GBTM理论:GBTM
GMM理论:GMM
1 论文汇总
1.1 收缩压时序轨迹与急性脑出血结局
论文标题:Temporal Trajectory of Systolic Blood Pressure and Outcomes in Acute Intracerebral Hemorrhage: ATACH-2 Trial Cohort
主要结论: 以中低SBP组为参考,高至低SBP组显示3个月时死亡或残疾的风险显着较高(调整后OR,2.29 [1.24-4.26])、7天内急性肾损伤(调整后OR,3.50 [1.83-6.69])、7天内肾脏不良事件风险(调整后OR,2.84 [1.22–6.62])和 7 天内心脏不良事件(调整后OR,2.26 [1.10–4.64]),但神经功能恶化的风险没有增加(调整后 OR,0.48 [0.20–1.13]
发表年份:2022
影响因子或引用量:IF 8.3 Q1 B1 Top 引用量1
数据说明:
- 2011年至2015年,1000名ATACH-2试验(急性脑出血的抗高血压治疗)的急性脑出血患者
- 被随机分为强化(110-139 mmHg)或标准(140-179 mmHg)静脉尼卡地平降低收缩压(SBP)组
- SBP数据在入院后随机分组前24h内采集,分组后第1小时15min采集一次,之后23小时1h采集一次
ATACH-2 试验是一项国际、随机、两组、开放标签试验,旨在确定快速降低 SBP 对急性自发性脑出血患者的疗效
目标变量: 3 个月内死亡或残疾、24 小时内神经功能恶化、发病后 7 天内急性肾损伤
纳排标准: 患者入院时GCS>=5,收缩压>=180mmHg,实质内血肿体积<60ml
考虑特征:地点、性别、年龄、既往史(高血压、糖尿病、高脂血症、心房颤动、指标事件前的中风/短暂性脑缺血发作、冠心病和充血性心力衰竭、吸烟习惯、抗高血压药物处方、GCS、美国国立卫生研究院中风量表评分、白细胞计数、血小板计数、血糖和血清肌酐
统计或建模方法:
- 基于组的轨迹模型分析了随机化后24小时内每小时最大SBP的时间变化
- 采用 GBTM 方法( Stata 的traj 插件)来识别 SBP 轨迹,并使用贝叶斯信息准则 (BIC) 进行模型筛选
- 创建逻辑回归模型是为了阐明主要和次要结果与轨迹分组的关联
统计或建模结果:
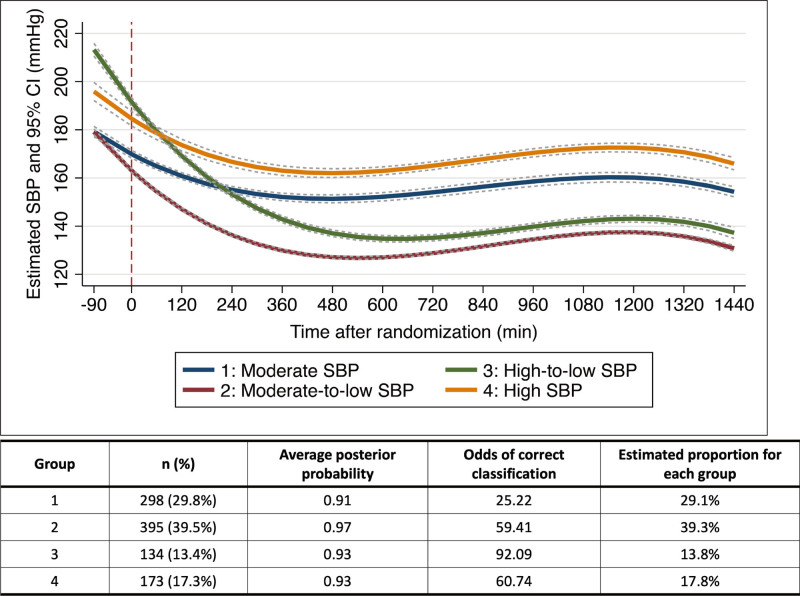
- 使用 GBTM 方法进行强力搜索,找到了从到达医院到随机化后 24 小时的 SBP 轨迹的 20 个候选模型
- 在候选模型中,具有 4 个三次项的 4 组模型显示出最高的 BIC;每组的后验概率均>0.90
- 中度 SBP(从入院时的 ≈190 mm Hg 到随机化后的 150–160 mm Hg;n=298)、中至低 SBP(从 ≈190 mm Hg 到 <140 mm Hg;n=395)、高到低 SBP(从 >210 mm Hg 到 <140 mm) Hg;n=134)和高SBP(从 >210 mm Hg 到 160–170 mm Hg;n=173)
