中文标题:在股票走势预测中融入细粒度事件
英文标题:Incorporating Fine-grained Events in Stock Movement Prediction
发布平台:EMNLP
发布日期:2019-01-01
引用量(非实时):34
DOI:10.18653/v1/D19-5105
作者:Deli Chen, Yanyan Zou, Keiko Harimoto, Ruihan Bao, Xuancheng Ren, Xu Sun
文章类型:conferencePaper
品读时间:2023-12-09 15:23
1 文章萃取
1.1 核心观点
本文为了将细粒度事件纳入股票走势预测中。首先提出了一个由领域专家构建的专业财经事件字典,并利用它自动从财经新闻中提取细粒度的事件;然后,本文设计了一个神经模型,将财经新闻与细粒度的事件结构和股票交易数据相结合,以预测股票走势
最终实验表明,MSSPM 模型表现优于所有基线,并表现出较好的泛化能力
1.2 综合评价
- 考虑了事件抽取和股票预测的联合学习,显著增强了模型的泛化性
- 词典的设计细节比较模糊,也没有相关数据公开;无法复现和参考
- 考虑基于注意力机制的更自动智能化的词典设计和关键新闻词挖掘
1.3 主观评分:⭐⭐⭐⭐
2 精读笔记
2.1 TOPIX 财经事件词典
TOPIX 财经事件词典(TFED):
- TFED 包含8个类别的32种金融的细粒度事件,涵盖了与 TOPIX(东证股价指数) 变动高度相关的金融事件类型(如盈利、并购和信用评级)
- 每个细粒度事件都包含触发词和事件角色(Event Roles);事件角色包括主谓宾(BIO)和其他细节(如收益时间,市值,变化率)
- TFED 来自三位金融领域专家的总结,并使用常规 NLP 算法进行辅助
基于 TFED 的事件抽取过程:
- 从财经新闻中提取词性和句法信息,分析工具为斯坦福开源的 CoreNLP
- 按 TFED 过滤可能是事件实例的新闻(包含任意事件的触发词)
- 根据领域专家设置的匹配规则检验依赖关系,并确保事件角色对应的词性(POS)标签与预定义的标签一致;满足依赖关系和 POS 标签一致性的新闻才会被视为一个事件实例
- 最后使用命名实体识别中的 BIO 标签标准来规范化标签结果
提取结果表明,该方法覆盖了210k 新闻中的71% 的样本
2.2 结构化股票预测模型 SSPM
SSPM 的模型结构如下所示:
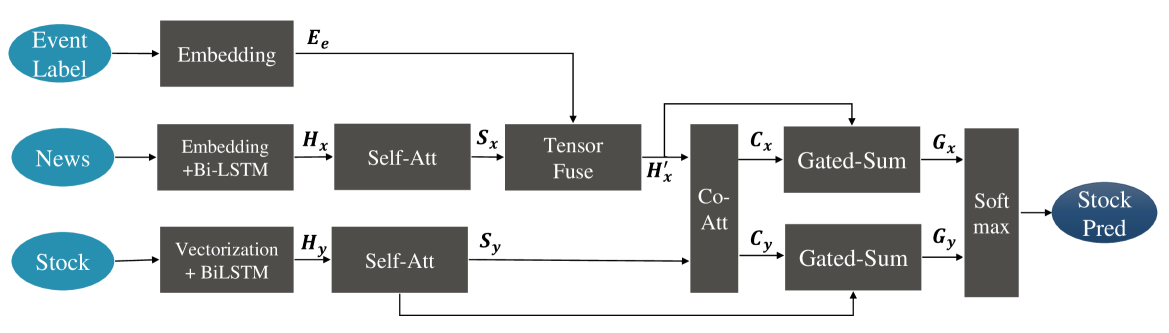
- SSPM 的模型输入包含三部分,其中股票信息为分钟级股价数据(first/last/highest/lowest)和交易量信息(总交易额、交易量、交易量加权的平均价格);新闻和事件的文本嵌入表示则来自两个预训练模型(Glove/ELMo)的拼接
- 模型通过双向长短期记忆(BiLSTM)和自我注意力挖掘文本和股价的向量表示
- 模型使用以下公式将包含文本和标签的事件信息$E_e$,与新闻信息$S_x$融合(fuse):
