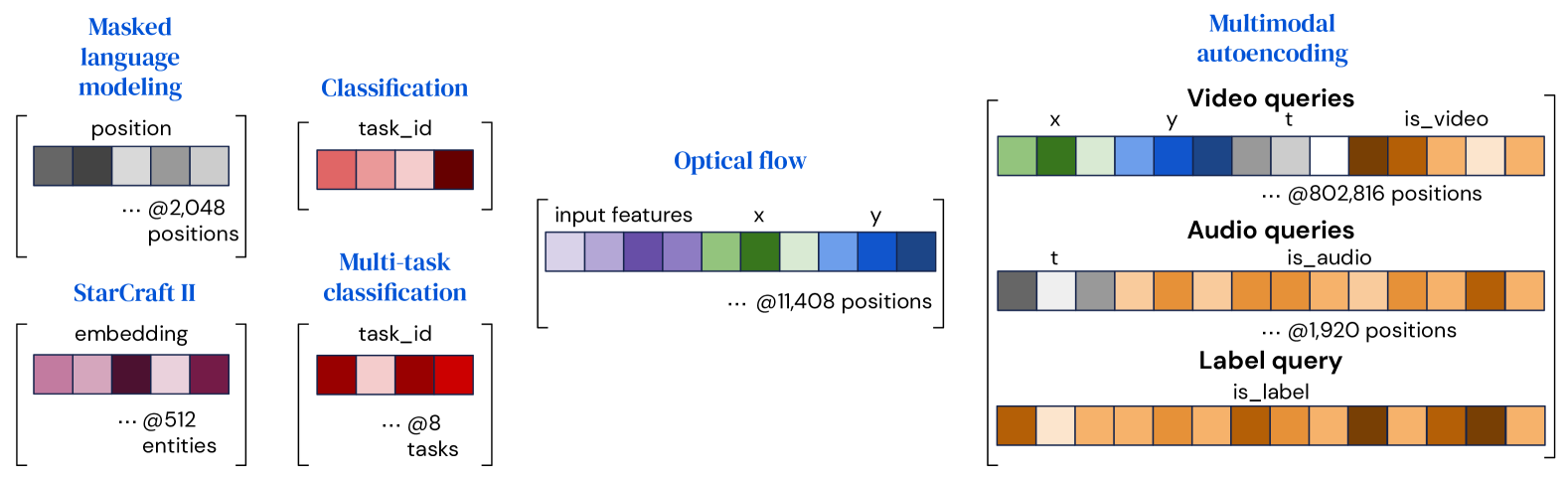
- Perceiver IO 通过将一组向量组合(串联或添加)为一个查询向量来构建查询,该查询包含与输出类型和维度相关的所有信息
- 对于简单任务(比如分类),该查询既可以在不同示例中复用,也可以重新学习
- 对于多模态任务,Perceiver IO 会针对每种多模态或任务学习对应的独立查询向量
- 对于其他任务,Perceiver IO 的输出需要能反应查询位置对应的输入内容
- 每个样本的输出都仅取决于查询向量和潜在特征,所以可以并行解码输出
2.3 实验分析
GLUE 语言理解基准测试:
| Model | Tokenization | M | N | Depth | Params | FLOPs | SPS | Avg. |
|---|---|---|---|---|---|---|---|---|
| BERT Base (test) | SentencePiece | 512 | 512 | 12 | 110M | 109B | - | 81.0 |
| BERT Base (ours) | SentencePiece | 512 | 512 | 12 | 110M | 109B | 7.3 | 81.1 |
| Perceiver IO Base | SentencePiece | 512 | 256 | 26 | 223M | 119B | 7.4 | 81.2 |
| BERT (matching FLOPs) | UTF-8 bytes | 2048 | 2048 | 6 | 20M | 130B | 2.9 | 71.5 |
| Perceiver IO | UTF-8 bytes | 2048 | 256 | 26 | 201M | 113B | 7.6 | 81.0 |
| Perceiver IO++ | UTF-8 bytes | 2048 | 256 | 40 | 425M | 241B | 4.2 | 81.8 |
- 其中 $M$ 表示输入维度,$N$ 表示潜在特征维度,$SPS$ 表示每秒训练步数据
- $Avg.$ 表示平均结果表现,可以发现 Perceiver IO 模型整体表现略优于 BERT,同时克服了 BERT 对序列长度的限制(在 M=2048 时的表现更好)
- 具体来说,本文的模型评价在 STS-B(语义文本相似性) 任务上使用 Pearson 相关性,在 CoLa(语法合规性) 上使用 Matthews 相关性,在其余任务上使用准确性
Perceiver IO 模型在多任务查询中的表现优于单任务:
| Method | Avg. |
|---|---|
| Single-task query | 81.0 |
| Multitask | |
| Shared input token | 81.5 |
| Task-specific input tokens | 81.8 |
