中文标题:基于语言模型构建可组合的机器人3D操纵图
英文标题:VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models
发布平台:预印本
暂无
发布日期:2023-07-12
引用量(非实时):
DOI:10.48550/arXiv.2307.05973
作者:Wenlong Huang, Chen Wang, Ruohan Zhang, Yunzhu Li, Jiajun Wu, Li Fei-Fei
关键字: #VoxPoser
文章类型:preprint
品读时间:2023-07-13 16:06
1 文章萃取
1.1 核心观点
本文提出了VoxPoser,这是一种从预先训练的语言模型中提取机器人操作的提示和约束的方法。具体来说,VoxPoser的输入为观察空间(图像信息)和指定任务,通过LLMs对任务进行拆解排序;之后针对每一个子任务,VoxPoser借助VLM/LLM直接生成代码块并以此构建约束图;最后VoxPoser可以借助多种约束图和启发式探索来迭代运动轨迹,实现动态干扰下的任务稳健执行。通过实验分析可发现,VoxPoser不但性能表现出色,泛化能力强,还能从有限数量的在线交互中受益,并实现有效地学习动力学模型
1.2 综合评价
- 本文尝试借助通用大模型的对机器人学进行赋能,并实现了零样本+抗干扰的机器人轨迹生成
- 由于VoxPoser涉及很多算法、模型和结构的交互,因此论文整体稍显杂乱细碎,部分细节也会一笔带过
- 随着未来多模态的发展,类似VoxPose的机器人算法一定会具备更好地落地效果,未来可期
1.3 主观评分:⭐⭐⭐⭐⭐
2 精读笔记
2.1 背景知识
具身智能机器人:像人一样能与环境交互感知,自主规划、决策、行动、执行能力的机器人/仿真人
“具身”(Embodiment)是一个心理学概念,其基本含义是指认知对身体的依赖性,即身体对于认知具有影响
大型语言模型(LLM)能捕获语言中内蕴的人类知识和经验,如何利用好这种可推广的知识是具身智能的关键
传统方法的限制:
- 传统方法多利用词汇分析/形式逻辑/图形模型来解析指令,而LLM模型能够将指令直接分解为文本步骤序列
- 但目前的方法在与环境的物理交互时,会更多地依赖于模型或规划师调用预先设计或训练的基本运动(技能)库
- 由于缺乏大规模机器人数据,这种对基础技能获取的依赖通常被认为是系统的主要瓶颈
- 所以下一步改进的关键在于:在机器人的细粒度动作层面上利用好LLM的内化知识,而不是手动设计
LLM相关的主流思路
- 已有的方法也能够实现端到端学习机器人交互中的基础语言指令,常用方法包括模型学习/模仿学习/强化学习
- 最新的有监督学习主要是将语言指令映射到2D成本图,用于引导运动规划器以无碰撞的方式生成首选轨迹
- 有团队认为LLM表现出行为常识,可用于低水平控制。但仍然需要手工设计的运动基元,以组成顺序策略逻辑
- 还有团队从奖励设计的角度思考,使用LLM对训练过程进行奖励规范,探索强化学习和人类偏好学习
本文也沿用这一思路,将LLM产生的奖励置于机器人的3D观察空间中
2.2 方法说明
2.2.1 定义VoxPoser优化问题
$$min_{\tau_i^r}{\mathcal{F}_{task}(T_i,l_i)+\mathcal{F}_{control}(\tau_i^r)}\ \ \ \rm{subject} \ \rm{to}\ \mathcal{C}(T_i)$$
- $i$表示时刻,给定文本指令$L$后,模型会生成一系列的子任务$\Gamma \rightarrow {l_1,l_2,...,l_n}$
- $T_i$表示时刻$i$时的环境状态演变;$\tau_i^r$表示时刻$i$的机器人轨迹;$\mathcal{C}(T_i)$表示动力学/运动约束