- 接受强化治疗的患者分别占各组的11.1%、88.6%、85.1%、1.7%
局限性或改进方向:
- 高至低和中至低 SBP 组的大多数患者被分配到强化 SBP 降低,这可能是一个主要限制
- SBP 轨迹的数量和形状的模型选择可能会影响本研究的结果(本文为了确保可重复性,使用暴力搜索+BIC筛选模型)
- 由于 ATACH-2 中脑叶 ICH 的比例较低,因此该结果可能并不完全适用于脑叶 ICH 患者(概率低)
- 脑小血管疾病可能是考虑降压治疗脑出血的重要因素,但 ATACH-2 数据集中未提供该因素
创新性或结果评价:
- 全面论证了急性脑出血的临床结果与 GBTM 方法确定的 SBP 轨迹之间的相关关系,该方法在 SBP 分组方面的随意性较小
其他补充:
- SBP高至低组血肿扩大发生率最低,但4组间差异无统计学意义(P=0.09)
- 使用具有次高 BIC 的模型进行敏感性分析,发现了与主分析模型相似的轨迹
1.2 基于组的多轨迹建模
论文标题:Group-based multi-trajectory modeling
发表年份:2016
主要结论: 基于组的轨迹建模旨在识别遵循单指标(如术后发烧或体重指数)轨迹相似性的个体聚类。而基于组的多轨迹建模可以识别遵循多个指标上存在轨迹相似性的潜在个体集群(例如,慢性肾病患者的健康状况,通过其 eGFR、血红蛋白、血 CO2 来衡量)
影响因子或引用量:IF2.3 Q1 B3 引用量442
数据说明:人口中的个体轨迹,不同年龄段的动脉压/肺活量/BMI
目标变量: 基于多轨迹数据分组
统计或建模方法:
- 本文假设不同轨迹间是相对独立的,之后构建了多轨迹的似然估计函数
- 基于这一函数实现模型参数的估计,之后通过评估BIC实现多轨迹的分组
统计或建模结果:
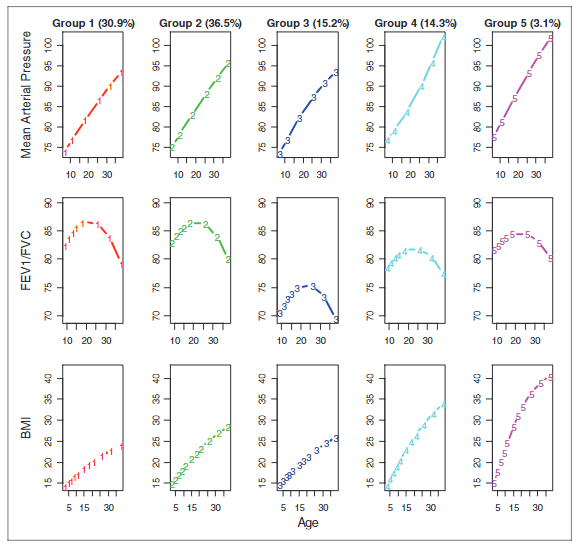
- 第 1 组在 38 岁之前一直保持在正常范围内,而第 2 组则成年后进入超重范围
- 第 3 组的特点是肺活量明显较低;第 4 组属于超重,第5组属于肥胖
- 第 4 组和第 5 组的区别在于血压和 BMI 轨迹。两组的血压均明显高于其他组
局限性或改进方向:
- 对于两个以上结果的相关轨迹,它是一种不稳定的分析形式
创新性或结果评价:
- 突出了与共同潜在病因过程相关的不同结果轨迹之间联系的异质性
- 避免两个以上轨迹分析所引起的条件概率表激增的问题
其他补充:
- 本文针对多轨迹建模有两个示例,此处只展示了一个
1.3 全膝关节置换术后的疼痛轨迹分析
论文标题:Distinguishing problematic from nonproblematic postsurgical pain: a pain trajectory analysis after total knee arthroplasty
