- SOTA模型基准测试 vs 人类的表现
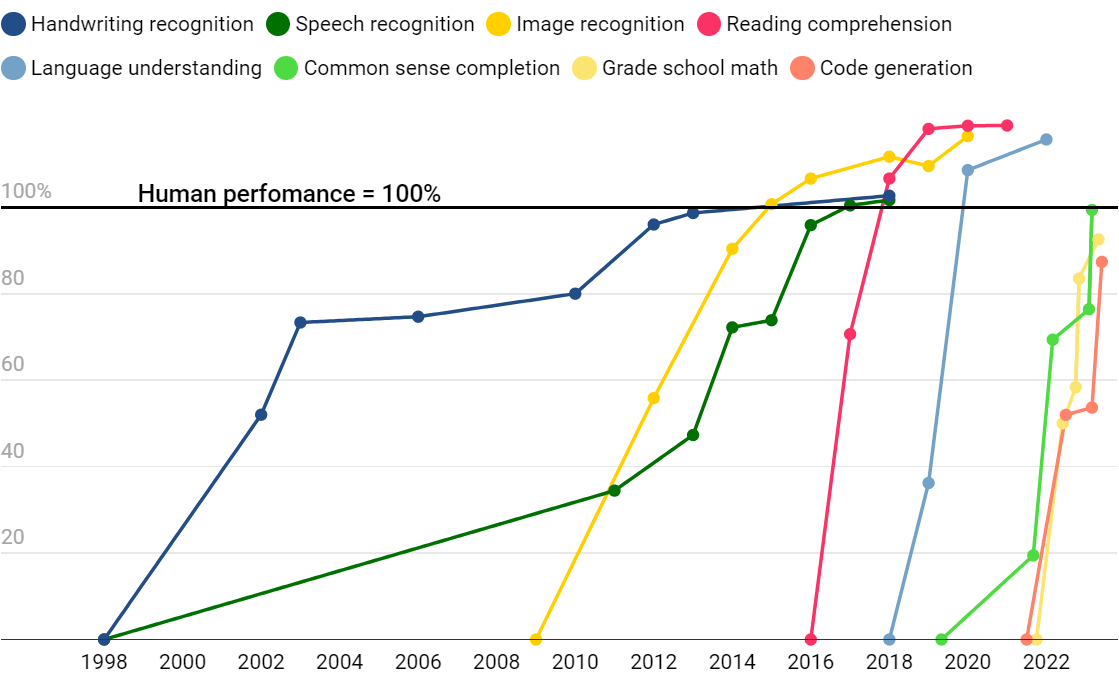
- 手写识别(MNIST)、语音识别(Switchboard)、图像识别(ImageNet)、阅读理解(SQuAD 1.1 & SQuAD 2.0)、语言理解(GLUE)、常识完成(HellaSwag)、小学数学(GSK8k)、代码生成(HumanEval)
- 训练AI模型的算力需求趋势
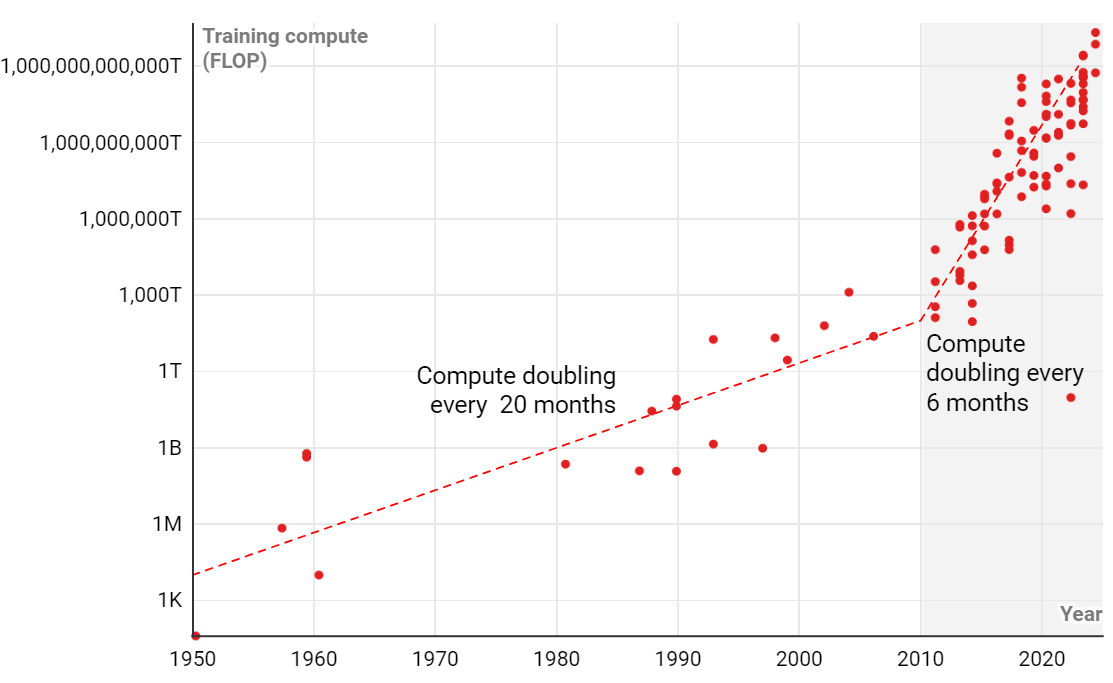
- 2010年以前,用于AI训练的算力每 20 个月翻一倍;2010年以后,算力每 6 个月翻一倍
- 摩尔定律(集成电路中的晶体管数量大约每两年翻一番)意味着算力的价格一直在稳步下降