- 函数$\mathcal{F}_{task}$根据输入环境状态$T_i$和子指令$l_i$,对任务完成度进行评分
- 函数$\mathcal{F}_{control}$则用于成本控制,鼓励轨迹$\tau_i^r$追求最低的变动成本/处理时间
- 每个子任务都会进行最优化求解,最终得到一系列的机器人轨迹,实现最终指令$L$
细节:指令拆分
- 举例:一个简单指令“打开顶部抽屉”可拆分为"抓住抽屉把手"+"拉开抽屉"
- 指令拆分和排序一般由高级计划者完成(比如大语言模型 LLM,或基于搜索的规划算法)
- 在本文实验部分,主要使用OpenAI的API中的GPT4来实现这一环节
定义$V \in \mathbb{R}^{w\times h \times d}$是一个在机器人观测空间内的3D体素(voxel)值图
- 给定子任务”抓住抽屉把手“后,$V$能反映”抽屉把手“对机器人的吸引力
- 给定提示”小心花瓶“后,$V$能反映”花瓶“对机器人的排斥力
定义机器人的末端执行器为$e$,其对应的轨迹可表示为$\tau^e$
给定指令/子任务$l_i$后,函数$\mathcal{F}_{task}$可根据$e$在$V$上的分值进行遍历累加得到: $$\mathcal{F}_{task}=-\Sigma_{j=1}^{|\tau^e|}V(p^e_j)$$
- 其中$p^e_j$表示末端执行器$e$在步骤$j$(对应轨迹$\tau^e$上的第$j$个点)时,对应的离散坐标系为$(x,y,z)$
2.2.2 将语言指令映射到 3D 值图
本文使用LLMs来直接生成3D体素值图$V$
- 首先,调用感知器API(视觉语言模型/开放词汇检测器)获取对象的空间几何信息
- 然后,借助LLMs直接生成Python代码来生成并操作Numpy数组
- 最后,在已生成的Numpy数组中填补精确值
以上过程也被称为$VoxPoser$方法,它的输入输出可定义如下: $$V_i^t=VoxPoser(o^t,l_i)$$
- 其中$o^t$表示时刻$t$时的观察空间(RGB-D,即带有深度信息的颜色数据);$l_i$是给定的指令/子任务
- 输出结果$V$经常是稀疏的,因此常使用平滑操作来致密3D体素值图(有利于生成更平滑的轨迹)
体素,即体积的像素。用来在3D空间中表示一个显示基本点的单位。类似于二维平面下的像素(pixel)
为了更好地实现机器人操作,还需要对已有轨迹参数进行丰富(构造其他约束图):
- 体素值图$V:\mathbb{N}^3\to \mathbb{R}$描述了不同空间位置的”奖励/成本”,而借助LLMs可以生成其他值图
- 定义$V_r:\mathbb{N}^3\to SO(3)$为旋转图,用来描述不同空间位置的”旋转成本/推荐姿态”
- 定义$V_g:\mathbb{N}^3\to {0,1}$为夹具控制图,用来描述不同空间位置的”夹具的开启/关闭”
- 定义$V_v:\mathbb{N}^3\to \mathbb{R}$为速度图,用来描述不同空间位置末端执行器的”指定速度”
在机器人学中,SO(3)对应三维特殊正交群,代表刚体运动中的旋转运动;
而SE(3)对应特殊欧式群,代表刚体变换运动(旋转+平移)
2.2.3 零样本合成机器人操纵的轨迹
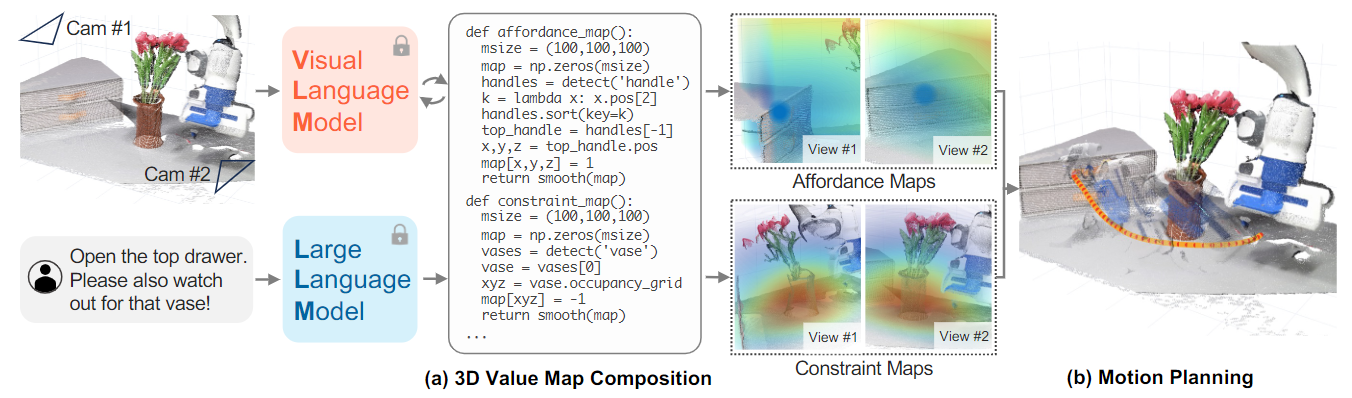
上一节,VoxPoser基于VLM/LLM得到了不同奖励/约束图,可用于最终的轨迹生成
零样本轨迹生成:
- 奖励/约束图是依赖于实体的,而实体则来自VLM/LLM;实际处理时需借助词汇检测器 OWL-ViT 来分辨不同实体,并获取边界框;之后需要将其输入 Segment Anything 以获得实体掩码,并使用视频跟踪器 XMEM 跟踪掩码(跟踪掩码最终会和RGB-D观察空间一起用于后续任务)