$$H_x^{'}=\sigma(W_f[S_x;E_e;S_x-E_e;S_x\circ E_e]+b_f)$$
- 模型使用协同注意力(Co-Att)实现两种信息(新闻文本/环境变量,股票价格/历史趋势)的交流,再使用门控机制合并(Gated Sum)原始向量表示和注意力结果
- 模型最后拼接$G_x$和$G_y$两部分深层特征,通过$softmax$函数之间预测股票趋势
2.3 多任务联合训练 MSSPM
虽然 SSPM 的性能优于所有基线,但它几乎无法处理 TFED 无法识别的新闻,即未覆盖的新闻,因此 MSSPM 被设计为使用细粒度事件作为监督标签来学习事件提取
在 MSSPM 中联合学习事件提取和股票预测,因为这两个任务是高度相关的。事件提取结果的提高可以促进新闻理解和股票预测。股票预测的输出可以反馈给事件提取
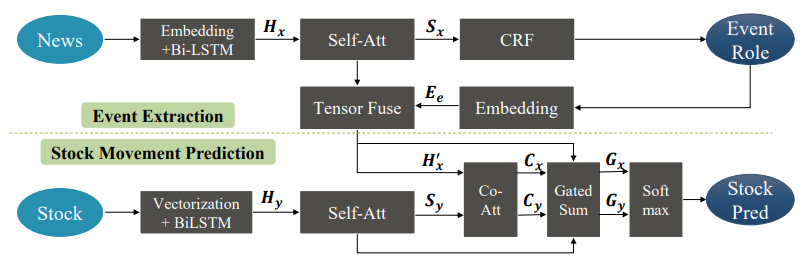
- MSSPM 模型的基本结构和 SSPM 模型相似,模型的输入都是新闻和交易数据,模型的输出也都是股票价格趋势(上涨/下跌),只是多了一个事件抽取模块
- 事件提取视为序列标注任务,先使用 BiLSTM 获取句子表示,之后利用自我注意力学习更好的句子表征,最后通过 CRF 来优化输出(序列标注)
- 考虑到事件提取和股价预测的强相关性,MSSPM 进行联合的多任务训练;最终模型的损失函数由事件抽取的负对数损失$LS_e$和股价预测的负对数损失$LS_s$组成:
$$LS=\lambda LS_e/L+(1-\lambda)LS_s$$
其中$\lambda$为超参数,在本文中的最佳取值为 0.43
2.4 实验结果与分析
实验设置说明:
- 数据收集的时间跨度 2011 年~2017 年,主要考虑 TOPIX 前1000名股票
- 新闻数据主要来自专业财经新闻提供商路透社(仅考虑标题,正文中噪音较多)
- 最终数据集中,股票上涨和下跌率分别为 45% 和 55%
- 评估指标是准确性和马修相关系数 MCC(可克服数据不平衡问题)
实验结果对比:
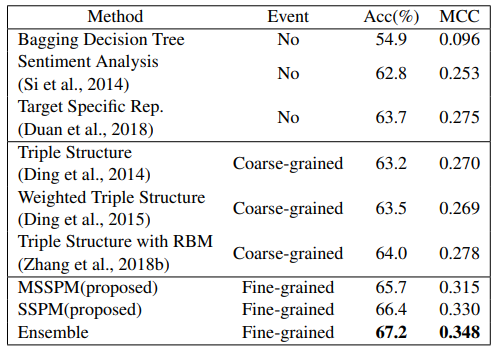
- 最终实验表明,MSSPM 模型表现优于所有基线,SSPM 模型为次优结果
- Ensemble 方法遵循一个简单的规则来组合 SSPM 和 MSSPM:TFED 覆盖的新闻由 SSPM 处理,未覆盖的新闻由 MSSPM 处理
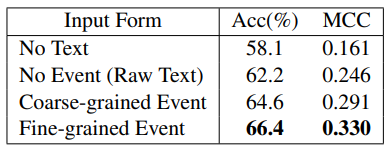
不同文本输入类型的 SSPM 模型表现对比(细粒度事件最优)
新闻是否被 TFED 覆盖的对比:
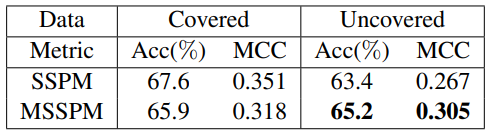
- MSSPM 在未覆盖的新闻上表现更好,说明股票预测的泛化性提高了
- 对于 TFED 已覆盖的新闻,基础版本的 SSPM 表现反而更好
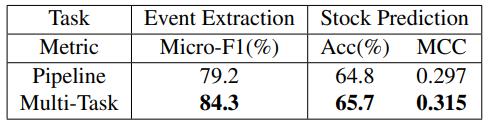
Pipline (独立训练并依次调用模型)与联合学习对比: