1 基本介绍
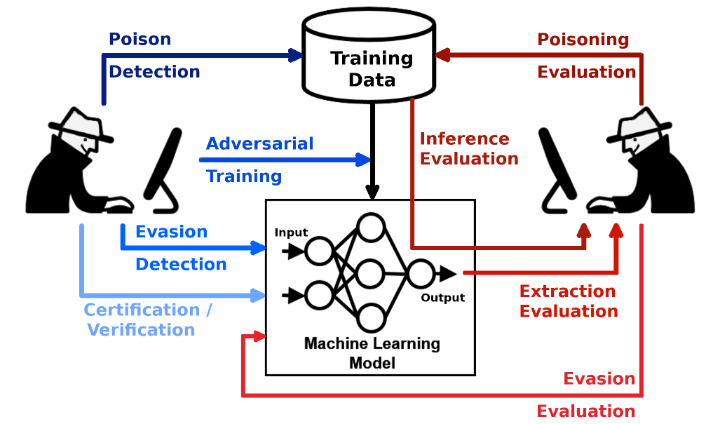
对抗性鲁棒性工具集(Adversarial Robustness Toolbox,ART)是用于机器学习安全性的Python库
- 从逃逸,数据污染,模型提取和推断的对抗性威胁等方面捍卫和评估模型
- 适用广泛,支持所有常见的数据类型、机器学习任务、机器学习框架
本项目由IBM团队在2019年开源。项目文档不是特别完善,但是示例丰富,API设计扁平,所以上手难度也不算太高。还需要注意的是虽然本项目一直活跃维护,但目前所实现的算法多集中在2016~2020年,
2 核心架构
ART项目主要包含五个子模块(攻击,防御,估计器,度量和预处理)
官方的文档里写了六个,但根据代码来看,评估(evaluations)模块已经弃用了
2.1 攻击(attacks)
ART已实现的四种攻击方式:
- 逃避(Evasion)攻击:操纵输入数据使得机器学习系统中产生误判(比如在图像中加入肉眼不可见的噪声),根据被攻击模型的参数是否可知,逃避攻击还可以分为黑盒攻击与白盒攻击
- 投毒(Poisoning)攻击:在训练阶段注入错误标记的样本(也是实际场景中最常见的数据问题)
- 提取(Extraction)攻击:通过访问在线模型,实现相似模型的本地复刻(类似于未经许可的模型蒸馏)
- 推理(Inference)攻击:判断某一个数据记录是否在模型的训练集中(主要关乎到数据隐私性的问题)
关于攻击方式的更多细节和论文实现可参阅项目的官方wiki-攻击
2.2 防御(defences)
ART已实现的五种攻击方式:
- 检测(Detector)防御:主要通过制定检测的方式防御攻击,常用于应对逃避/投毒攻击
- 后处理(Postprocessor)防御:常用的后处理方式包括类别修正、添加噪声、高置信度预测等
- 预处理(Preprocessor)防御:常用的预处理方式包括数据增强、特征压缩、标签平滑等
- 训练(Trainer)防御:主动添加攻击或数据增强进行对抗性训练,增强模型稳健性
- 转换(Transformer)防御:修正模型以提高安全性,比如防御性模型蒸馏、识别和去除后门等
关于防御方式的更多细节和论文实现可参阅项目的官方wiki-防御
2.3 估计器(Estimators)
ART已实现的八种常见的估计器:分类(Classification)、目标检测(Object Detection)、目标追踪(Object Tracking)、语音识别(Speech Recognition)、鲁棒性增强(Certification)、编码器(Encoding)、生成器(Generation)、回归(Regression)
2.4 度量(Metrics)
ART内置了多个用于评估模型鲁棒性、敏感性和隐私性的指标
2.5 预处理(preprocessing)
ART内置了数据标准化、音频预处理、图像预处理等辅助工具
本项目中的算法基本都是对优秀论文的复现,其中很多论文很值得读一读 #待补充
3 官方示例
针对不同框架(scikit-learn,LightGBM,PyTorch等)的入门示例可参阅:Get Started with ART
以scikit-learn为例,对应示例代码如下:
from sklearn.svm import SVC
import numpy as np
from art.attacks.evasion import FastGradientMethod
from art.estimators.classification import SklearnClassifier
from art.utils import load_mnist
# Step 1: Load the MNIST dataset
(x_train, y_train), (x_test, y_test), min_pixel_value, max_pixel_value = load_mnist()
# Step 1a: Flatten dataset
nb_samples_train = x_train.shape[0]
nb_samples_test = x_test.shape[0]
x_train = x_train.reshape((nb_samples_train, 28 * 28))
x_test = x_test.reshape((nb_samples_test, 28 * 28))
# Step 2: Create the model
model = SVC(C=1.0, kernel="rbf")
# Step 3: Create the ART classifier
classifier = SklearnClassifier(model=model, clip_values=(min_pixel_value, max_pixel_value))
# Step 4: Train the ART classifier
classifier.fit(x_train, y_train)
# Step 5: Evaluate the ART classifier on benign test examples
predictions = classifier.predict(x_test)
accuracy = np.sum(np.argmax(predictions, axis=1) == np.argmax(y_test, axis=1)) / len(y_test)
print("Accuracy on benign test examples: {}%".format(accuracy * 100))
# Step 6: Generate adversarial test examples
attack = FastGradientMethod(estimator=classifier, eps=0.2)
x_test_adv = attack.generate(x=x_test)
# Step 7: Evaluate the ART classifier on adversarial test examples
predictions = classifier.predict(x_test_adv)
accuracy = np.sum(np.argmax(predictions, axis=1) == np.argmax(y_test, axis=1)) / len(y_test)
print("Accuracy on adversarial test examples: {}%".format(accuracy * 100))
更多进阶用法可参阅官方ipynb格式的notebook示例