- 每个语言模型程序(LMP)负责特定的功能(例如,处理感知调用)的价值映射,主要包括奖励/成本图、速度图、旋转图、夹具动作图;除此之外,还会有两个高级LMP分别用于:任务的拆分/排序,以及根据子任务调用LMP
- 实际的运动规划主要使用贪心搜索算法,算法输入仅考虑奖励/成本图(二者权重比为2:1),算法输出为一系列无碰撞的末端执行器坐标位置(轨迹);然后通过其他值图对每个坐标位置进行参数补充(速度、旋转、是否夹启)
- 合成轨迹后将执行第一个路点(对应一个),之后在0.2s内(5Hz)重新规划新的轨迹
- 所以VoxPoser不但能零样本的生成轨迹,还可以在动态干扰的情况下稳健地执行任务
欧氏距离应用于奖励图,高斯滤波器应用于成本图(原文描述记录,暂不清楚具体细节)
OWL-ViT 是一个开放词汇对象检测网络,在各种类型(图像、文本)的样本对上进行训练。它可以用于通过一个或多个文本查询来查询图像,以搜索和检测文本中描述的目标对象
Segment Anything 效果出色的任意颗粒度多目标检测工具 #待补充
XMEM 是一种基于记忆模型(分为感觉记忆、工作记忆和长期记忆)的长视频目标分割框架
除了具备零样本合成轨迹的能力,VoxPoser还可以从真实操作中受益,实现有效的在线学习
- 时刻$t$时的环境信息$o_t$随着操作$a_t$的执行,将会产生时刻$t+1$时的环境信息$o_{t+1}$
- 随着在线操作的进行,VoxPoser将会收集到环境的转换数据:$(o_t,a_t,o_{t+1})$
- 通过最小化预测环境信息$\hat{o}_{t+1}$和真实环境信息$o_{t+1}$之间的L2损失,来构建动态模型$g_{\theta}$
为了更好地利用LLMs中的通识信息,可以考虑对轨迹$\tau_t^r$附近进行动作采样,并通过添加小噪声来鼓励局部探索;从而避免了对稀疏的完整动作空间的探索,进而显著加快学习的过程
2.3 实验分析
本文使用Franka Emika 机器人搭建了一个真实操作桌面,并选择了5种代表性任务来进行评估:
| LLM + Prim. | LLM + Prim. | VoxPoser | VoxPoser | |
|---|---|---|---|---|
| Task | Static | Dist. | Static | Dist. |
| Move & Avoid | 0/10 | 0/10 | 9/10 | 8/10 |
| Set Up Table | 7/10 | 0/10 | 9/10 | 7/10 |
| Close Drawer | 0/10 | 0/10 | 10/10 | 7/10 |
| Open Bottle | 5/10 | 0/10 | 7/10 | 5/10 |
| Sweep Trash | 0/10 | 0/10 | 9/10 | 8/10 |
| 整体成功率 | 24.0% | 14.0% | 88.0% | 70.0% |
- 整体来看,VoxPoser的成功率远高于大模型+预定义基础动作(LLM + Prim)的情况
- VoxPoser可以借助LLMs获得丰富的常识知识,比如“推断绕z轴逆时针旋转可以打开瓶子”
- 与传统的顺序策略逻辑相比,VoxPoser通过考虑约束并整合空间信息进行联合优化的方式更灵活稳健
此处的LLM + Prim主要指的是Code as Policies(谷歌在22年底推出的语言模型控制机器人算法)的变种
VoxPoser面对未见过的指令/属性也具备强大的泛化能力:
| Train/Test | Category | U-Net MP | LLMs Prim. | LLMs MP (Ours) |
|---|---|---|---|---|
| SI SA | Object Int. | 21.0% | 41.0% | 64.0% |
| SI SA | Composition | 53.8% | 43.8% | 77.5% |
| SI UA | Object Int. | 3.0% | 46.0% | 60.0% |
| SI UA | Composition | 3.8% | 25.0% | 58.8% |
| UI UA | Object Int. | 0.0% | 17.5% | 65.0% |
| UI UA | Composition | 0.0% | 25.0% | 76.7% |
- SI”和“UI”指的是见过和未见过的指令。 “SA”和“UA”指的是见过和未见过的属性
- U-Net MP是基于U-Net网络结构进行有监督学习得到的模型
- VoxPoser 在两个类别(总共 13 项任务)上都优于两个基线(U-Net MP,LLMs Prim)
零样本的轨迹合成作为先验可以有效指导模型的动态学习:
| Zero-Shot | No Prior | w/ Prior | |
|---|---|---|---|
| Task | Success | Success Time(s) | Success Time(s) |
| Door | 6.7%±4.4% | 58.3±4.4% TLE | 88.3%±1.67% 142.3±22.4 |
| Window | 3.3%±3.3% | 36.7%±1.7% TLE | 80.0%±2.9% 137.0±7.5 |
| Fridge | 18.3%±3.3% | 70.0%±2.9% TLE | 91.7%±4.4% 71.0±4.4 |
- 上表主要测试 VoxPoser 能否打开三种具备复杂结构的铰链物体
- 第一列为零样本操作,第二列不使用先验分布,整体表现一般
- 第三列使用零样本轨迹作为先验指导模型的动态学习,整体表现出色
VoxPoser和两个基线模型的误差原因分析:
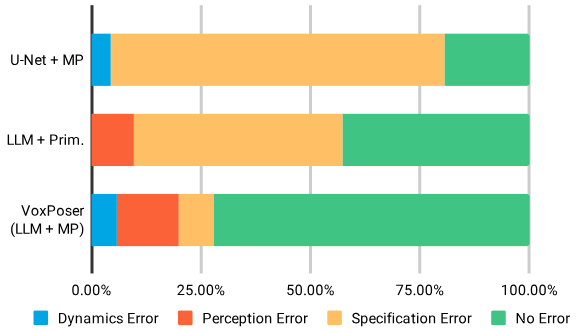
- UNet + MP 直接将 RGB-D 观测值映射到值图,然后由运动规划器 (MP) 使用,因此没有独立感知模块(Perception 橙色)
- LLM + Primitives 使用 LLM 顺序组合基础动作,因此没有动态模块(Dynamics 蓝色)
- 规范错误(Soecification Error,黄色)指的是策略逻辑或价值图生成时发生的错误
- VoxPoser 整体误差最小,且误差原因主要来自感知模块(通过VLM/LLM的加强来持续改善VoxPoser性能)
VoxPoser具备应对突发行为的能力,还能根据理解复杂的用户意图,实现更复杂场景的操作:

- 估计物体的物理属性(左上):使用可用的工具进行物理实验,推断不同块的质量差异】
- 行为常识推理(右上):在用户指定行为偏好(”我是左偏子“)的情况下完成设定任务
- 细粒度语言校正(左下):通过更精细的用户指令(“你偏离了1cm”)对行为进行修正
- 多步骤视觉程序(右下):由于机器人不清楚抽屉有多长,所以需要先全部打开再往回收拢
局限性:
- 依赖于外部感知模型,限制了需要视觉推理或理解物体颗粒度/几何形状的任务
- 适用于高效的动力学模型,但面对丰富的任务需要配套的动力学模型具备相同的泛化能力
- 目前的VoxPoser仅考虑了末端执行器轨迹,全臂规划可能是一种未来更好的选择
- 需要人工设计提示工程(详见论文原文的附录A.1)来满足不同的LLMs输出需求
更多示例及其效果,推荐前往VoxPose 项目地址观看
相关资源
- 论文在线地址
- 本地文件地址:Huang et al_2023_VoxPoser.pdf
- 本地Zotero地址:Huang et al_2023_VoxPoser.pdf