中文标题:基于知识图谱的约束问答
英文标题:Constraint-Based Question Answering with Knowledge Graph
发布平台:COLING
发布日期:2016-12-01
引用量(非实时):214
DOI:缺失
作者:Junwei Bao, Nan Duan, Zhao Yan, Ming Zhou, Tiejun Zhao
文章类型:conferencePaper
品读时间:2022-09-07 13:43
1 文章萃取
1.1 核心观点
针对传统知识问答数据集中大部分问题过于简单的情况,本文提出了一个新的QA数据集ComplexQuestions,旨在评价KBQA系统在多约束问题上的表现。同时本文基于将多约束问题(MulCQ)转化为多约束查询图(MulCG)的思路,提出了一种新的解决多约束问题的KBQA方案,并在最后的实验分析中取得了较好的表现。
1.2 综合评价
- 本文涉及的前置知识较多,但流程清晰,内容丰富
- 存在多处人为的规则设定,最终表现仍存在较大改进空间
- 分享了一个新的QA数据集,具备一个完整的约束问答流程
1.3 主观评分:⭐⭐⭐⭐
2 精读笔记
2.1 构建数据集
传统知识问答(KBQA)的基准数据库为 WebQuestions 和 SimpleQuestions。但这份数据中有85%的问题都属于简单问题,即通过一个知识三元组便能够回答
复杂问答常见情况与举例:
- 多实体约束(30.6%):由张艺谋执导,并且还有葛优参演的那个电影叫啥?
- 类型约束(38.8%):大思想家马克思出生在哪个城市?
- 显式时间约束(10.4%):2008年的时候,美国总统是谁啊?
- 隐式时间约束(3.5%):北京办奥运会那年,美国总统是谁啊?
- 次序约束(5.1%):中国第二长的河是那一条?
- 聚合约束(1.2%):中国总共有多少个直辖市啊?
多约束QA数据集构建
- 从真实搜索引擎抽取三个月日志(2015.1.1-2015.4.1),约有2100w个5W1H问题
- 问题的筛选:不包含代词(带“you”,"my"等代词的问题多为非事实描述问题),单词数在7~20之间(过长的问题难以回答),随即筛选剩余的10%,并剔除未检测到实体的问题
- 从WebQuestions 和 SimpleQuestions中抽取单词,排除实体词和停用词后构建词典,保留包含词典中单词的问题(使得筛选后的问题和前两个开源QA数据集尽量保持一致)
- 以上过程最终筛选出878条数据,并基于 FreeBase 进行人工标注。再结合来自 WebQuestions 中筛选出的924条已标注数据,以及300条来自另一个团队开源的复杂语义约束QA数据
- 本文最终开源的数据集ComplexQuestions,共包含2100条数据(训练集1300,测试集800)
5W1H:what、where、when、who、which、how
不同类型的QA标注规则:
- 多实体约束(30.6%):至少包含两个非重叠实体
- 类型约束(38.8%):包含来自Freebase的类型短语
- 显式时间约束(10.4%):能通过NER检测到时间表达式
- 隐式时间约束(3.5%):包含关键词”when“、”before“、”after“、”during“
- 次序约束(5.1%):包含来自WordNet中的序数或最高级(the most)短语
- 聚合约束(1.2%):以”how many“开头或包含关键词”number of“或”count of“
2.2 多约束查询图
知识图谱$K$中存在很多事实,每个事实$t$为一个知识三元组$<s,p,o>$
多约束查询图(Multi-Constraint Query Graph,MulCG)的四个基本元素:
- 顶点(Vertex):分为常量型顶点(用矩阵表示)和变量型顶点(用圆形表示)
- 边(Edge):分为关系型和函数型,其中函数型主要包括Equal(等于)、<(小于)、>(大于)、MaxAtN(次序,降序排列)、MinAtN(次序,升序排列)、Count(计数)
- 基本查询图(Basic Query Graph):定义为三元组$<v_s,p,v_o>$,其中$v_s$表示问题中出现的常量型顶点(主题),$v_o$表示问题对应的隐含答案(变量型顶点,用带阴影的圆形表示),$p$表示$v_s$到$v_o$之间的路径(包含1~2条边)