| Multitask query | 81.8 |
Shared input token表示在任务间共享输入的 tokenTask-specific input tokens表示使用类似 BERT 的[CLS]tokenMultitask query使用特定于任务的输入 token,即本文所用方法;该方法相比于第二种,不依赖额外的[CLS]token,具备更好的通用能力和泛化性
Perceiver IO 模型在光流任务中略好于其他模型:
| Network | Sintel.clean | Sintel.final | KITTI |
|---|---|---|---|
| PWCNet (Sun et al., 2018) | 2.17 | 2.91 | 5.76 |
| RAFT (Teed & Deng, 2020) | 1.95 | 2.57 | 4.23 |
| Perceiver IO | 1.81 | 2.42 | 4.98 |
- PWCNet 和 RAFT 是两种光流问题中的主流 baseline 模型
- Sintel. Clean、Sintel. Final、KITTI 是常见的光流问题测试集
- 该任务的评价指标为平均终点误差 (EPE), 值越低越好
多模态自动编码(重建多模态输入):

- 在保持 88 倍的压缩比例的情况,Perceiver IO 实现了较好的多模态输入重建
其他结论:
- 在 ImageNet 上,预训练的 Perceiver IO 在不使用 2D 卷积的情况下超过了 80% top-1 准确率
- 在替换 AlphaStar 的实体 Transformer 后,Perceiver IO 仅经过 3 次实验运行,就获得了 ∼3.5× FLOP 的减少,同时保持了《星际争霸Ⅱ》87% 的胜率和参数计数
- 在 AudioSet 上,在多模态视频+音频分类上,Perceiver IO 始终优于原始 Perceiver
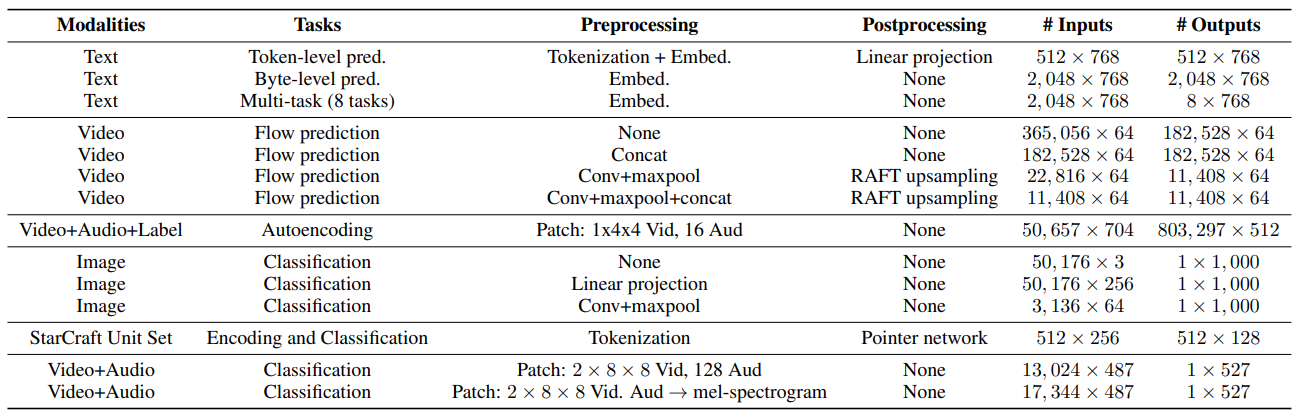
补充:用于评估 Perceiver IO 的任务细节
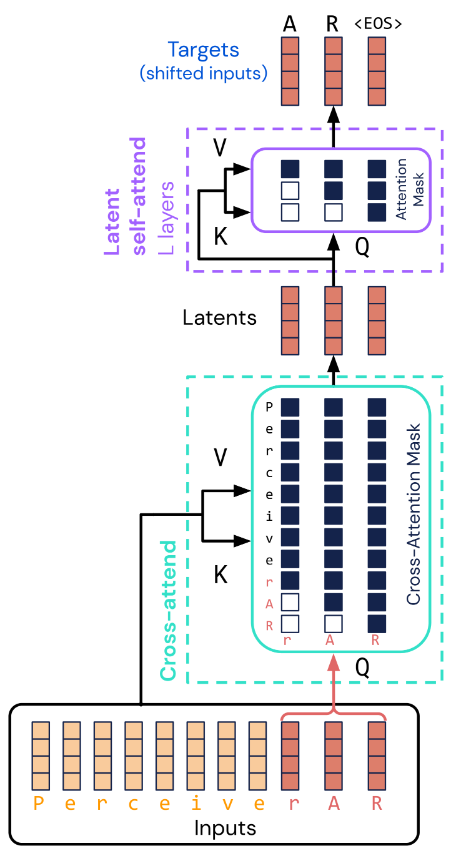
3 后续:Perceiver AR
Perceiver AR 在 Perceiver IO 的基础上引入了因果掩码和自回归的机制:
- 通过使用单个输出元素识别每个潜在变量来引入对潜在变量的排序
- 使用交叉注意力将远程输入映射到少量潜在变量,同时保持端到端因果屏蔽
- 使用因果屏蔽交叉注意来确保每个潜在变量仅关注其之前的输入元素按顺序
- 以自回归方式进行解码输出,同时保留 Perceiver 架构的计算和内存优势
- 每个输出都以所有先前的输入为条件,因此该架构能够很好地捕获远程依赖性
- 最终 Perceiver AR 在 ImageNet 和 Project Gutenberg 密度估计任务上获得了最先进的结果,并在几个具有挑战性的生成任务(图像、象征性音乐和音频)中表现出色