发表年份:2022
主要结论: 术前疼痛水平可以预测疼痛轨迹组成员资格,术前中度疼痛是术后中性或正性疼痛轨迹的危险因素
影响因子或引用量:IF 7.4 Q1 B1 Top 引用量89
数据说明:
- 173名完成全膝关节置换术的患者(女性占比49%,平均年龄为62.9±6.8)
- 术后4天、6周、3个月、12个月分别进行调查问卷评测和功能测试
- 调查问卷:骨关节炎指数 (WOMAC)、下肢功能量表、医院焦虑和抑郁量表 (HADS)、疼痛残疾指数 (PDI)
- 功能测试:定时起床行走测试 (TUG)、6 分钟步行测试、上下楼梯测试、膝关节活动范围
统计或建模方法:使用GMM进行具备二次斜率的轨迹分组,并根据AIC筛选出一个最佳的4分组模型
统计或建模结果:
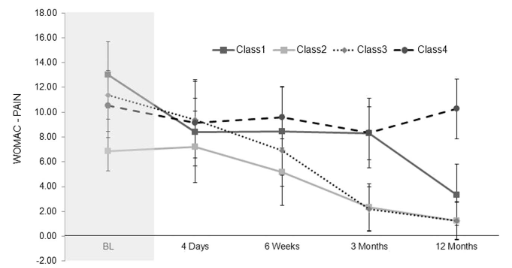
- 前 3 条疼痛轨迹代表不同的恢复率,术后 12 个月疼痛程度相对较低
- 第 4 组是持续性高疼痛组,由具有中性或正性疼痛斜率的患者组成,并且在术后第一年其疼痛体验没有表现出改善
局限性或改进方向:
- 患者参与了加巴喷丁效用的随机对照实验,可能影响患者的同质性
- 样本量有限,不足以探索心理相关变量与疼痛轨迹的关系;缺少术中数据
其他补充:
- 慢性术后疼痛 (CPSP) 是一种常见的疼痛状况,手术一年后影响 1.5% 至 10% 的成年人
1.4 基于有限混合模型和动态治疗方案形成脓毒性休克个体化复苏策略
论文标题:Individualized resuscitation strategy for septic shock formalized by finite mixture modeling and dynamic treatment regimen
发表年份:2022
主要结论:
- 通过使用有限混合模型确定了五类表现出不同临床特征的感染性休克,并通过 k 均值聚类进一步证实
- DTR 模型估计的最佳液体量显示出一种模式,在前 2 天内最初液体量较大,随后液体量需求减少
- 较大的液体输注和适当剂量的去甲肾上腺素才能在早期阶段获得更好的临床结果,并且较少的液体输注后期有好处
影响因子或引用量:IF 2.319 Q3 B3 引用量5
数据说明:
- 2016年1月至2017年12月中国25家三级甲等医院的感染性休克患者
- 在入住 ICU 后第 0、1、2、3 和 7 天收集临床和实验室变量
- 最终共有1437名死亡率为29%的患者被纳入分析
目标变量:
- 液体超负荷被定义为接受超过最佳剂量 > 1000 mL/天
- 去甲肾上腺素过量是指接受超过最佳剂量 > 0.1 mcg/kg/min
纳排标准: 缺失值 20% 或更多的患者被排除在分析之外
考虑特征:
- 人口统计和基线临床数据包括年龄、性别、患者类型(择期手术、急诊手术、非手术)、入院时体重、合并症和感染部位(腹部、胸部、大脑、血流、软组织和尿路感染)
- 记录体温、动脉血压、心率和呼吸频率等生命体征
- 入ICU后24小时内计算急性生理学和慢性健康评估(APACHE)II评分
- 实验室变量包括 pH、HCO 3 、血清乳酸、血红蛋白 (HB)、血细胞比容 (HCT)、PaCO 2 、P/F 比、碱过剩 (BE)、血小板计数、红细胞分布宽度(RDWCV)、血清肌酐和总胆红素
- 通过总结所有晶体、胶体、血液制品、鼻胃(NG)水、NG饲料、肠外营养和与静脉注射药物相关的液体摄入量来计算液体摄入量。每天测量液体的摄入量和排出量。
- 记录血管加压剂,包括去甲肾上腺素、肾上腺素、多巴胺和多巴酚丁胺
统计或建模方法:
- 使用皮尔逊相关分析检查特征变量之间的相关性,通过领域知识删除了高度相关的变量
- 使用有限混合模型(FMM)探索感染性休克的类别,并且方差被限制为跨类别相等,协方差被固定为0
- 进行 Bootstrap 似然比检验来比较 k 类模型是否优于 (k − 1) 类模型
- 使用 DTR 模型估算最佳液体量和去甲肾上腺素剂量
- 使用 XGboost 来识别液体超负荷或去甲肾上腺素过量的危险因素
DTR建模可用于估计多个治疗阶段的最佳治疗策略: $$E\left(Y|x,a\right)=f\left({x}^{\beta }; \beta \right)+\gamma \left({x}^{\psi }, a; \psi \right)$$
- 基于回归的方法用于估计入住 ICU 后第 0、1、2、3 和 7 天的最佳剂量策略
- $E\left(Y|x,a\right)$表示死亡率,$f\left({x}^{\beta }; \beta \right)$表示无治疗模型,$\gamma \left({x}^{\psi }, a; \psi \right)$表示blip函数
- 其中$x$是协变量,$a$是治疗策略;$x^{\beta}$和$x^{\psi}$是协变量向量$\text{x}$的可观测子集
- blip 函数根据$\psi$进行参数化并表征治疗效果;模型还需要指定接受治疗的倾向评分:$\pi \left(a|x\right)={f}_{A|x}\left(a|x\right)$
- 参数估计的目标是以顺序方式优化最终结果$Y$。该估计是通过动态加权普通最小二乘法进行的
统计或建模结果:
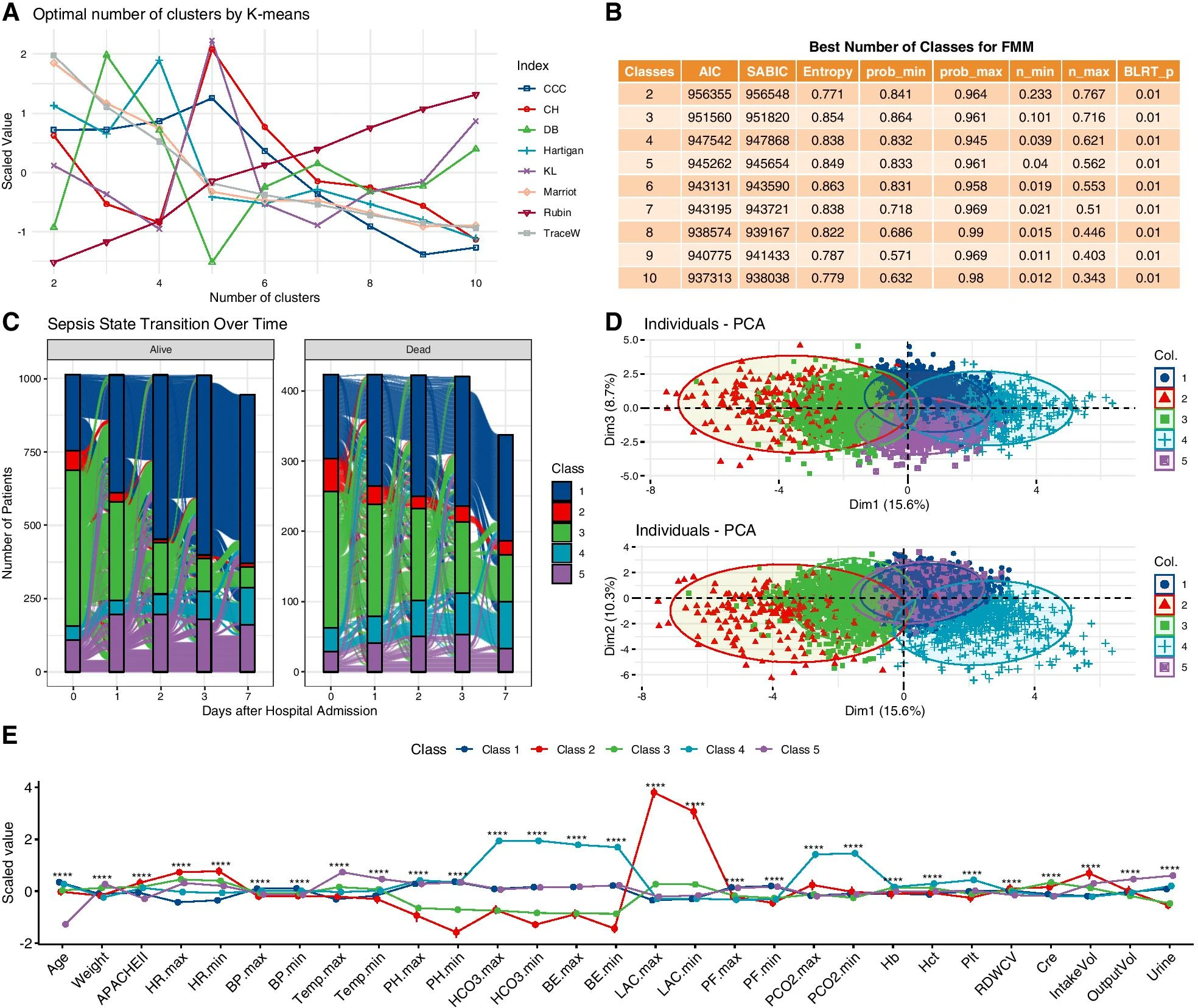
第 1 类是所有研究日中最大的类,所有变量均为平均值(基线类)
第 2 类的特点是组织灌注不良和多器官衰竭,可称为危重级
第 3 类的特点是血清肌酐最高和代谢性酸中毒,可称为肾功能障碍级
第 4 类的特点是最高 PaCO2(60;IQR 50–77 mmHg)和低 PF 比(169;IQR 118–232 mmHg),可指定为呼吸衰竭级别
第 5 类的特点是年龄小、死亡率低、肾功能保存良好,可认为是轻症级
3 类患者更有可能出现液体超负荷;较高的心率(紫色)与去甲肾上腺素过量服用的风险增加
DTR 模型估计的最佳液体量模式:在前 2 天内最初液体量较大,随后液体量需求减少
第 1 类的复苏阶段从第 3 天开始,但第 3 类(肾衰竭类)的复苏阶段从第 1 天开始
第 3 类液体超负荷的风险增加,因为受伤的肾脏无法有效维持液体平衡
第 4 类(呼吸衰竭类别)的实际液体量相对较低,这表明医生意识到液体超负荷对受伤肺部的潜在危险影响
局限性或改进方向:
- 将感染性休克患者分为五个亚类,但粒度可能不够高,无法完全实施个体化复苏策略
- 由于研究设计的观察性质,Cox 回归和 DTR 模型中可能存在残余混杂效应
- 预先确定最小患者数量,可能具有不同治疗反应的患者可能会被集中在一起(高粒度和可解释性之间的权衡)
- 有限样本量导致不允许探索不同治疗方式的组合(比如液体和去甲肾上腺素剂量)效果
创新性或结果评价:
- 分类/聚类结果稳定,最小类别成员概率大于 0.80;患者人数最少应占整个研究人群的 4% 以上
- DTR 模型也在外部独立数据集(eICU-CRD,共5756个患者)中得到了很好的验证
其他补充:
- 早期开始使用去甲肾上腺素对大多数感染性休克患者是有益的
- 较低的 AIC 和 SABIC 值以及较高的熵值被认为是更好的模型拟合
2 学习资料总结
2.1 推荐使用-latend包
latend包是R语言中一个相对小众的包,提供了一个以标准化方式聚类纵向数据集的框架
实际体验较好,集成了KML、GBTM、GMM等很多时序聚类/轨迹建模方法,而且进行了接口上的统一
已支持的算法及其API文档:
GBTM(crimCV):适用于零膨胀(包含大量零值)计数型数据的GBTM
GBTM(flexmix):适用于连续型非零值的数据的GBTM
GBTM(Lcmm):通过固定效应(fixed-effects)建模进行GBTM
GMM(Lcmm):基于潜在类进行线性混合建模(linear mixed modeling)的GMM
GMM(mixtools):使用 mixtools 指定混合回归模型的GMM
GCKM:二阶段聚类,先使用线性混合建模(linear mixed modeling),再使用K-means
LMKM:二阶段聚类,先使用线性回归建模(linear regression modeling),再使用K-means
funFEM:基于判别性函数混合(discriminative functional mixture)模型,该模型允许将数据聚类在独特且判别性的函数子空间中;适用于长时间时序;更多细节可查阅相关项目地址和论文原理
MixTVEM:使用非参数轨迹和时变效应混合对密集纵向数据进行建模(需额外加载文件,未复现成功)
NPRM:从狄利克雷分布中抽取的随机聚类比例,创建具有随机聚类分配的模型(不推荐,效果一般)
Akmedoids:基于k-means改进的时序聚类方法,适用于识别随时间变化具有相似长期线性趋势的轨迹聚类;但需要注意,最新版的R语言已删除了相关依赖包,相关项目也已经于2021年停止维护(因此不再推荐学习和使用)
longclust:基于多元 t 或高斯分布与 Cholesky 分解协方差结构混合进行纵向数据聚类或分类;但需要注意,最新版的R语言已删除了相关依赖包,相关项目也已经停止维护(因此不再推荐学习和使用)
常用评价指标(多用于确定分组数):
- Dunn Index(DI):评估聚类算法的指标(组间最近/组内最远),越大越好
- ASW:基于欧几里得距离的平均轮廓宽度(轮廓系数)
- WMAE:修正的加权MAE(绝对误差均值)
- WRSS:修正的加权RSS(残差平方和)
- BIC:贝叶斯信息量
- eT:预估耗时
2.2 GBTM相关资料
犯罪学研究与分析班研讨会-课件+数据+代码
中文教程(个人博客-繁体):GBTM介绍(上) 、GBTM介绍(下)
膝关节伸肌和内收肌内的肌内脂肪含量越高,预示着骨关节炎会更加疼痛和进行性加重 higher intra-muscular fat within knee extensor and adductor muscles predicts more painful and progressive osteoarthritis:
- 基于CNN量化脂肪体积和占比,借助GBTM和KOOS/WOMAC评分变化进行患者分组
- 说是用的Python3.8,但没找到相关代码,原论文疑似存在截断(可能是资源没找好);
基于器官功能障碍轨迹的脓毒症亚表型分析 Sepsis subphenotyping based on organ dysfunction trajectory
- 本论文主要使用GBTM划分亚组,已进行结论的验证分析
- 本研究中的所有源代码均已开源 ,但是包含R语言和Python的混用
总结:
- 大部分论文都使用Stata中的traj包来实现GBTM算法(暂不考虑)
- R语言通常使用crimCV完成GBTM算法,一个较好的示例
- Andrew P.Wheeler的博客有更丰富的GBTM的实现,包括基于R的crimCV和flexmix ,也有基于Pytorch的实现
crimCV适用于计数型数据(基于零膨胀泊松模型),对于连续型非零数据可考虑flexmix包
2.3 GMM相关资料
混合增长模型可以看作是潜增长模型(latent growth model)和潜分类模型(latent class model)的组合
具体的公式及其演变表示可参阅论文-潜变量增长混合模型在学龄儿童体质指数变化轨迹分析中的应用
更多潜变量模型的汇总可参阅:知乎-统计学中/高级笔记:潜变量模型大章【暂时暂停】 - 知乎 (zhihu.com)
使用Mplus软件实现GMM的过程可参阅:Mplus入门到精通进阶第六讲 增长混合模型 - 知乎 (zhihu.com)