- 据OpenAI CEO Sam Altman透露,GPT-4的训练成本超过了1亿美元
- 训练AI模型的数据量需求趋势
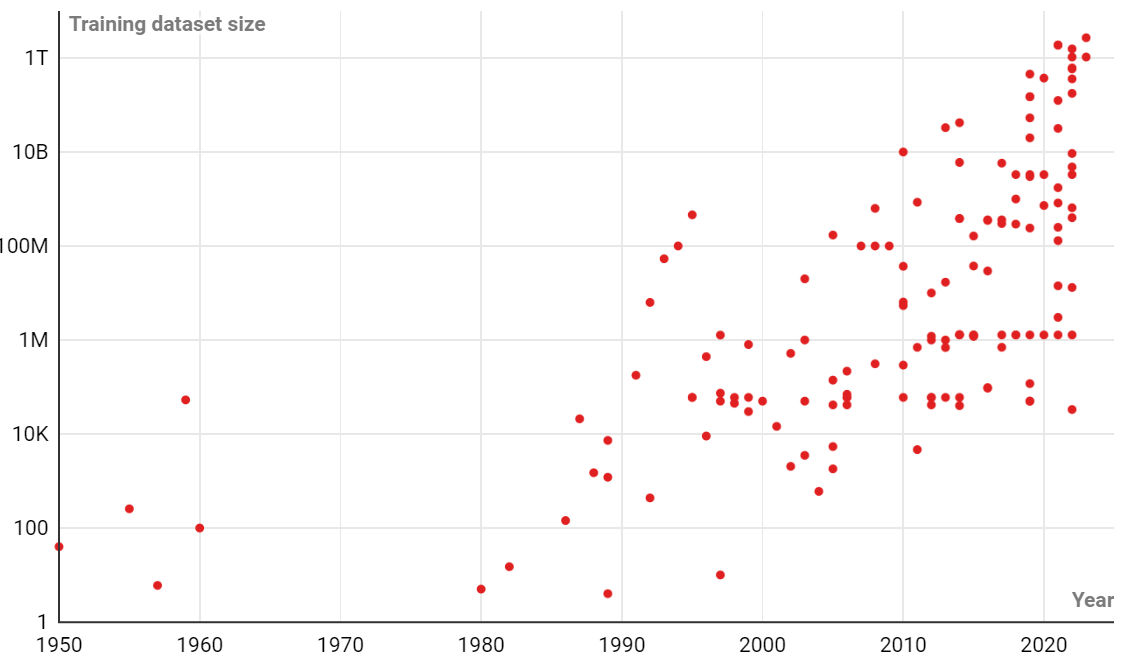
- 训练数据大小是指用于训练AI模型的数据量,表示可供模型学习的示例数
- 由Meta在2023年发布的大语言模型LLaMA,则使用了约10亿个数据点进行训练
- 在图像识别测试中达到 80.9% 的准确度所需的计算量和数据点数
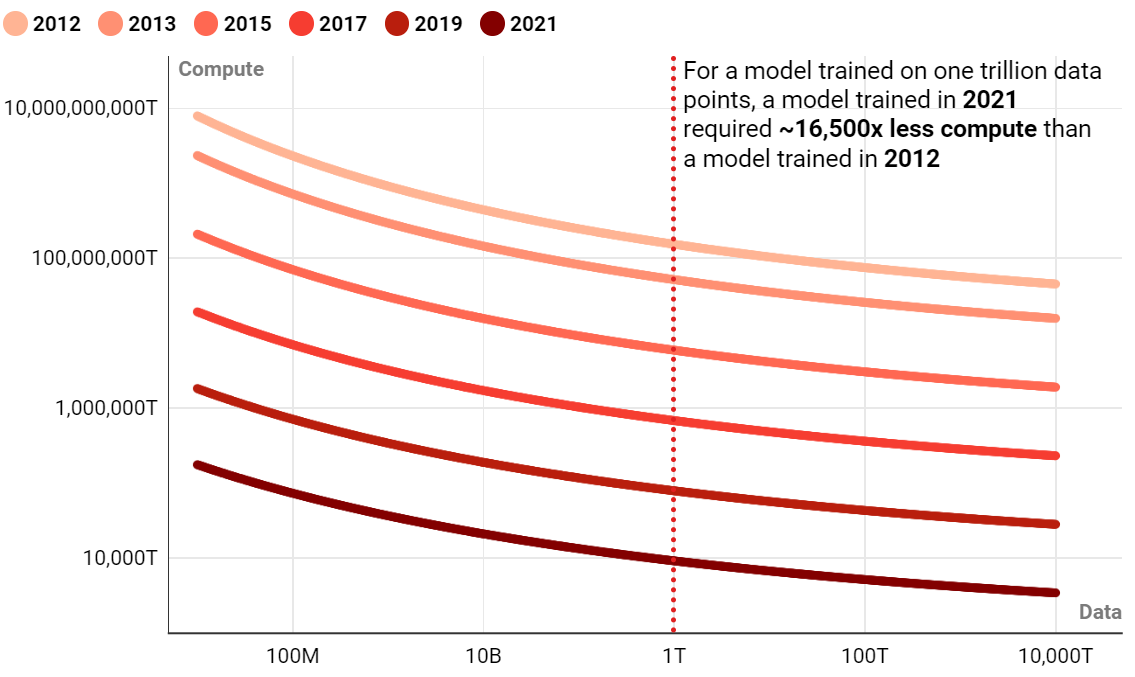
- 2021年训练的模型所需的计算量比2012年训练的模型少~16,500倍
未来趋势:
- 训练AI模型所需的计算量在未来一段时间内会保持目前的加速度增长
- 目前训练AI模型所需的数据量增长,已经超过了互联网上新文本数据的生产速度;预估到2026年,AI开发人员将耗尽高质量的语言数据;数据不足目前并没有成为AI发展的瓶颈
- 过去超过四分之三的算法进步,都是被用来弥补计算的不足(追求更高效地利用算力);未来,随着数据成为AI训练发展的瓶颈,可能会有更多的算法改进,被用来弥补数据上的不足
- 考虑到资金的大量投入、算力的增长、算力成本的进一步降低、剩余的高质量数据、持续的算法改进;未来几年,AI发展将继续保持高速的增长
参考
TIME - 4 Charts That Show Why AI Progress Is Unlikely to Slow Down