中文标题:训练计算最优的大语言模型
英文标题:Training Compute-Optimal Large Language Models
发布平台:预印本
发布日期:2022-03-29
引用量(非实时):
DOI:10.48550/arXiv.2203.15556
作者:Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Jack W. Rae, Oriol Vinyals, Laurent Sifre
关键字: #Chinchilla #龙猫法则 #DeepMind
文章类型:preprint
品读时间:2023-11-22 14:50
1 文章萃取
1.1 核心观点
对于计算最优的训练,模型大小和训练的数据量应该同等缩放:即模型的参数量/尺寸每加倍一次,模型对应的训练数据/token 数量也应该加倍。本文通过训练预测的计算最优模型 Chinchilla 来测试这一假设,该模型使用与 Gopher 相同的计算预算,但具有 70B 个参数(Gopher 是280B)和 4 倍多的数据量
Chinchilla 在大量下游评估任务上均显着优于 Gopher (280B)、GPT-3 (175B)、Jurassic-1 (178B) 和 Megatron-Turing NLG (530B),在 MMLU 基准测试中达到了最先进的平均准确率 67.5%,比 Gopher 高 7%。而 Chinchilla 更小的参数量也大幅降低了推理成本,有助于促进下游任务的使用
1.2 综合评价
- 本文内容思路清晰,叙事逻辑有条理,围绕单一论点进行了充分实验和探究
- 本文核心论点(模型大小和训练的数据量同等缩放)有助于其他研究的模型设计
- 结论可能具有时效性,模型结构/训练技巧/数据质量的变动都可能影响到龙猫法则
1.3 主观评分:⭐⭐⭐⭐⭐
2 精读笔记
2.1 相关工作
Kaplan et al. (2020) 的研究工作表明:
自回归语言模型(LM)中的参数数量与其性能之间存在幂律关系
不应将大型模型训练到尽可能低的损失以实现最佳计算
随着计算预算的增加,模型大小应该比训练数据大小增加得更快
相比之下,本文则认为这两个数量应该以大致相同的速度扩展
其他工作成果小结:
- 其他重要的影响因素:学习率、学习率计划、批量大小、优化器和宽深比
- 最佳批量大小(batch size)和模型大小之间仅存在弱依赖性
- 改进语言模型的正交方法是通过显式检索机制来增强 Transformer
- 语言模型的性能可能比以前想象的更依赖于训练数据的大小
2.2 策略制定
本文制定以下策略来权衡限定 FLOPs 预算下的模型大小和训练 token 量
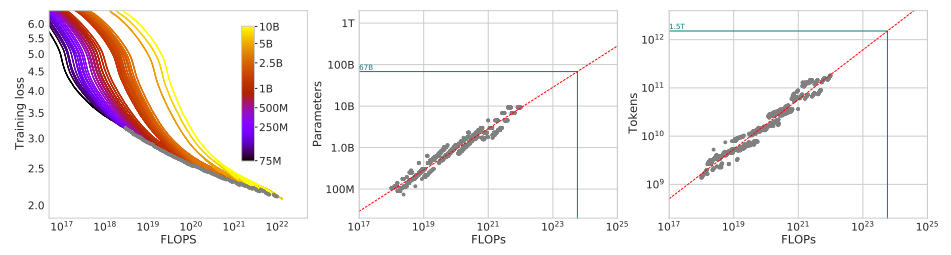
- 方法 1:固定不同的模型大小(70M~10B)并改变训练的 token 量
- 方法 2:固定 9 种 FLOPs 预算并改变模型的大小(考虑最终的训练损失)
- 方法 3:拟合参数,使用前两种方法得到的结果作为训练集进行建模:
$$\hat{L}(N,D)\triangleq E+\frac{A}{N^\alpha}+\frac{B}{D^\beta},$$
- 其中 $N$ 表示 token 量,$D$ 表示模型大小,其他为待拟合参数
- 最优化方法:使用 L-BFGS 算法最小化预测和观察到的 Huber 损失:
$$\min_{A,B,E,\alpha,\beta}\sum_{\text{Runs }i}\text{Huber}_\delta\Big(\log\hat{L}(N_i,D_i)-\log L_i\Big)$$
最终拟合曲线可表示如下:
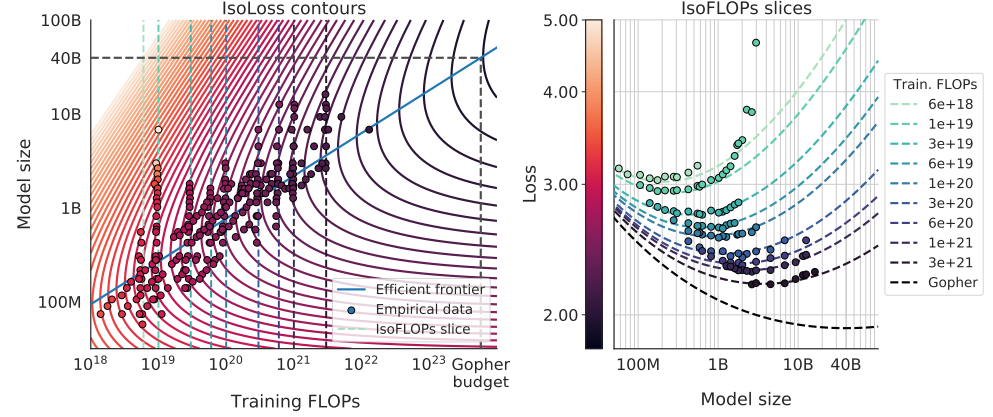
- 虚线表示不同的FLOPs 预算限制;蓝色实线是双对数空间中的一条有效边界
- 随着FLOPs 预算的增加,模型大小和训练数据量应以大致相等的比例增加
三种方法的结果存在一致性:
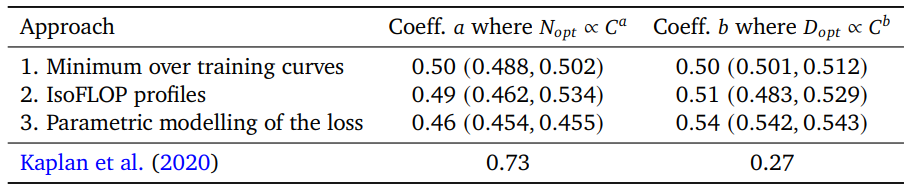
- 其中$a=\frac\beta{\alpha+\beta}$,$b=\frac{\alpha}{\alpha+\beta}$;三种方法的结果种,二者都接近1:1
- 意味着随着计算量的增加,参数和数据量的缩放比例几乎相等
- 置信区间的10%和90%分位数来自 bootstrapping 抽样估计
2.3 Chinchilla 模型
根据上一节的分析,本文针对 Gopher 模型进行调整并得到了 Chinchilla 模型:

Chinchilla 的训练设置与 Gopher 基本一致,除了以下几点:
- 训练数据集(MassiveText)与 Gopher 相同,但会借助子集分布来实现 Token 量的增加
- 优化器从 Adam 改为 AdamW,改善语言建模损失和微调后的下游任务性能
- 稍微修改 SentencePiece tokenizer(训练的 token 有 94.15% 与 Gopher 保持一致)
- 实际运算时的浮点数为 bfloat64,但在分布式优化器状态中存储参数的 float32 副本
2.4 实验分析
在不同的评估任务上,Chinchilla 都优于 Gopher:
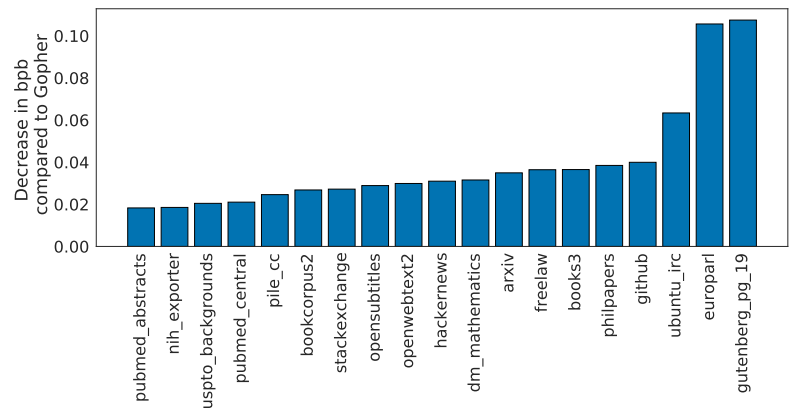
- 纵轴表示,Chinchilla 模型性能表现相比 Gopher 模型的改善程度
不同模型的多任务语言理解 (MMLU)评估:

其他评估:
- 单词预测(LAMBADA),Chinchilla 准确率为 77.4%,而 Gopher 准确率为 74.5%
- BIG-bench 的 57 项任务中,Chinchilla 除了在 51 个单个任务上表现更好、2 个任务上表现相同、仅在 4 个任务上表现较差,平均比 Gopher 表现好 7.6%
- 阅读理解(RACE-h 和 RACE-m),Chinchilla 为 71.6%/75.1%,而 Gopher 为 82.3%/86.8%
- 常识基准评估(PIQA, SIQA, Winogrande, HellaSwag, BoolQ)Chinchilla 都优于 Gopher 和 GPT-3
- 模型真实性评估(TruthfulQA)和闭卷问答(Natural Questions)Chinchilla 都优于 Gopher
- 相比于 Gopher, Chinchilla能更好地避免性别歧视和 toxic(侮辱/仇恨/亵渎/威胁等)
3 后记
- 2023年7月,博主 Thaddée Yann TYL 针对本论文中论点提出了一些质疑
- 该文章基于对 LlaMA2 论文及其数据,给出了以下训练过程的可视化:
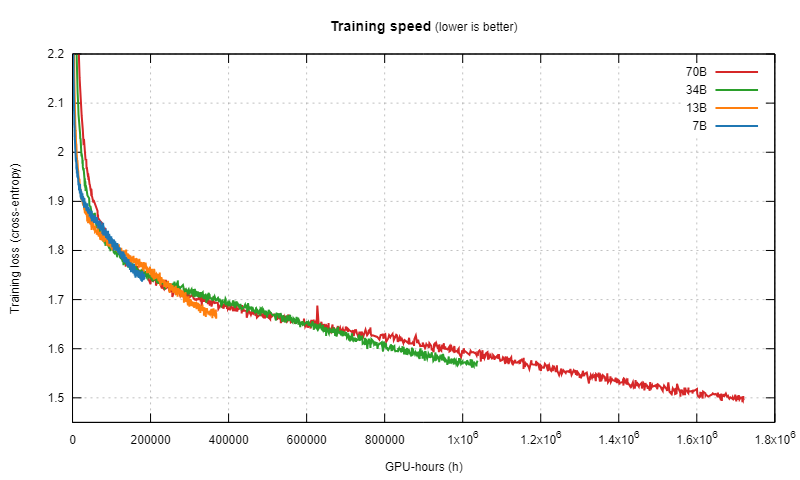
- 基于此图中的表现,该文章提出了一个与龙猫法则略有不同的观点:如果有充足的计算资源和数据,训练足够长时间,小模型的表现也可以超越大模型
- 此外,文章还针对基于余弦衰竭的学习速率机制提出了质疑(可能干扰了小模型的后期学习?)
评论补充:
- 增大模型的参数量确实是一种前进的方向,但目前的收益是递减的
- 相比于训练曲线,可能验证曲线会更令人信服(考虑小模型的过拟合风险)
- 目前的LLMs几乎都没有正则化器,使用大型且多样化的训练集是最好的正则化器
- 模型越小,需要更多的计算来弥补差距(达到 67B 模型的训练损失,33B 模型需要 2.3 倍的计算,13B 模型需要 25 倍的计算,7B 模型需要 7837x 的计算)