- 约束(Constraint):定义为三元组$<v_s,r_,v_o>$,其中$r$表示函数型边
注意,当$p$包含2条边时,2边之间必然包含一个CVT实体。CVT(compound value type),即复合值类型,它是一种特殊的实体类型,用于表示复杂的数据,以涵盖一条数据的多种可能(比如一个城市的人口数,是随时间变化的),此概念来自Freebase(个人还不是很理解这个CVT的必然性)
MulCG示例 :
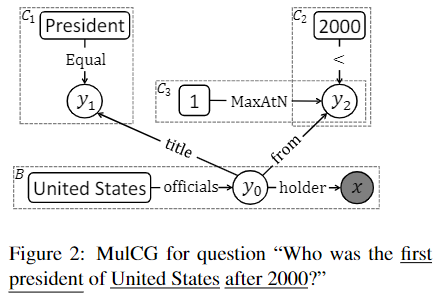
- 上图中$B$表示基本查询图,$C_1,C_2,C_3$表示三种约束
2.3 实现多约束查询
多约束查询的解决思路:
- 给定多约束问题($MulCQ$,简称$Q$)和知识图谱(简称$K$)
- 先根据问题找到所有可能的基础(候选)查询图$MulCGs$
- 再检测问题中的约束,通过约束绑定将基础查询图转化为多约束查询图$G$
- 之后针对每个多约束查询图$G\in H(Q)$,通过$CNN$模型抽取特征向量$F(Q,G)$
- 依次计算每个$MulCG$的特征向量与$MulCQ$的特征向量的余弦相似度
- 找到语义相似度最高的$MulCG$,其对应的答案$A$就是$MulCQ$的答案
2.3.1 生成基础查询图
前置知识:基于树模型的结构化实体识别算法 S-MART
- S-MART在MART算法(又称GBDT算法,通过不断拟合残差的方式构建多个弱学习器并进行集成)基础上进行了改进,并结合了TreeCRF对序列标注问题进行针对性优化
- S-MART算法具备很强的通用性,也适用于各种形式的损失函数
- S-MART算法使用非线性回归树来捕捉特征间的高阶关系,模型拟合能力出色
- 关于算法的更多细节可参阅S-MART算法论文原文和TreeCRF算法论文原文
生成基础查询图:
- 使用S-MART算法检测给定问题中的所有实体
- 每个实体都可以看作一个常量型顶点(主题),简称$s$
- 遍历每个$s$的所有可能路径(仅考虑一跳和二跳)
- 对于一跳的情况,最终的基础查询图为$<s,p_0,x>$
- 对于二跳的情况,最终的基础查询图为$<s,p_1-y_{cvt}-p_2,x>$
- 其中$y_{cvt}$表示CVT实体对应的节点,$x$表示答案对应的节点
2.3.2 语义相似度评估
如何根据原始问题找到与之最匹配的查询图?如何根据谓语描述找到与之最匹配的边?
本文根据”双塔模型“的思想,提出了一种孪生CNN网络,用于评估文本(主谓宾)与查询图(节点/边)之间的相似度,进而找到最合适的查询图用于寻找问题的答案:
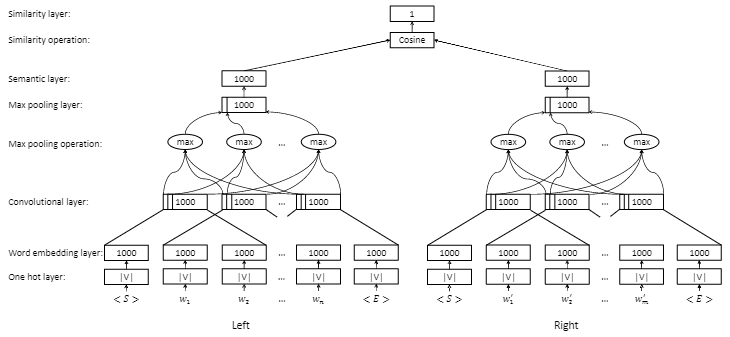
- 两个文本序列分别输入左右两个模型,并通过嵌入层将one-hot矩阵转化为词向量
- 词向量经过卷积-池化层完成特征的抽象,左右分别形成两组特征向量
- 两个序列的最终相似度等于序列对应特征向量的余弦相似度
根据输入序列的不同,孪生CNN网络可以进行不同角度的相似度描述。既可以评估文本中的实体与查询图中节点的相似度,也可以评估文本中的实体关系与查询图中边的相似度,还可以评估问题文本与多约束查询图的整体相似度。
2.3.3 约束检测与绑定
约束类型主要包括以下六种: 多实体约束、类型约束、显式时间约束、隐式时间约束、次序约束、聚合约束。
实现约束主要靠以下六种边函数:Equal(等于)、<(小于)、>(大于)、MaxAtN(次序,降序排列)、MinAtN(次序,升序排列)、Count(计数)
前置知识:抽取文本中的类型词
- 在论文《基于Freebase的结构化信息抽取与问题回答》中,作者提出了四种“问题词”、“问题焦点”、“问题动词”和“问题主题”这四个概念
- 问题词(question word,简称qword)主要包括九种:who、when、what、where、how、which、why、whom、whose
- 问题焦点(question focus,简称qfocus)主要用于提示期望答案的类型, 一个比较简单的规则,是将依赖于“问题词”的名词视为问题焦点,即实现类型词的抽取
- 对于后两个概念和其他细节可参阅对应论文原文的4.1小节
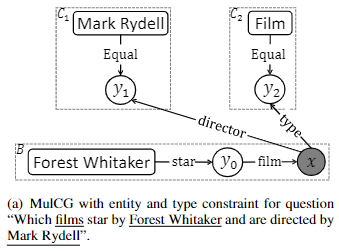
例句1:由Mark Rydell执导,并且还有Forest Whitaker参演的那个电影叫啥?
多实体约束示例:
- 将以上多约束问题转化得到的基础查询图称为$G_0$
- 遍历问题中的实体,针对实体”Mark Rydell”找到对应短句,并将实体替换为特殊词元
<e>,借助孪生CNN网络找到与文本“由<e>执导”最相似的边:“导演” - 由此得到额外的实体约束:
<Mark Rydel,Equal,y1>
实体类型约束示例:
- 将根据“问题焦点“的定义抽取到的名词集合作为实体的类型集合
- 遍历搜寻问题中的实体类型,找到实体类型”电影“
- 由此得到额外的类型约束:
<电影,Equal,y1>
多实体+类型约束图示:
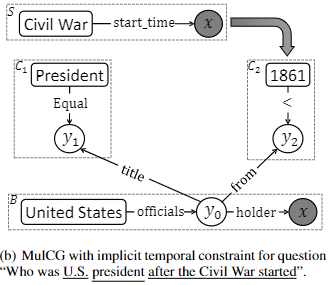
例句2:南北战争爆发后,谁是美国的总统?
显式时间约束示例:
- 使用斯坦福推出的NER工具识别文本中的时间短语,其中的时间值为$t$
- 使用关键词”after“或"later then"触发函数型边:<(小于)
- 使用关键词”before“或"earlier then"触发函数型边:>(大于)
- 如果链接到实体的路径(1~2跳)中存在类型"Date_Time",则保留此约束
隐式时间约束示例:
- 根据预设关键词”when“、”before“、”after“、”during“等检测存在时态的短语
- 比如短语”南北战争爆发后“存在时态,将其转化为问题”南北战争什么时候爆发?“
- 之后使用本文的问答系统回答以上问题:”南北战争1861年爆发 “
- 将隐式时间约束转为显式时间约束:”南北战争爆发后“——>”1861年后“
隐式时间约束图示:
次序约束示例:
- 使用人工收集的序数列表和WordNet的最高级(the most)词汇检测序数
- 当变量型顶点对应的宾语实体是数值型或时间型,并且顶点对应的路径最后一个词与最高级词汇相似度最高时,添加次序约束(MaxAtN 或 MinAtN)
- 比如”博尔特是短跑最厉害的人类“对应的约束可能是:
<短跑,MaxAtN,y0>
聚合约束示例:
- 当问题以”how many“开头或包含关键词”number of“、”count of“时,添加聚合约束
- 比如”how many children does bill gates have“,会统计对应实体"children"的个数
2.3.4 搜索空间与答案
生成搜索空间:
- 针对问题$Q$,检测得到实体集合$E$,生成基础查询图集合$G_b$
- 针对每个基础查询图$g_b$,进行约束的检测,得到约束的集合$C$
- 穷举所有可能约束的排列组合,得到集合$Permutation(C)$
- 基础查询图$g_b$结合一种约束组合转化为多约束查询图$g_c$
- 最终所有的查询图$g_b$和$g_c$构成了完整的搜索空间$H$
具体的算法伪代码:

针对生成的搜索空间,借助孪生CNN计算各项指标评分,具体指标列表如下:

使用排序学习算法lambda-rank(一种基于概率损失最小化的通用排序方法,对应的综述论文还没来得及看)计算不同指标的权重,汇总所有指标后找到匹配度最高的一个多约束查询图,将此查询图的对应结果作为问题的最终答案
2.4 实验分析
数据集:ComplexQuestions (简称CompQ,是本文整理开源的数据集)、WebQuestions (简称 WebQ,基于查询日志和Freebase手动标记的数据集,训练集大小为3778,测试集大小为2032)、SimpleQuestions (简称 SimpQ)
CNN训练数据:
- 使用初始系统$S_0$穷举每个问题的所有基础查询图
- 选择得分大于0的用于训练初始CNN,得到系统$S_1$
- 使用系统$S_1$筛选得分大于0.5的数据,作为最终的CNN训练数据
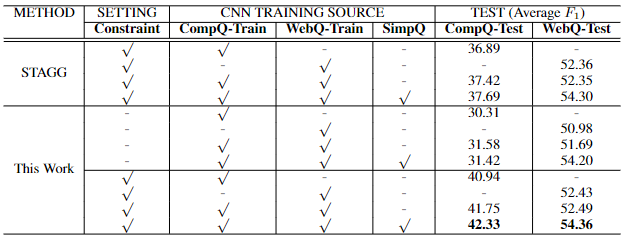
本文使用STAGG作为baseline进行对比,模型性能表现如下: